
不到 3 个月估值破 40 亿,Fal.ai CEO:模型越多,我们越值钱
不到 3 个月估值破 40 亿,Fal.ai CEO:模型越多,我们越值钱2025 年 10 月 22 日,AI 基础设施公司 Fal.ai宣布完成新一轮 2.5 亿美元融资。据悉,凯鹏华盈与红杉资本领投此轮,公司估值超40亿美元。
来自主题: AI资讯
8717 点击 2025-10-27 11:02
 搜索
搜索
2025 年 10 月 22 日,AI 基础设施公司 Fal.ai宣布完成新一轮 2.5 亿美元融资。据悉,凯鹏华盈与红杉资本领投此轮,公司估值超40亿美元。
HuggingFace 与牛津大学的研究者们为想要进入现代机器人学习领域的新人们提供了了一份极其全面易懂的技术教程。这份教程将带领读者探索现代机器人学习的全景,从强化学习和模仿学习的基础原理出发,逐步走向能够在多种任务甚至不同机器人形态下运行的通用型、语言条件模型。
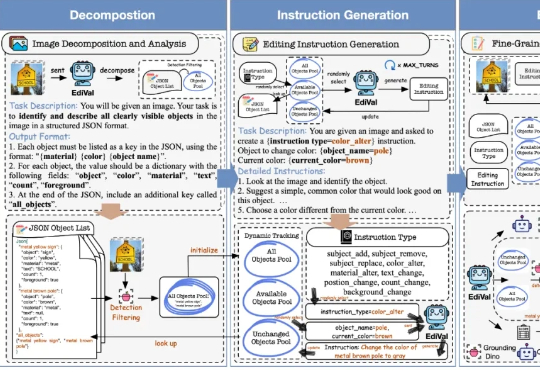
在 AIGC 的下一个阶段,图像编辑(Image Editing)正逐渐取代一次性生成,成为检验多模态模型理解、生成与推理能力的关键场景。我们该如何科学、公正地评测这些图像编辑模型?
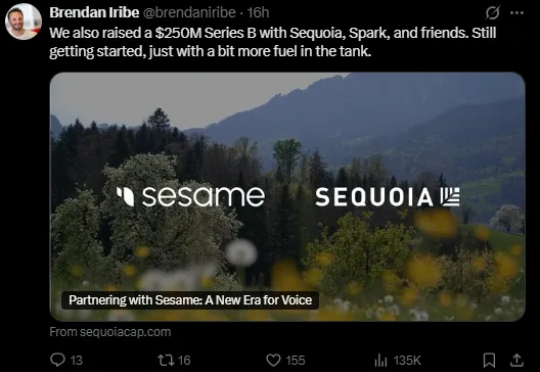
TechCrunch 报道,之前一直以 AI 语音初创公司示人的 Sesame,完成了 2.5 亿美元的 B 轮融资,投资方包括红杉资本、Spark Capital 及其他未公开的投资者。随后,Sesame 创始人 Brendan Iribe 也在个人社媒账号上发帖,证实该消息。
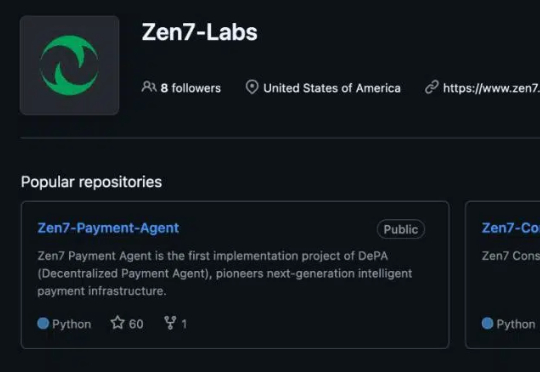
近日,Zen7 Labs正式提出DePA(Decentralized Payment Agent,去中心化支付智能体)概念,并率先在GitHub 上开源其核心产品Zen7 Payment Agent。Zen7 Labs 是一家专注于智能计算与 Agent 技术创新的国际化团队
很疯狂,Meta AI裁员能裁到田渊栋头上,而且是整组整组的裁。田渊栋在Meta工作已超过十年,现任FAIR研究科学家总监(Research Scientist Director),他领导开发了早于AlphaGo的围棋AI“Dark Forest”

近日,范鹤鹤(浙江大学)、杨易(浙江大学)、Mohan Kankanhalli(新加坡国立大学)和吴飞(浙江大学)四位老师提出了一种具有划时代意义的神经网络基础操作——Translution。 该研究认为,神经网络对某种类型数据建模的本质是:

刚刚,这个开源的VLA一站式平台,不仅让UR5e真机实现了100%成功率,还在五大仿真环境中全面领先,最高性能提升高达46%,而且还支持RTX 4090训练!最近,由Dexmal 原力灵机重磅开源的Dexbotic,则构建了一个「VLA统一平台」。Dexbotic作为具身智能VLA模型一站式科研服务平台,可以为VLA科研提供基础设施,加速研究效率。
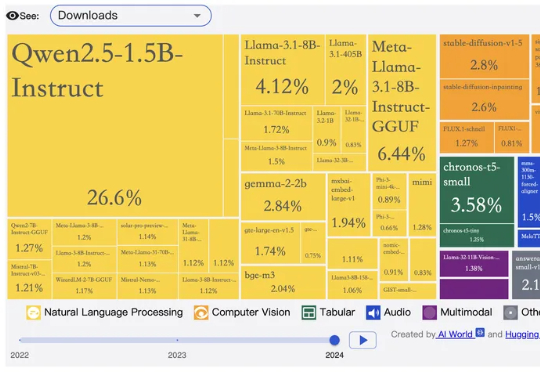
美国 AI 圈开始出现“担心中国开源断供”的苗头了吗?10 月 20 日,在专注于开源模型讨论、拥有 55 万成员的 Reddit 分论坛“r/LocalLLaMA”上,一位网友发布了一则“当中国公司停止提供开源模型时会发生什么?”的提问,并表达了假如中国模型逐渐闭源或开始收费该怎么办的担忧。
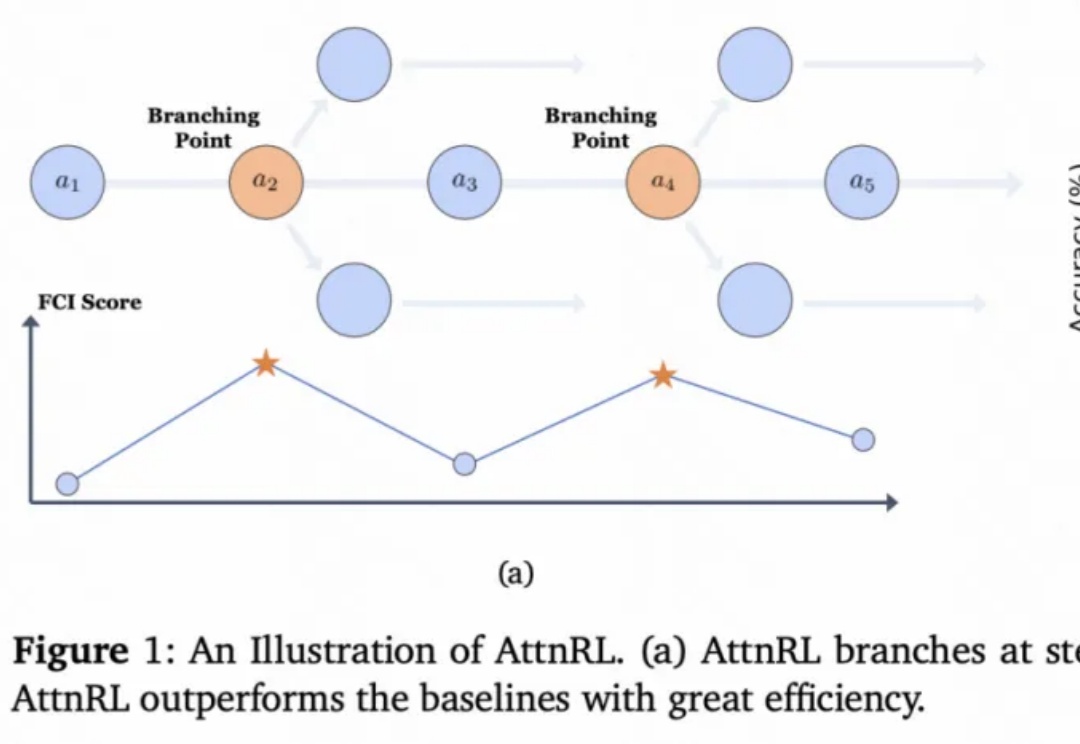
从 AlphaGo 战胜人类棋手,到 GPT 系列展现出惊人的推理与语言能力,强化学习(Reinforcement Learning, RL)一直是让机器「学会思考」的关键驱动力。