
无问芯穹提出混合稀疏注意力方案MoA,加速长文本生成,实现最高8倍吞吐率提升
无问芯穹提出混合稀疏注意力方案MoA,加速长文本生成,实现最高8倍吞吐率提升随着大语言模型在长文本场景下的需求不断涌现,其核心的注意力机制(Attention Mechanism)也获得了非常多的关注。
来自主题: AI技术研报
5395 点击 2024-11-08 19:19
 搜索
搜索
随着大语言模型在长文本场景下的需求不断涌现,其核心的注意力机制(Attention Mechanism)也获得了非常多的关注。

TL;DR:DuoAttention 通过将大语言模型的注意力头分为检索头(Retrieval Heads,需要完整 KV 缓存)和流式头(Streaming Heads,只需固定量 KV 缓存),大幅提升了长上下文推理的效率,显著减少内存消耗、同时提高解码(Decoding)和预填充(Pre-filling)速度,同时在长短上下文任务中保持了准确率。

7 年前,谷歌在论文《Attention is All You Need》中提出了 Transformer。就在 Transformer 提出的第二年,谷歌又发布了 Universal Transformer(UT)。它的核心特征是通过跨层共享参数来实现深度循环,从而重新引入了 RNN 具有的循环表达能力。

又快又准,即插即用!清华8比特量化Attention,两倍加速于FlashAttention2,各端到端任务均不掉点!

通往AGI的路径只有一条吗?实则不然。这家国产AI黑马认为,「群体智能」或许是一种最佳的尝试。他们正打破惯性思维,打造出最强AI大脑,要让世界每一台设备都有自己的智能。
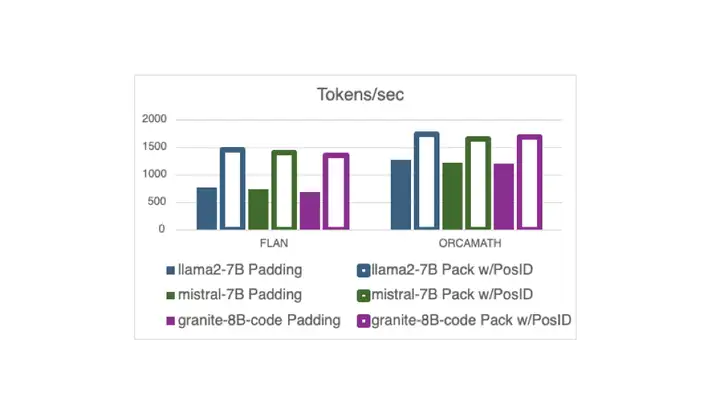
现在,在 Hugging Face 中,使用打包的指令调整示例 (无需填充) 进行训练已与 Flash Attention 2 兼容,这要归功于一个 最近的 PR 以及新的 DataCollatorWithFlattening。 它可以在保持收敛质量的同时,将训练吞吐量提高多达 2 倍。继续阅读以了解详细信息!
Attention is all you need.

今年 3 月份,英伟达 CEO 黄仁勋举办了一个非常特别的活动。他邀请开创性论文《Attention Is All You Need》的作者们齐聚 GTC,畅谈生成式 AI 的未来发展方向。

2017 年,谷歌在论文《Attention is all you need》中提出了 Transformer,成为了深度学习领域的重大突破。该论文的引用数已经将近 13 万,后来的 GPT 家族所有模型也都是基于 Transformer 架构,可见其影响之广。 作为一种神经网络架构,Transformer 在从文本到视觉的多样任务中广受欢迎,尤其是在当前火热的 AI 聊天机器人领域。

用 FlexAttention 尝试一种新的注意力模式。