
智谱与Anthropic是母凭子贵
智谱与Anthropic是母凭子贵Anthropic增加绿卡认证后,最开心是智谱,直接原地化身战狼,高呼「前沿智能属于所有人」,提前把专注Coding的GLM5.2发了。
来自主题: AI产品测评
8302 点击 2026-06-24 16:36
 搜索
搜索
Anthropic增加绿卡认证后,最开心是智谱,直接原地化身战狼,高呼「前沿智能属于所有人」,提前把专注Coding的GLM5.2发了。

美方官员被曝坦言,美国已流失下一代机器人配套产能。

全球最强超算,易主了!
6 月 11 日凌晨,小米 MiMo 团队公开了一个叫 MiMo Code 的项目,定位是终端编程 Agent,MIT 协议开源。官方宣传重点有三处,14 天 5 人团队投入的“vibe coding”开发叙事、Claude Code 之上的 SWE-Bench Pro 跑分。以及“无限上下文”的记忆架构。

今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。

小米UltraSpeed需求远超预期。

大家好,我是最近疯狂研究短剧的袋鼠帝 最近的AI漫剧发展的是真快啊,各种爽文小说改编的AI漫剧播放量甚至已经超过了某些电影和电视剧。

有这么一组数据,是真真儿地戳到了用Agent这件事的爽点。
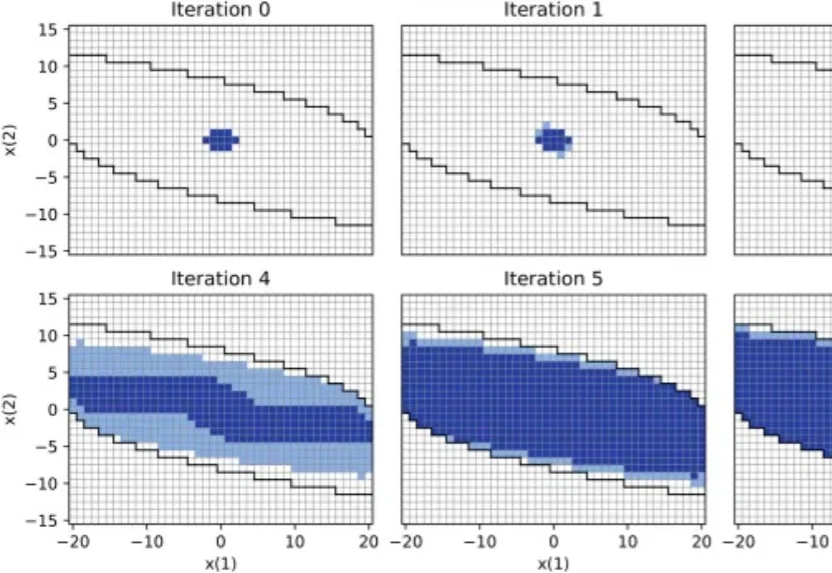
近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。
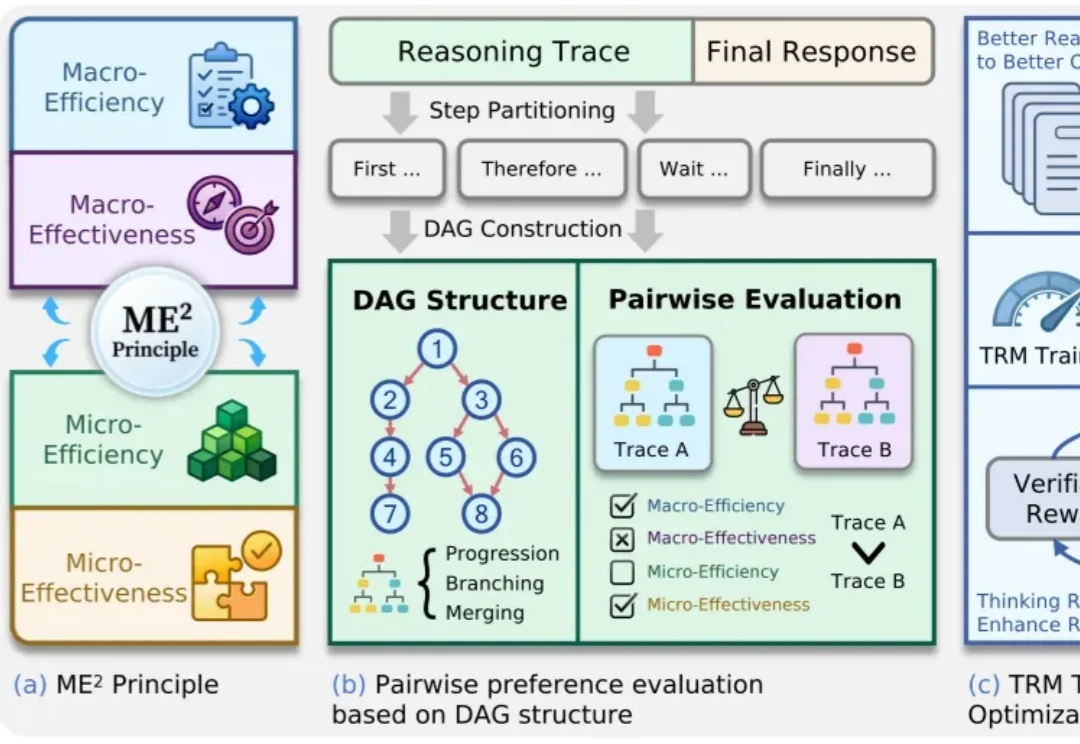
大模型推理能力越来越强,但答案对了,思考过程就一定好吗?