
6位前DeepMind老将打造「AI指挥官」,一半成本刷新SOTA
6位前DeepMind老将打造「AI指挥官」,一半成本刷新SOTA6位前DeepMind成员以元系统重塑大模型调用方式,该系统推出的Gemini 3 Pro优化技术在ARC-AGI-2上以54%的成绩夺得榜首,而成本仅为此前最优方法的一半。
来自主题: AI技术研报
8935 点击 2025-12-15 11:31
 搜索
搜索
6位前DeepMind成员以元系统重塑大模型调用方式,该系统推出的Gemini 3 Pro优化技术在ARC-AGI-2上以54%的成绩夺得榜首,而成本仅为此前最优方法的一半。
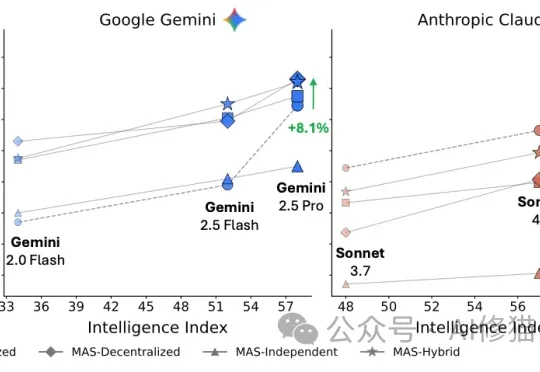
最近,来自Google Research、Google DeepMind和MIT的研究者们联合发表了一项重磅研究。结果显示:盲目增加智能体数量,在很多时候不仅没用,反而会让系统变笨、变慢、变贵。

昨夜,OpenAI用专家级GPT-5.2复仇Gemini 3成功!而在GPT-5.2发布前一个多小时,谷歌就率先推出全新版Gemini Deep Research Agent。谷歌对Gemini深度研究进行了重新构想,使其比以往任何时候都更加强大。

今日凌晨,比OpenAI早一个小时,谷歌甩出了3个Agent大招:Deep Research Agent功能更新,并首次向开发者开放;开源新网络研究Agent基准DeepSearchQA,旨在测试Agent在网络研究任务中的全面性;推出新交互API(Interactions API)。
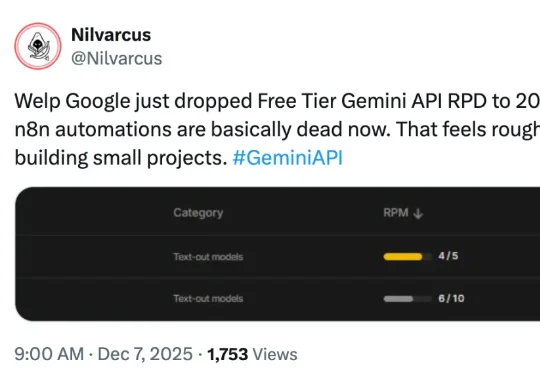
“谷歌刚把免费版 Gemini API 的每日请求次数从 250 降到了 20,我的 n8n 自动化脚本现在基本都用不了了。这对任何开发小型项目的人来说都是个打击。”网友 Nilvarcus 表示。近日,有网友曝出 Google 收紧了 Gemini API 免费层级的限制:Pro 系列已经取消,Flash 系列每天仅 20 次。这对开发者来说远远不够用。
几乎每一次普适性的技术革命都会带来内容生态的变化,AI 也不例外。

最近,Google Research 发布了一篇 Blog《Titans + MIRAS:帮助人工智能拥有长期记忆》。它们允许 AI 模型在运行过程中更新其核心内存,从而更快地工作并处理海量上下文。

近日,第三方评测机构 SuperCLUE 发布 11 月 DeepSearch 评测报告,国产大模型 openPangu-R-72B 凭借在长链推理、复杂信息检索领域的卓越表现,在模型榜单中名列第一,体现了基于国产昇腾算力的大模型研发实力。
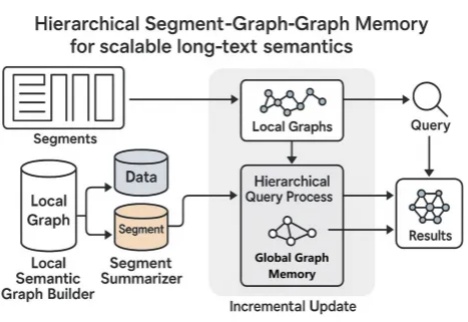
当你阅读《红楼梦》《哈利·波特》《百年孤独》等长篇小说时,读着读着可能就忘记前面讲了什么,有时还会搞混人物关系。AI 在阅读长文章的时候也存在类似问题,当文章太长时它也会卡主,要么读得特别慢,要么记不住前面的内容。

一家成功的科技公司,其灵感往往源于最切身的痛点。对于 Archy 的创始人 Jonathan Rat 而言,这个痛点来自他的夫人。