
亿元级A+轮融资背后:未来智能的“硬件新物种”实验,一场关于AI Agent入口的豪赌
亿元级A+轮融资背后:未来智能的“硬件新物种”实验,一场关于AI Agent入口的豪赌AI硬件公司未来智能宣布完成亿元级A+轮融资,参投方是在全球手机市场中素有“非洲之王”称号的传音。据未来智能CEO马啸透露,这轮融资很快就完成了敲定,“我们没有盲目融很多钱,而是按照公司的发展需要去规划。”
来自主题: AI资讯
9422 点击 2026-05-10 10:44
 搜索
搜索
AI硬件公司未来智能宣布完成亿元级A+轮融资,参投方是在全球手机市场中素有“非洲之王”称号的传音。据未来智能CEO马啸透露,这轮融资很快就完成了敲定,“我们没有盲目融很多钱,而是按照公司的发展需要去规划。”

Nacos 作为 Skill Registry AI Agent 进入日常工作流后,能力复用的载体正在发生变化。 过去,我们复用的是脚本、配置、模板和文档;现在,越来越多可复用经验会被沉淀成 Skil
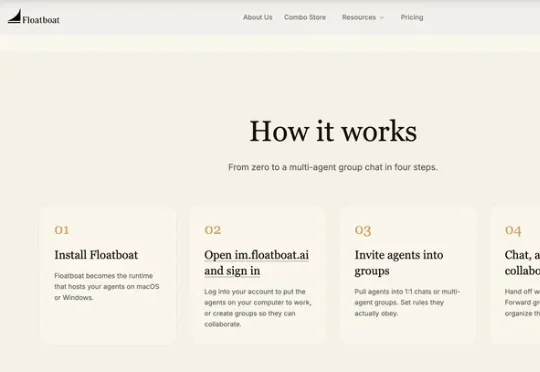
本期项目推荐的6个项目从三层展开:第一层是 对话关系。Agent 要先进入群聊,读到同样的信息。第二层是 组织关系。Agent 进入团队后,要被分配、管理、调度。第三层是 经济关系。Agent 不再只是被使用,能不能自己接单、交付、赚钱。
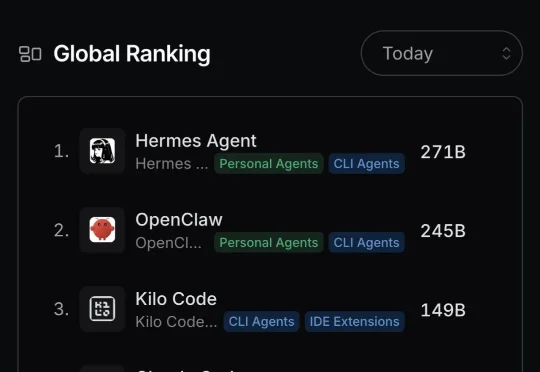
5月9日,Hermes Agent(昵称:爱马仕)登顶OpenRouter全球应用调用量榜首,首次超越OpenClaw(昵称:龙虾)。据OpenRouter应用Token消耗榜最新数据,这一Nous Research旗下开源自进化Agent产品登顶全球应用Token消耗榜,单日Token消耗量达到271B,也就是2710亿Token。
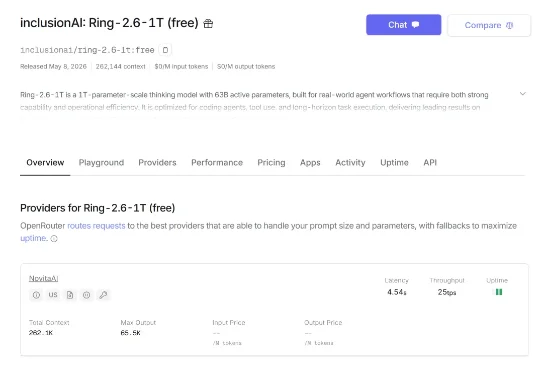
今天,蚂蚁百灵大模型发布Ring-2.6-1T。这是一款面向真实复杂任务场景的万亿级思考模型,目前已上线OpenRouter,并开放限时一周免费体验,后续将正式开源。Ring-2.6-1T加入了可调节的Reasoning Effort机制。开发者可以在high和xhigh两种推理强度之间选择:high面向Agent、Coding、多步工具调用等高频任务
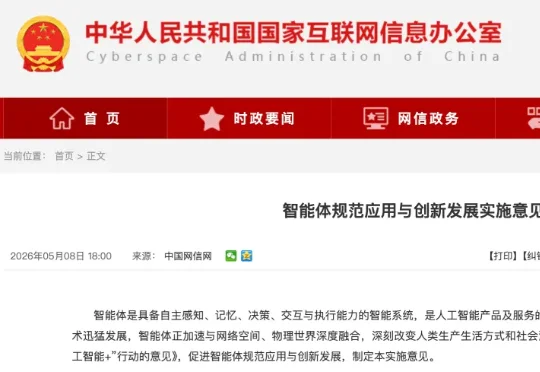
昨日晚间,国家网信办、国家发展改革委、工业和信息化部近日联合印发《智能体规范应用与创新发展实施意见》(简称:《实施意见》)。这是国家三部门首次单独以 “智能体(Agent)” 为核心主题制定的系统性政策,此前没有任何一部国家部委文件专门聚焦智能体的定义、安全、应用、生态进行全面规范。
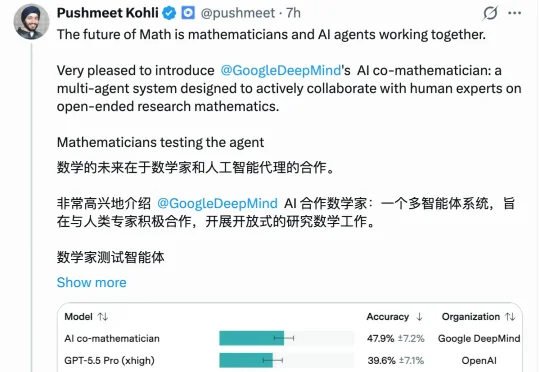
群论领域几十年无解的第21.10号问题,被牛津数学家Marc Lackenby用谷歌一个新系统破解了。过程也很有意思:AI第一次给出的证明是错的,被系统里的审查Agent揪出了漏洞。

今日,像素绽放PixelBloom宣布完成C轮融资。本轮融资由国科投资与商汤国香资本联合领投,基石创投、大米创投跟投。 资金将重点投入AI办公解决方案Agent的研发迭代、商业化落地及全球化人才招募。
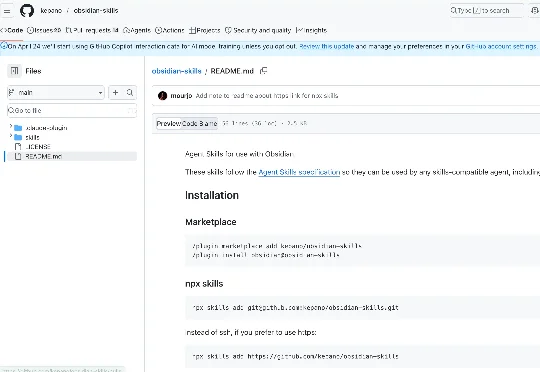
随手打开 GitHub,2026 年的 Agent 项目热榜上有这样一个仓库: • 27,000+ stars,1,800+ forks • 零行 Python,零行 TypeScript,零行 JS • 作者是 Obsidian 的 CEO 本人,kepano • 整个仓库就是 5 个 Markdown 文件
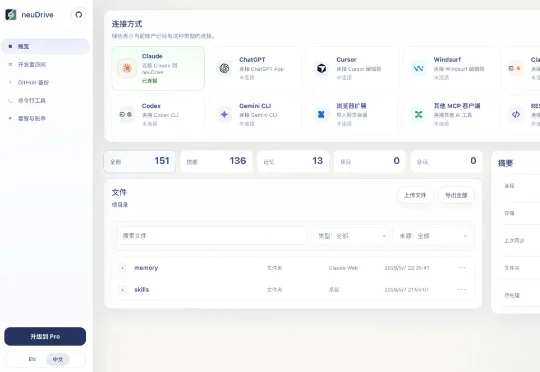
俺做滴 我做了一个给 Agent 用的网盘,叫 neuDrive.ai,开源的 你在 Claude、Codex、Cursor 这些工具里攒下来的 skill、记忆、文件,可以通过 neuDrive 一键备份、相互同步