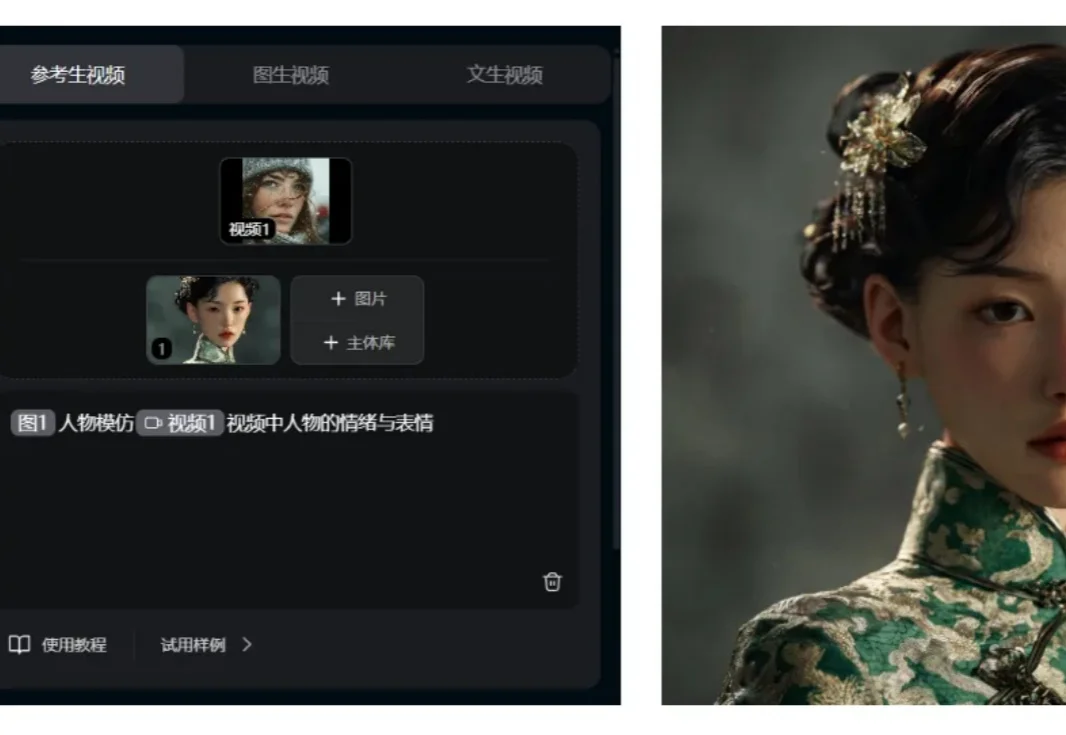
爆款视频可以抄作业了!特效表情质感都能复刻,万物可参考AI视频模型 Vidu Q2参考生Pro 来了
爆款视频可以抄作业了!特效表情质感都能复刻,万物可参考AI视频模型 Vidu Q2参考生Pro 来了现在的视频创作环境太卷了。去年我们还在感叹AI视频能动了,现在大家的要求直接拔高到了不仅要能动,还要动得高级、动得精准。
来自主题: AI资讯
8412 点击 2026-01-28 11:01
 搜索
搜索
现在的视频创作环境太卷了。去年我们还在感叹AI视频能动了,现在大家的要求直接拔高到了不仅要能动,还要动得高级、动得精准。
你的下一个视频团队,不一定非得是人。

Sora画下的饼终于被做熟了!用DeepSeek式的慢思考逻辑,把AI视频从「看运气抽卡」变成了「确定性交付」,这才是电商人真正需要的工业革命。
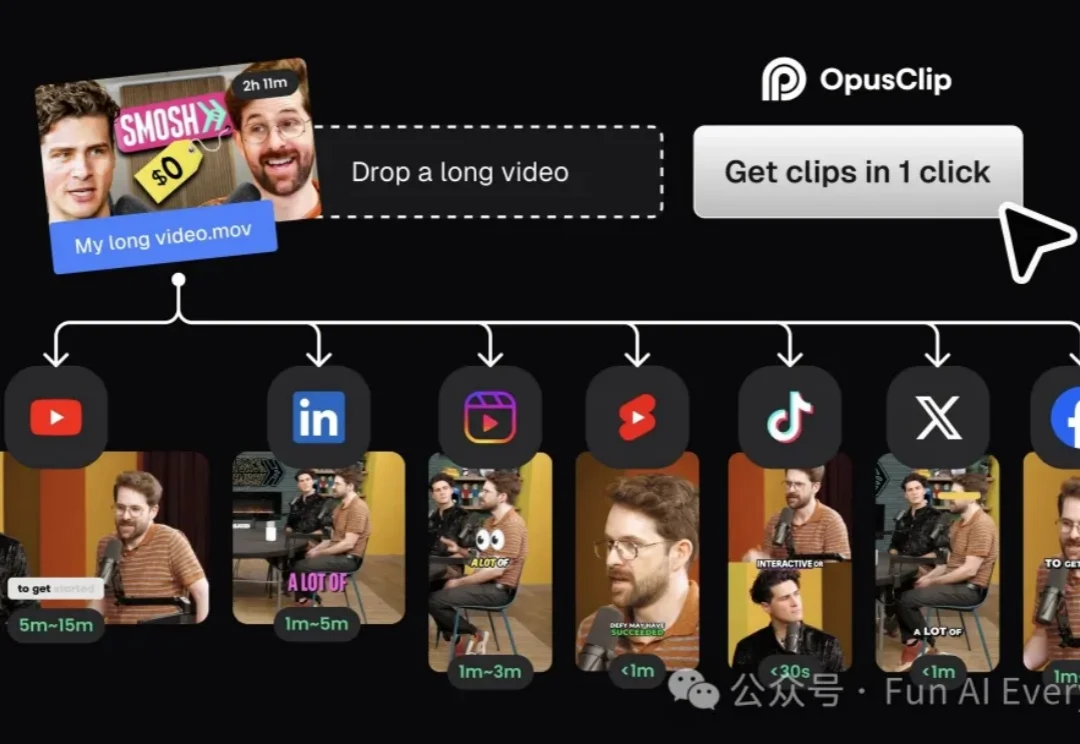
OpusClip 是一款把长视频、长内容自动剪成可发布的短视频片段的 AI 工具,服务内容创作者和企业内容团队。
《晚点 LatePost》独家获悉,快手旗下视频生成大模型可灵 AI 的月活跃用户(MAU)在今年 1 月突破 1200 万。

过去一年,AI圈的词语通货膨胀是不是有点太严重了?

不er,这个世界还有什么是真的?反正我是已经分不清了...

测了一堆AI视频生成工具后,骡子马发现了个真东西——Flova。
AI视频生成正从“静态输出”迈入“实时交互”阶段,一场内容创作革命即将到来。 近日,中国儒意宣布以1420万美元对爱诗科技进行战略投资,双方将围绕影视、流媒体、游戏等业务展开深度合作。 爱诗科技作为全

视频世界模型领域又迎来了新的突破!