
独家:逐际动力前COO张力加入具身智能大脑初创企业BeingBeyond|甲子光年
独家:逐际动力前COO张力加入具身智能大脑初创企业BeingBeyond|甲子光年如果要让机器人更有价值,“大脑”层面的突破是关键。
来自主题: AI资讯
7866 点击 2026-05-13 10:27
 搜索
搜索
如果要让机器人更有价值,“大脑”层面的突破是关键。

4 月 14 日,智在无界发布第三代旗舰模型 Being-H0.7,该模型将数据规模扩展至 20 万小时人类视频,并提出一种全新的范式 —— 基于潜空间推理的世界模型。在 6 项国际性权威评测中,H0.7 综合排名全球第一(其中 4 项登顶),同时也是首个覆盖跨本体、跨场景、连续动态、流体、柔性物体、物理规律与上下文推理等七大关键维度的通用世界模型。
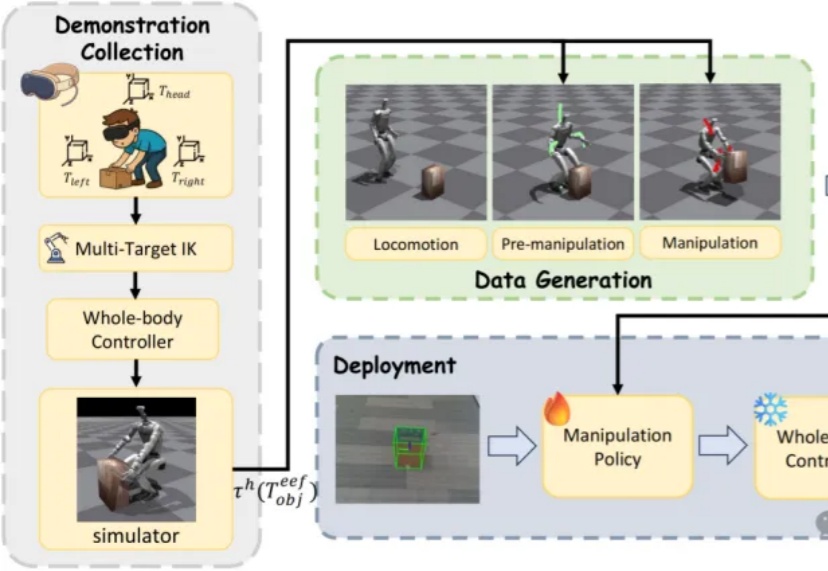
近日,来自北京大学与BeingBeyond的研究团队提出DemoHLM框架,为人形机器人移动操作(loco-manipulation)领域提供一种新思路——仅需1次仿真环境中的人类演示,即可自动生成海量训练数据,实现真实人形机器人在多任务场景下的泛化操作,有效解决了传统方法依赖硬编码、真实数据成本高、跨场景泛化差的核心痛点。
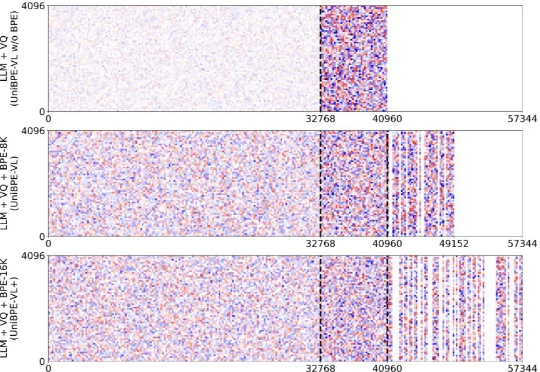
为此,北大、UC San Diego 和 BeingBeyond 联合提出一种新的方法——Being-VL 的视觉 BPE 路线。Being-VL 的出发点是把这一步后置:先在纯自监督、无 language condition 的设定下,把图像离散化并「分词」,再与文本在同一词表、同一序列中由同一 Transformer 统一建模,从源头缩短跨模态链路并保留视觉结构先验。
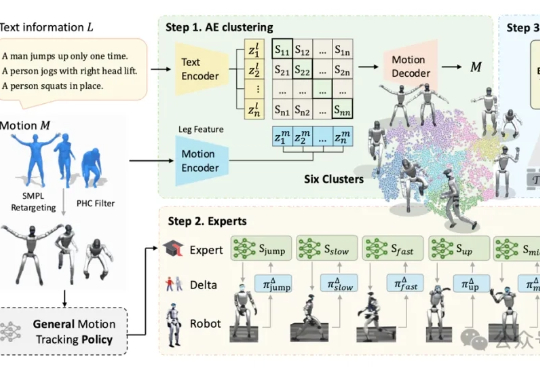
人形机器人对跳舞这件事,如今是越来越擅长了。北京大学与BeingBeyond团队联合研发的BumbleBee系统给出了最新答案:通过创新的“分治-精炼-融合”三级架构,该系统首次实现人形机器人在多样化动作中的稳定控制。