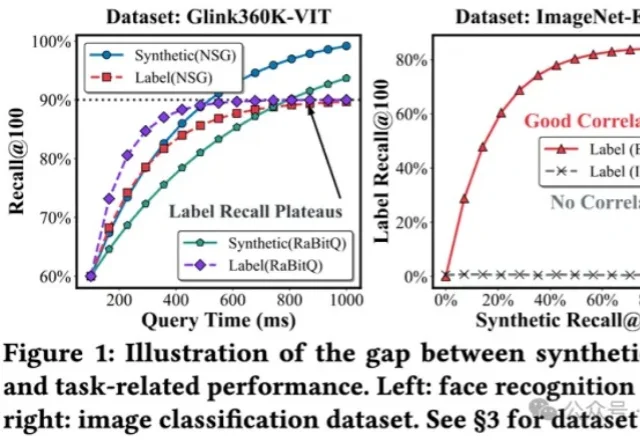
向量检索爆雷!傅聪联合浙大发布IceBerg Benchmark:HNSW并非最优,评估体系存在严重偏差
向量检索爆雷!傅聪联合浙大发布IceBerg Benchmark:HNSW并非最优,评估体系存在严重偏差将多模态数据纳入到RAG,甚至Agent框架,是目前LLM应用领域最火热的主题之一,针对多模态数据最自然的召回方式,便是向量检索。
来自主题: AI技术研报
7655 点击 2025-12-26 09:40
 搜索
搜索
将多模态数据纳入到RAG,甚至Agent框架,是目前LLM应用领域最火热的主题之一,针对多模态数据最自然的召回方式,便是向量检索。

年少有为、雄心勃勃的创业者早已不是新鲜事。Bill Gates 19 岁时联合创办了微软;Mark Zuckerberg 也是在 19 岁那年创立了 Facebook。但如今的创业者,年龄更小了,可能还只是个拿着学车许可证、戴着牙套的孩子。

我们不会和 Meta 竞价,即便待遇远低于对方,核心人才仍愿意留在 OpenAI,只因大家坚信这里的发展潜力和 AGI 愿景。
2025年12月12日,波士顿大学的 Andrey Fradkin 团队发布了一项令业界瞩目的研究 《The Emerging Market for Intelligence: Pricing, Supply, and Demand for LLMs》(智能的新兴市场:LLM的定价、供给与需求)。
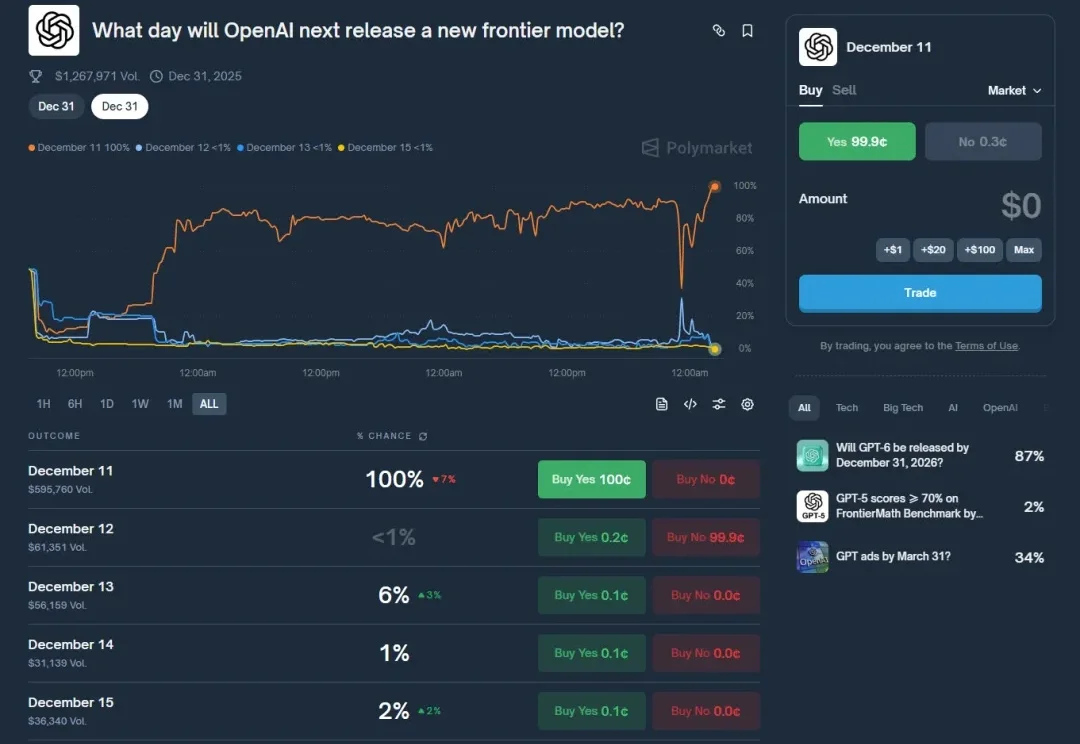
GPT-5.2也发布了有几天了。

刚刚,Linux 基金会正式宣布推出智能体 AI 基金会(Agentic AI Foundation,简称 AAIF)。据公告披露,AAIF 定位为 AI 智能体(AI agents)相关开源项目的中立托管平台,全球几乎所有科技巨头均已签约成为该基金会成员。Anthropic、OpenAI 与 Block 三家公司作为联合创始成员,将贡献三大开源项目,构成基金会启动初期的支柱。

在本周一举行的 Open Source Summit Japan 主题演讲中,Linux 基金会执行董事 Jim Zemlin 抛出了一个耐人寻味的判断: “AI 可能还谈不上全面泡沫化,但大模型或许已经开始泡沫化了。”

救大命,OpenAI首席研究官Mark Chen最新访谈,信息量有点大呀。

5000亿美元,是NASA预估能让人类完成火星登陆的预算、能买下1.36个阿里(3670亿美元)、3.5个NBA联盟(1400亿美元)、建设100座Apple Park(50亿美元)、买1400亿杯咖啡(3.5美元),却只够OpenAI建一座Stargate数据中心。

基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。