
谁在 ChatGPT 里买广告?|对谈 Nexad COO Harry Zhou
谁在 ChatGPT 里买广告?|对谈 Nexad COO Harry Zhou今年初,ChatGPT 开始小范围测试卖广告。半年过去,我们很好奇:那些真正把预算投进去的人,看到了什么?
来自主题: AI资讯
7684 点击 2026-06-30 10:46
 搜索
搜索
今年初,ChatGPT 开始小范围测试卖广告。半年过去,我们很好奇:那些真正把预算投进去的人,看到了什么?
Patronus AI 今天官方宣布公司完成由 Greenfield Partners 领投的 5000 万美元 B 轮融资,Lightspeed Venture Partners、Notable Capital、Datadog、三星、Gokul Rajaram、Factorial Capital 以及来自我们实验室和新实验室的众多人工智能领军人物也参与了本轮融资。
没错,我说的就是从6月下半旬开始在Github上爆火的OpenMontage。这是一个专门用来给AI视频生成准备的Harness工具,你把你的提示词给它,它就能自动帮你完善成专业的AI视频生成提示词,并且还配有剪辑、配音等等一系列后期工作。

硅谷著名科技播客主持人 Dwarkesh Patel 最近抛出了一个问题:AI 的下一代训练范式会是什么?
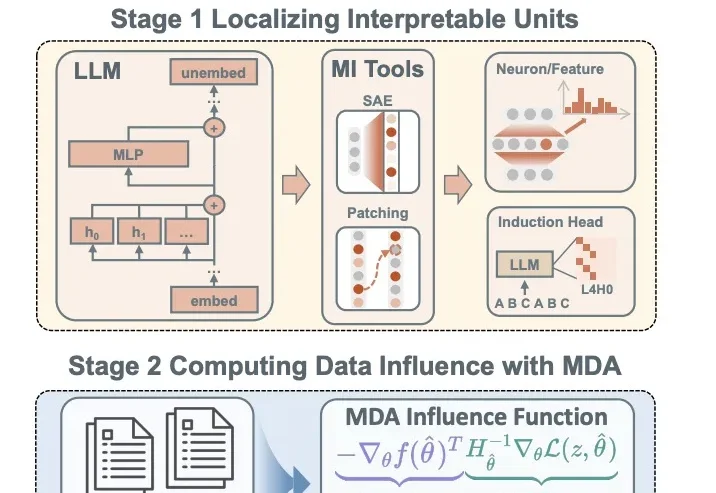
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。
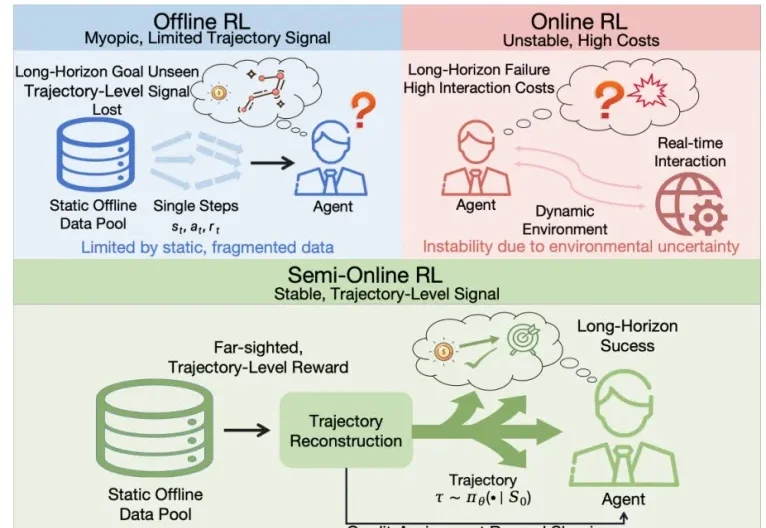
想训练能自动操作手机的GUI(图形用户界面)智能体,总会遇到两难困境:
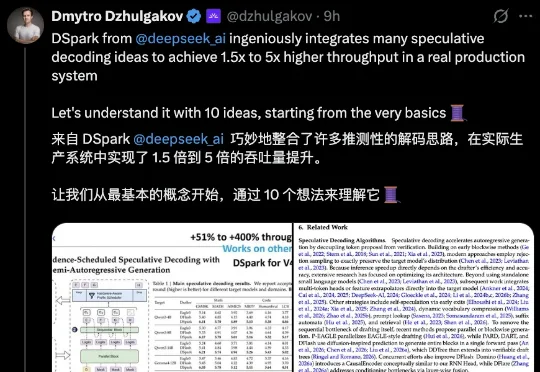
Fireworks AI的联合创始人兼CTO、PyTorch核心维护者Dmytro Dzhulgakov将整篇论文梳理成了10个概念,从最底层的GPU访存特性讲到最上层的在线自适应调度。DeepSeek这套方案真正的精髓在于系统工程和模型协同设计。
为了想清楚 Agent 时代怎么发社交平台,我做了 ArcSocial 。ArcSocial 不是为了让 AI 替我写文章,而是为了把人的判断、Agent 的协作和平台发布流程组织成可追溯、可维护的工作区。

15 个来自火山引擎 V-START 加速器的项目,横跨具身智能、AI 陪伴硬件、Agent 工具、内容生成、AI 教育等赛道。都在各自的场景里,把模型能力变成了用户愿意持续使用甚至付费的产品体验,要么扎进了模型短期内替代不了的物理世界,要么在垂直场景里把 Agent 做到了用户真正愿意持续用的程度,要么用 AI 重构了一个原本就有刚需的消费品类。

来自 Sharpa、清华大学、UC Berkeley、上海交通大学、ETH Zurich 等机构的研究者提出了首个通用触觉基础策略 FTP-1。它基于约 3,000 小时、来自 26 个数据来源和 21 种触觉传感器的数据进行预训练