
葬CLI如闪电般上线
葬CLI如闪电般上线葬AI开源了两个项目,一个没有前端,一个没有后端。
来自主题: AI资讯
10179 点击 2026-03-26 15:22
 搜索
搜索
葬AI开源了两个项目,一个没有前端,一个没有后端。

而现在,MCP 似乎正在走向消亡。昨天,Perplexity 的联合创始人和 CTO Denis Yarats 在其公司内部表示,他们正在放弃 MCP,转而使用 API 和 CLI。讽刺的是,这似乎是近期 MCP 声量最高的事件,引发了网友们的讨论。
OpenClaw 火爆的盛况至今仍在持续,在国内甚至出现了排队在腾讯总部楼下等待安装 OpenClaw 的场景,让人感叹「一代人有一代人的领鸡蛋」。
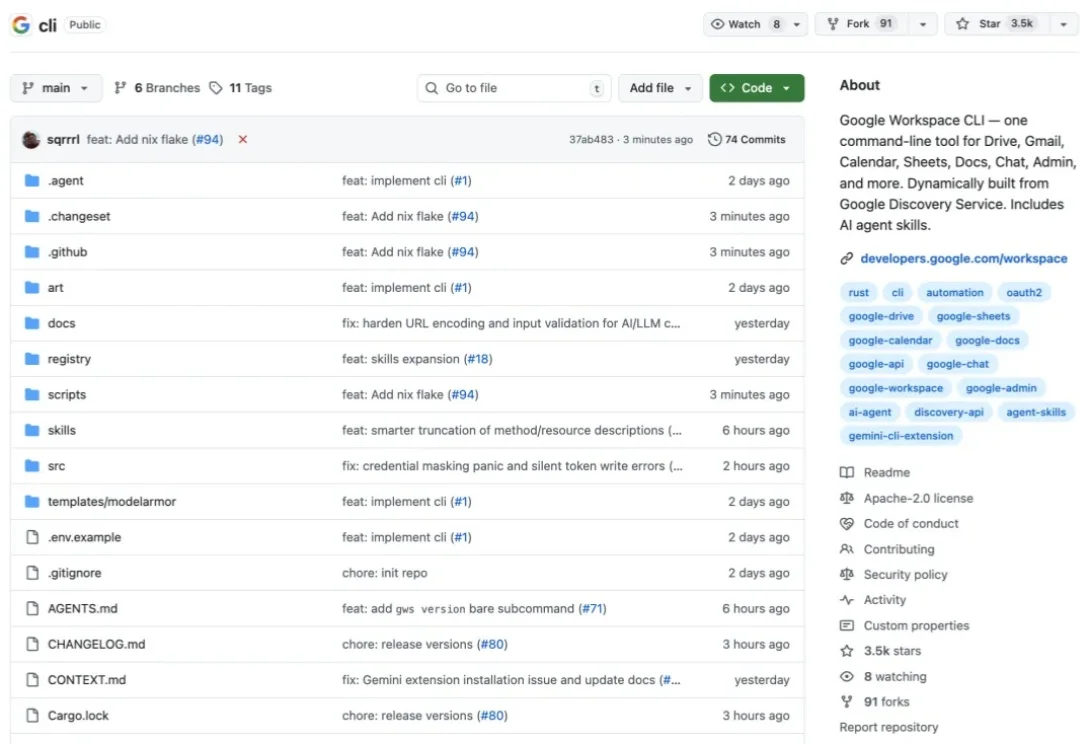
今天上午的时候,Google Workspace CLI 上线到了 GitHub,挂在 Google Workspace 的官方组织名下。我开始写这篇文章的时候,这个项目是 2700 个 Star;当我发出去的时候,重新截了个图,已经有 3500 个 Star 了

刚刚,阿里云Coding Plan订阅服务全面上线Qwen3.5、GLM-5、MiniMax M2.5、Kimi K2.5四大顶尖开源模型。用户订阅套餐后,可在Qwen Code、Claude Code、Cline、OpenClaw等AI工具上自由切换使用这些模型,享受更稳定、Tokens额度更高的模型服务。

在2026当下的智能体(Agent)开发体系中,“为LLM加Skills”已经成为事实上的行业标准。您的Agent表现不好,是因为底层的LLM参数量不够,还是因为您喂给它的“Skills”写得一塌糊涂?无论是日常使用的各类CLI工具,还是最近的Openclaw,其底层能力的跃升很大程度上都依赖于这些特定领域的Agent Skills。
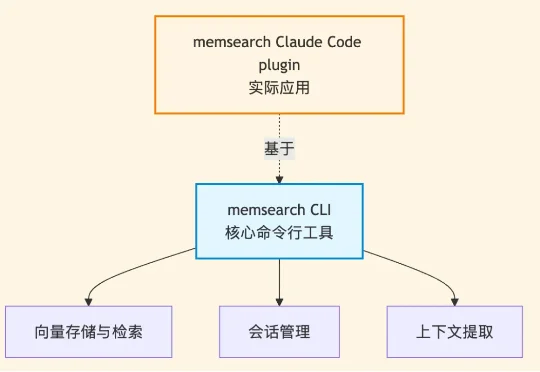
但考虑到在代码领域,如何做好记忆与检索,相比其他场景又有所不同,因此,基于 memsearch CLI ,我们同时也为Claude Code 做了个永久记忆的 plugin——memsearch ccplugin(可适用所有AI coding软件)。

从俄罗斯最大搜索引擎中分拆,4年拿下70亿融资。
实时分析、数据仓库、可观测性以及AI/ML领域的领军企业ClickHouse宣布完成D轮融资,募集资金4亿美元。

Clawdbot火爆全球,国产算力却不能用?AI Agent迎来高光时刻:Ollama只支持CUDA,中国团队直接把国产版开源了!正面硬刚Ollama,5分钟让国产芯片跑通OpenClaw!