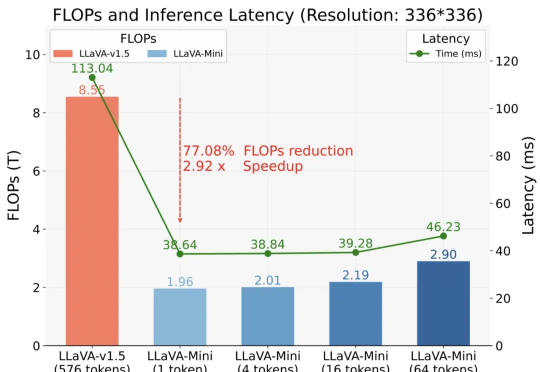
LLaVA-Mini来了!每张图像所需视觉token压缩至1个,兼顾效率内存
LLaVA-Mini来了!每张图像所需视觉token压缩至1个,兼顾效率内存以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。
来自主题: AI技术研报
5092 点击 2025-02-06 15:26
 搜索
搜索
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。

你是否想过在自己的设备上运行自己的大型语言模型(LLMs)或视觉语言模型(VLMs)?你可能有过这样的想法,但是一想到要从头开始设置、管理环境、下载正确的模型权重,以及你的设备是否能处理这些模型的不确定性,你可能就犹豫了。
OpenAI 放出了 o1 Pro、GPT-4o 高级语音、GPTCanavas,就跟孔雀开屏一样 ~ 谷歌最近的大动作是发布了 Gemini 2.0 嘛!2.0 比 1.5 版本快一倍,而且是原生的多模态大模型,能输入和生成语言、声音、图片、视频等。

以 GPT4V 为代表的多模态大模型(LMMs)在大语言模型(LLMs)上增加如同视觉的多感官技能,以实现更强的通用智能。虽然 LMMs 让人类更加接近创造智慧,但迄今为止,我们并不能理解自然与人工的多模态智能是如何产生的。

随着AI技术的不断突破,虚拟数字人和AI养成类游戏正成为数字创作领域的新风向标。从HeyGen、商汤SenseAvatar到腾讯智影,用户上传视频即可轻松生成高拟真度的数字人,标志着个性化内容生产进入了技术主导创作的新篇章。
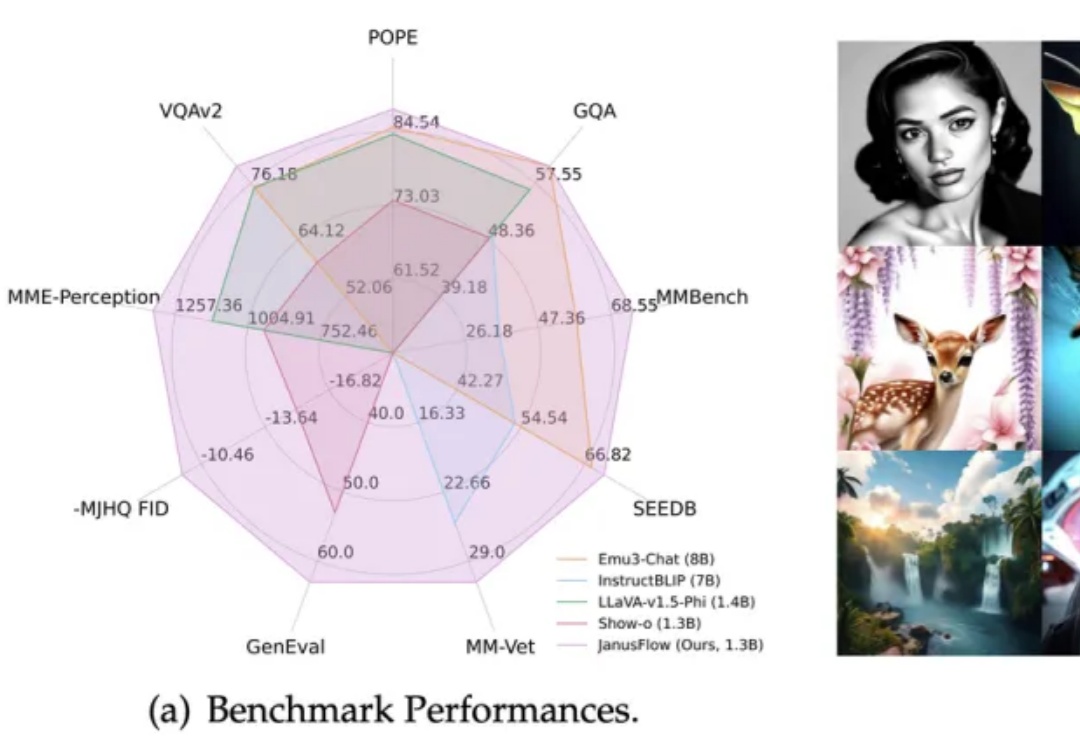
在多模态AI领域,基于预训练视觉编码器与MLLM的方法(如LLaVA系列)在视觉理解任务上展现出卓越性能。
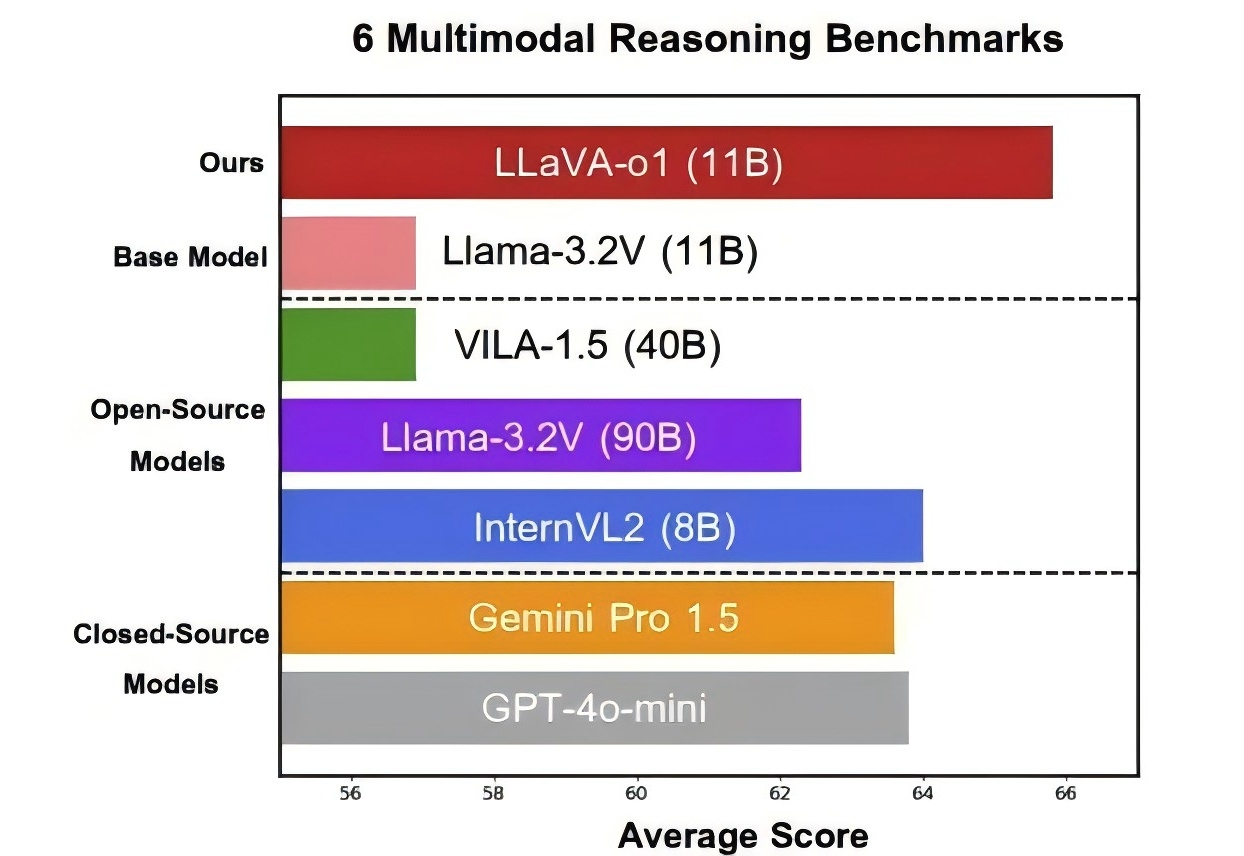
北大等出品,首个多模态版o1开源模型来了—— 代号LLaVA-o1,基于Llama-3.2-Vision模型打造,超越传统思维链提示,实现自主“慢思考”推理。 在多模态推理基准测试中,LLaVA-o1超越其基础模型8.9%,并在性能上超越了一众开闭源模型。

在人工智能领域,大型预训练模型(如 GPT 和 LLaVA)的 “幻觉” 现象常被视为一个难以克服的挑战,尤其是在执行精确任务如图像分割时。

专注金融领域的AI Agent平台Interface.ai宣布完成3000万美元首次融资,由Avataar Venture Partners领投。

Agent-to-Sim (ATS) 是一个创新的三维模拟系统,能够从日常视频集合中学习三维代理的交互行为模型,由 Meta Codec Avatar 实验室主导研发。