
AI「上班流」首次完整曝光!不点鼠标,只写代码,PPT也当函数调
AI「上班流」首次完整曝光!不点鼠标,只写代码,PPT也当函数调AI已经不止会写代码、画图、做PPT,它也开始「上班」了!CMU与斯坦福的研究团队首次完整追踪了AI的工作过程,发现一个惊人事实:它并不是在模仿人类,而是在用编程的方式重写工作的定义。这场关于「谁在工作」的实验,正在重构未来职场的逻辑。
来自主题: AI技术研报
8258 点击 2025-10-31 14:47
 搜索
搜索
AI已经不止会写代码、画图、做PPT,它也开始「上班」了!CMU与斯坦福的研究团队首次完整追踪了AI的工作过程,发现一个惊人事实:它并不是在模仿人类,而是在用编程的方式重写工作的定义。这场关于「谁在工作」的实验,正在重构未来职场的逻辑。

在这片喧嚣和迷雾之中,我们迫切需要一个清晰的导航图。而Jason Wei正是提供这份地图的最佳人选之一。他现任Meta超级智能实验室(Meta Super Intelligence Labs)的研究科学家,此前在OpenAI工作了两年,o1研发的主导者,更早之前是Google Brain的科学家。
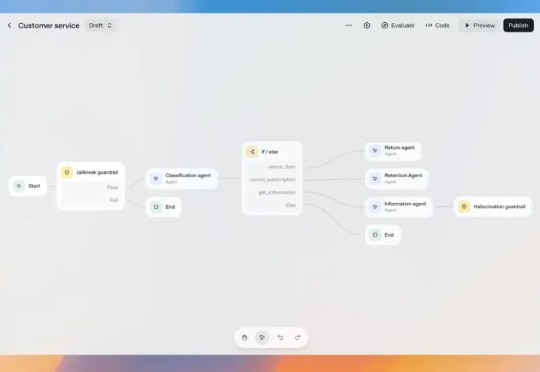
在几天前的开发者大会上,OpenAI 发布了一套面向开发者和企业的完整工具集 AgentKit。其中,可视化画布 Agent Builder 用于创建、管理和版本化多智能体工作流,通过拖拽节点的方式即可编辑工作流。
一个这样的 AI 产品,居然每个月也能搞到几十 K 流量,还在稳步往上走。基本上就是躺着赚的节奏。对那阵子有印象的朋友应该还记得,当时 ComfyUI 很火。但本地部署真不省心,对电脑硬件要求也高,所以很多人干脆租云电脑来用 ComfyUI。

不用在建模、UV、贴图软件之间反复横跳,一个工作台就能得到:这是腾讯专为3D设计师、游戏开发者、建模师等打造的专业级AI工作台混元3D Studio。

2022年10月,Comfyanonymous 偶然接触到 Stable Diffusion 并深深着迷。当时这并非因为什么“让 AI 更易用” 的宏大使命,而是出于对图像生成的纯粹热爱。他最初的尝试,仅仅是想生成一位耳廓狐形象的动画角色的图片。。出于对这个想法的执着,ComfyUI 由此诞生。

Vibe Coding(Claude code、Cursor、Lovable) 把原本8周的开发周期压缩成2天 现在,同样20倍的加速在营销圈上演—— Vibe Marketing: 一个人➕n 个AI Agent和自动化工作流,几小时就能把营销想法落地了,杠杆效应大到离谱。
OpenAI 在 AI 领域引领了一波又一波浪潮,想必很多人好奇,这些创新背后的研究人员是如何通过面试的? 尤其是现在,OpenAI 已经成为全球最受瞩目的 AI 公司之一,吸引了无数顶尖人才投递简历。想要加入这个团队,着实不容易。

研究人员分析了20万条AI对话、整合了近3万项职业任务数据,通过计算覆盖率、成功率和影响范围三个维度,为每个职业算出了AI适用性分数。

最近,Dify 的迭代非常之频繁,继 6 月 25 日发布 1.5.0 版本之后,7 月 2 日又迅速推出了 1.5.1 版本。从 1.4.x 开始,我几乎每个版本发布时都会第一时间尝试升级。社区一如既往地活跃,大家遇到 bug 都会第一时间反馈,官方团队也会及时记录并处理。