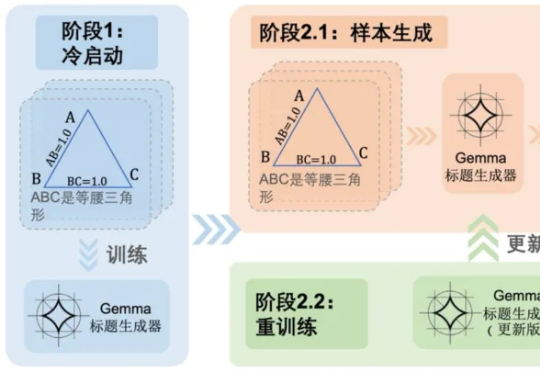
给几何图片写标题就能让AI更聪明,UIUC发布高质量可泛化几何数据集
给几何图片写标题就能让AI更聪明,UIUC发布高质量可泛化几何数据集随着多模态大语言模型(MLLMs)在视觉问答、图像描述等任务中的广泛应用,其推理能力尤其是数学几何问题的解决能力,逐渐成为研究热点。 然而,现有方法大多依赖模板生成图像 - 文本对,泛化能力有限,且视
来自主题: AI技术研报
8054 点击 2025-09-26 13:30
 搜索
搜索
随着多模态大语言模型(MLLMs)在视觉问答、图像描述等任务中的广泛应用,其推理能力尤其是数学几何问题的解决能力,逐渐成为研究热点。 然而,现有方法大多依赖模板生成图像 - 文本对,泛化能力有限,且视
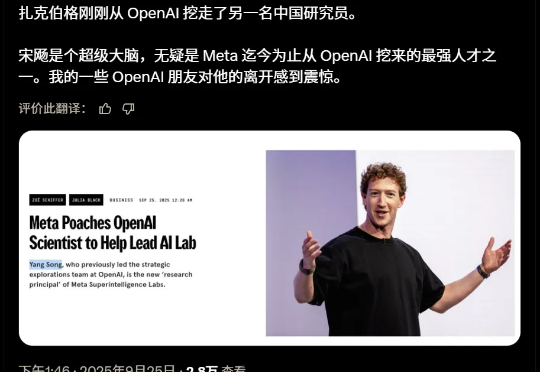
刚刚,Meta又从OpenAI挖来一员猛将——宋飏,扩散模型领域的核心人物,DALL·E 2技术路径的早期奠基者。他已正式加入Meta Superintelligence Labs,担任研究负责人,直接向他的师兄赵晟佳汇报。
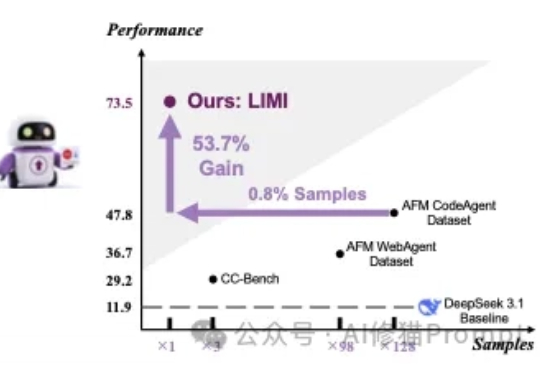
对于提升AI能主动发现问题、提出假设、调用工具并执行解决方案,在真实环境里闭环工作,而不只是在对话里“想”的智能体能力(Agency)。在这篇论文之前的传统方法认为,需要遵循传统语言模型的“规模法则”(Scaling Laws)才能实现,即投入更多的数据就能获得更好的性能。

该公司周二宣布完成530 万美元种子轮融资,本轮由 Outlander VC 和 Field Ventures 共同领投。埃默里透露,部分投资人源自他上一个创业项目,这些早期投资者又为他引荐了本轮领投机构。其他参投方包括 Hootsuite 创始人联合创立的 LOI Venture、Zenda Capital、8-Bit Capital 以及 Behind Genius Ventures。

今天继续给大家带来「一页纸」讲透美股公司系列。对国内投资者而言,美股研究资料相对匮乏,导致认知大多停留在几家全球科技巨头,但其实美股存在大量的“隐形冠军”,都录得相当不错的收益。这是一个非常「有钱景」的方向,我会借助 AlphaEngine 的帮助,帮你跨越美股研究的信息鸿沟,每天挖掘一个潜在的美股财富密码。
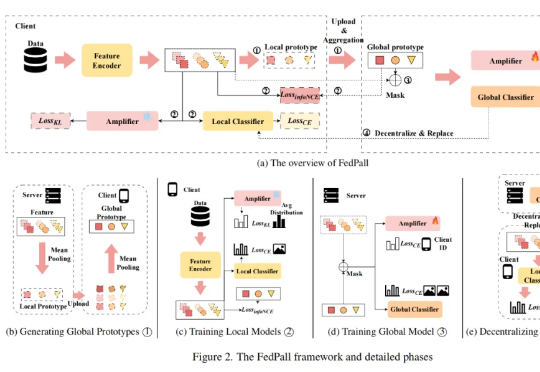
本论文第一作者张勇为北京理工大学医学技术学院计算机技术专业硕士生,主要研究方向为联邦学习,多专家大模型,多任务学习和并行代理。通讯作者是深圳北理莫斯科大学人工智能研究院梁锋博士和胡希平教授。梁锋博士毕
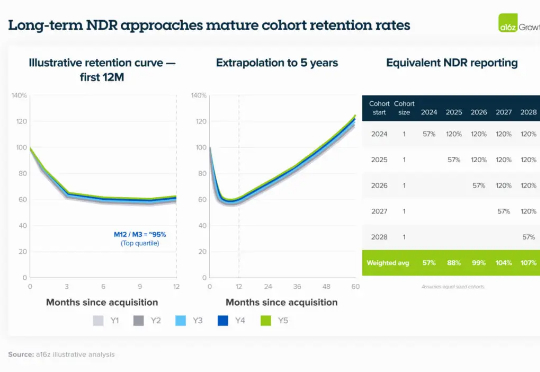
近期,a16z 的研究团队发布了一篇博客文章《Retention Is All You Need》,在分析了数百家 AI 企业的情况后发现:将衡量用户留存率的基准点从第 0 个月(M0)后移至第 3 个月(M3),反而能更清晰地评估 PMF 和 GTM 策略。

昨天,甲骨文突然宣布换帅!本月初刚去白宫参加闭门晚宴的CEO Safra Catz卸任,接任者是甲骨文云基础设施总裁Clay Magouyrk和甲骨文行业总裁Mike Sicilia。埃里森下定了决心,All in AI。

Distyl AI。这家成立三年的初创公司为 T-Mobile 等企业提供所谓的"前置部署工程师"和 AI 软件,可自动化处理客户数据分析或人力资源管理等业务流程。据首席执行官 Arjun Prakash 透露,这家由数据分析软件制造商 Palantir 前员工创立的企业,在合同量激增后已完成 1.75 亿美元融资,投后估值达 18 亿美元。

谷歌云刚发布了一篇《Google Cloud Startup technical guide: Al agents》(Google Cloud 创业公司技术指南:AI 代理)这是一份非常详尽和全面的手册,这篇文档要解决的问题:原型到生产之间最大鸿沟,Agent的非确定性、复杂推理轨迹如何验证、如何部署与运维等。初创公司业务负责人或开发者看完后能获得一个系统性的、