
「整数智能」,AI大模型重构数据标注生产效率
「整数智能」,AI大模型重构数据标注生产效率整数智能发展于浙江大学计算机创新技术研究院,致力于为人工智能企业及科研院所提供一站式数据管理服务。其提供的智能数据工程平台(ABAVA Platform)与数据集构建服务(ACE Service),能够满足自动驾驶、AIGC、智慧医疗等数十个应用场景的数据需求。
来自主题: AI资讯
6734 点击 2024-04-16 11:12
 搜索
搜索
整数智能发展于浙江大学计算机创新技术研究院,致力于为人工智能企业及科研院所提供一站式数据管理服务。其提供的智能数据工程平台(ABAVA Platform)与数据集构建服务(ACE Service),能够满足自动驾驶、AIGC、智慧医疗等数十个应用场景的数据需求。

GPT-4V 的推出引爆了多模态大模型的研究。GPT-4V 在包括多模态问答、推理、交互在内的多个领域都展现了出色的能力,成为如今最领先的多模态大模型。
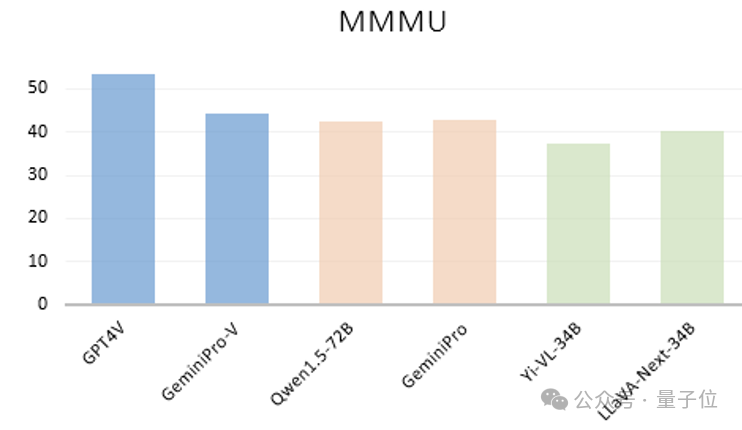
大模型不看图,竟也能正确回答视觉问题?!中科大、香港中文大学、上海AI Lab的研究团队团队意外发现了这一离奇现象。他们首先看到像GPT-4V、GeminiPro、Qwen1.5-72B、Yi-VL-34B以及LLaVA-Next-34B等大模型,不管是闭源还是开源,语言模型还是多模态,竟然只根据在多模态基准MMMU测试中的问题和选项文本,就能获得不错的成绩。

法国产、AI加持。2024 年 4 月 1 日,一款名为 Ava 的 AI Dating 产品登上美国免费下载榜总榜 Top1。最厉害的是 Ava 整个团队不超过 5 个人,甚至是在一周前才开始招聘第一位产品经理、第一位产品设计师。

阿里云最近入职的这位新员工,程序员们看了拍手叫好!每天,它都有数百万行代码被采用,单日推理次数超两千万。007敲代码,兢兢业业改bug,从不抱怨。它不抢程序员饭碗,主打辅助!

2023 年我们正见证着多模态大模型的跨越式发展,多模态大语言模型(MLLM)已经在文本、代码、图像、视频等多模态内容处理方面表现出了空前的能力,成为技术新浪潮。以 Llama 2,Mixtral 为代表的大语言模型(LLM),以 GPT-4、Gemini、LLaVA 为代表的多模态大语言模型跨越式发展。

单图 3D 说话人视频合成 (One-shot 3D Talking Face Generation) 可以被视作解决这一难题的下一代虚拟人技术。它旨在从单张图片中重建出目标人的三维化身 (3D Avatar)

混合专家(MoE)架构已支持多模态大模型,开发者终于不用卷参数量了!北大联合中山大学、腾讯等机构推出的新模型MoE-LLaVA,登上了GitHub热榜。

最近,来自Meta和UC伯克利的研究人员,发布了一种最新的音频到人像模型。操作简单,输出极致逼真。

对于大型视觉语言模型(LVLM)而言,扩展模型可以有效提高模型性能。然而,扩大参数规模会显著增加训练和推理成本,因为计算中每个 token 都会激活所有模型参数。