
中国龙虾第一芯!全球首款OpenClaw专属CPU,Arm、阿里云都来了
中国龙虾第一芯!全球首款OpenClaw专属CPU,Arm、阿里云都来了19日下午,此芯科技以「智启未来 芯动全球」为主题,在深圳举办OpenClaw CPU系列产品及方案矩阵发布会,正式推出全球首款OpenClaw专属CPU——CIX ClawCore螯芯系列。
来自主题: AI资讯
9618 点击 2026-03-20 14:38
 搜索
搜索
19日下午,此芯科技以「智启未来 芯动全球」为主题,在深圳举办OpenClaw CPU系列产品及方案矩阵发布会,正式推出全球首款OpenClaw专属CPU——CIX ClawCore螯芯系列。

没有农民,没有农机手,甚至没有一个人站在田间地头。
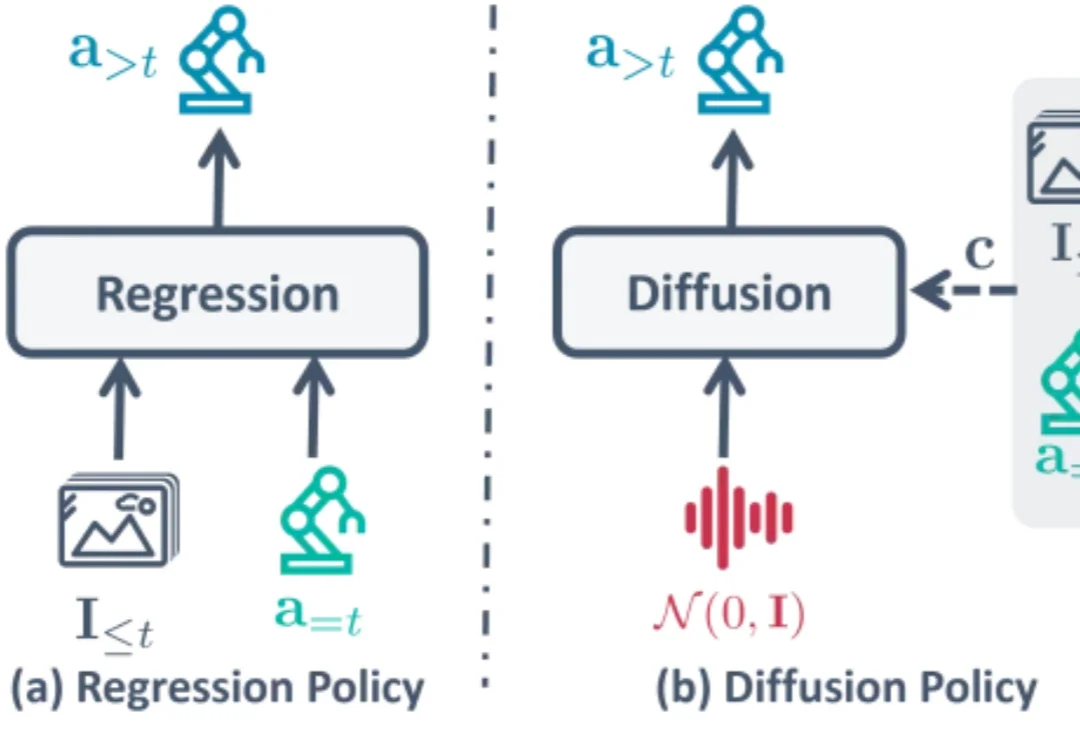
在机器人领域,扩散策略(Diffusion Policy)已经成为了标准模仿学习策略和 VLA 动作生成范式,但其「从随机噪声中迭代解噪」的机制带来了不容忽视的推理延迟。如果机器人不再从随机高斯噪声开始「盲猜」,是否可以基于「刚刚做了什么」来预测「下一步做什么」呢?
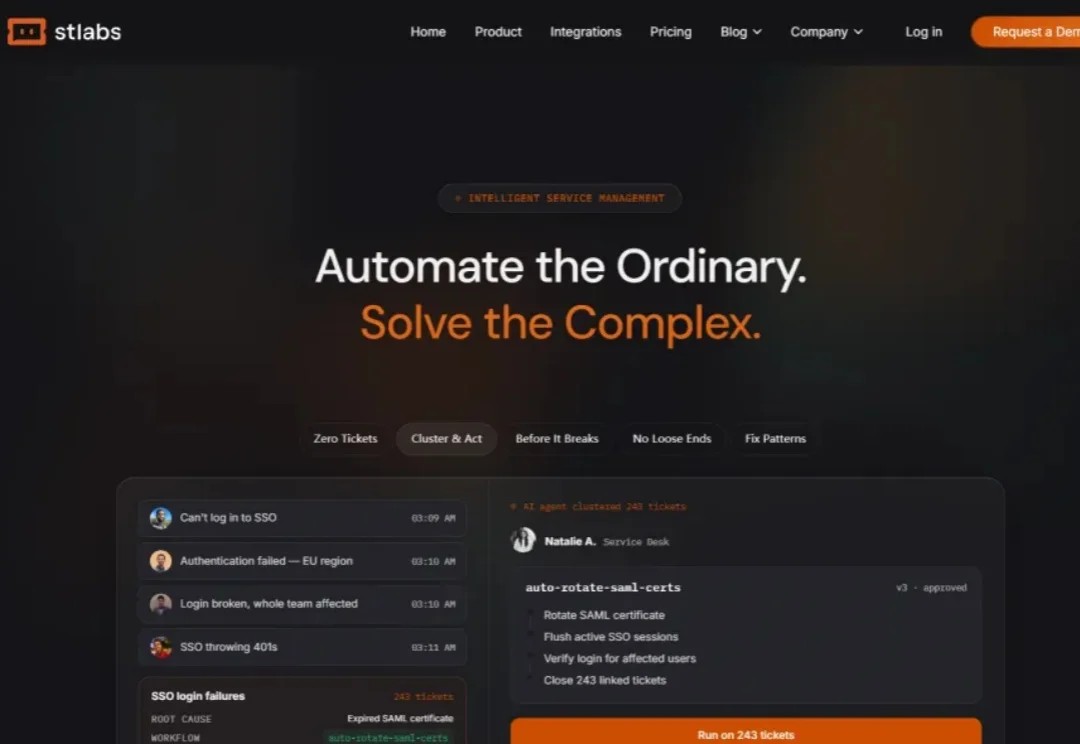
由 Datadog 前总裁阿米特·阿加瓦尔创立的 Standard Template Labs 已完成首轮 4900 万美元融资,旨在重塑大型企业内部信息技术服务的运作方式。
来自天工AI的SkyReels-V4,没打招呼,直接登顶Artificial Analysis文转视频(含音频)全球榜,超越Veo 3.1、Sora 2。一个月前,其Preview版本才刚拿下该榜全球第2。

Agnes AI近日披露了一组新的业务数据:全球用户规模已突破700万,年度经常性收入(ARR)接近2000万美元,并于去年底完成千万美元级融资。据公司方面透露,Agnes目前正在推进新一轮融资,目标估值约2亿美元,以持续投入核心技术研发并推动全球市场扩展。
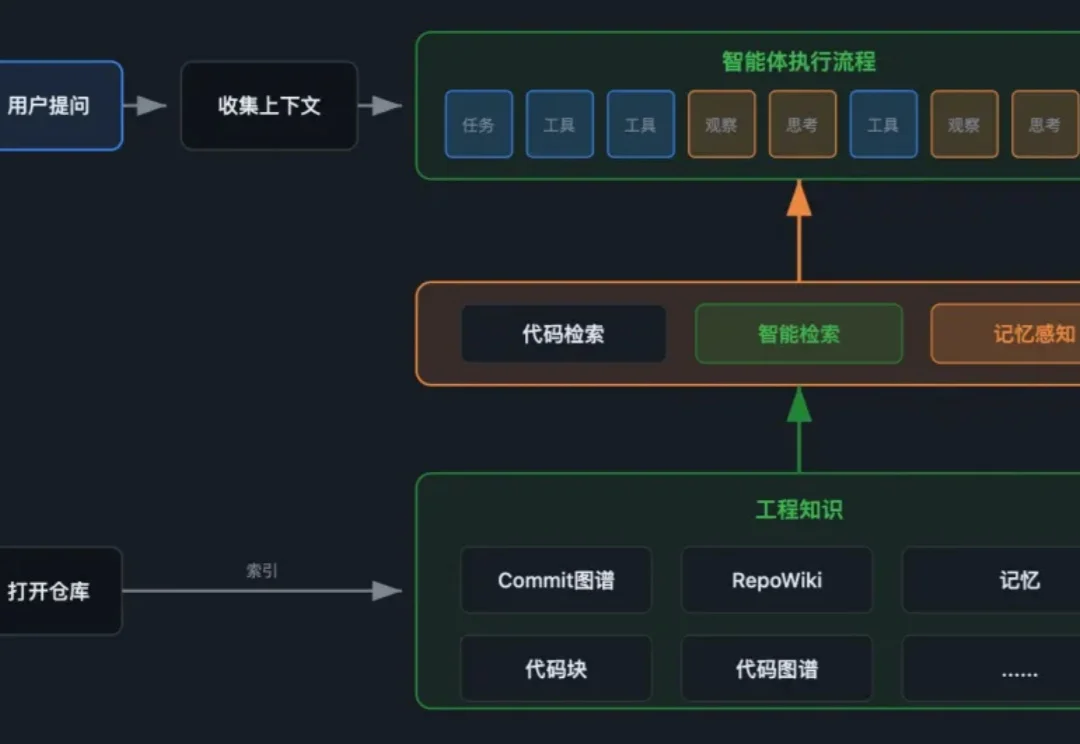
在AI编程智能体快速演进的今天,一个核心痛点愈发凸显:AI能写代码,却难以理解代码。更深层的问题是:即便模型能力再强,若缺乏结构化的工程约束与上下文支撑,智能体也难以稳定、可预期地完成真实工程任务。
Lovart是一个很好的AI产品,不仅是它能让你便宜用Nano banana🍌,更重要的是……好吧我编不下去了,Lovart的主要优点就是便宜用Nano banana,功能主要是🍌中转站。

过去一年,具身智能领域迎来了爆发式增长。从后空翻到托马斯回旋,从整理衣物到冲泡咖啡……各类令人惊艳的机器人演示视频层出不穷。

2025 年 1 月,特朗普在白宫亲自站台,宣布了一个号称“史上最大 AI 基础设施项目”的宏伟计划。OpenAI 联合软银、甲骨文和阿布扎比主权基金 MGX,组建了一家名为 Stargate LLC 的合资公司,承诺在四年内向美国 AI 基础设施投入 5,000 亿美元。