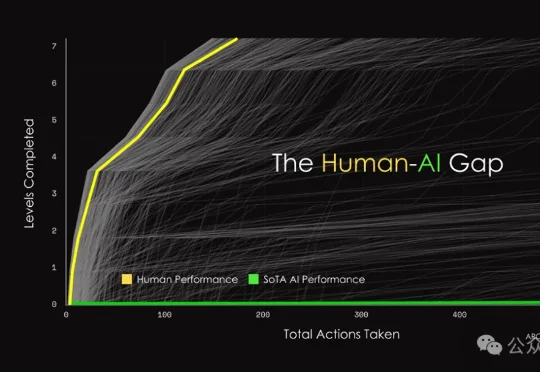
刚刚,全球最难考试惊天大反转!AI黑马 Symbolica冲破36%,顶流模型集体翻车
刚刚,全球最难考试惊天大反转!AI黑马 Symbolica冲破36%,顶流模型集体翻车就在昨天,ARC-AGI-3刚把全球顶尖大模型按在地上摩擦,结果一家名不见经传的公司却给出惊天消息:他们的AI在首日就取得了36.08%的成绩!这匹黑马究竟靠什么撕开全球最难AI考试的铁幕?是真突破,还是另有玄机?
来自主题: AI资讯
9192 点击 2026-03-27 15:24
 搜索
搜索
就在昨天,ARC-AGI-3刚把全球顶尖大模型按在地上摩擦,结果一家名不见经传的公司却给出惊天消息:他们的AI在首日就取得了36.08%的成绩!这匹黑马究竟靠什么撕开全球最难AI考试的铁幕?是真突破,还是另有玄机?
昨日凌晨,谷歌正式推出其最高质量的音频和语音模型——实时语音模型Gemini 3.1 Flash Live,并在Gemini App、Search Live以及Google AI Studio中同步开放,其中后者以预览版本向开发者提供。
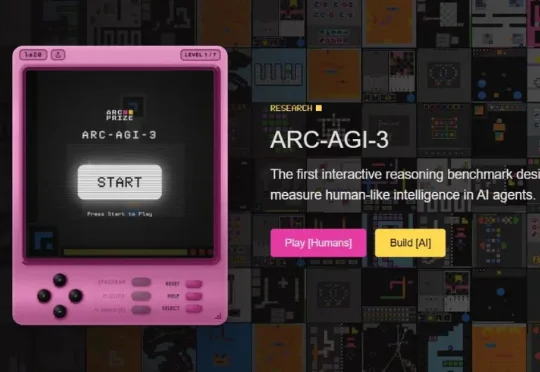
今夜,整个AI圈震动了。全球最难AGI测试ARC-AGI-3一上线,就把全球顶尖AI打到集体失声,人类满分通关,最强模型Opus 4.6得分仅0.2%,还不到1%。AI这是一夜被打回「原始人」了。

一次只持续了不到1小时的投毒事件,撕开了AI基础设施「信任链」的致命裂缝。更魔幻的是,全行业逃过一劫,居然靠黑客自己写出bug。
最近一直在聊Agent、聊Vibe Coding。

天使轮拿下2.42亿美元后,它石智航到底干啥去了?然而接下来的一年里,它石智航选择了一条截然不同的路:没有参加各种行业大会,没有频繁对外发声,没有出现在春晚或各类展示活动中,一直踏实干活。
这是一件极其严肃的软件安全事件。
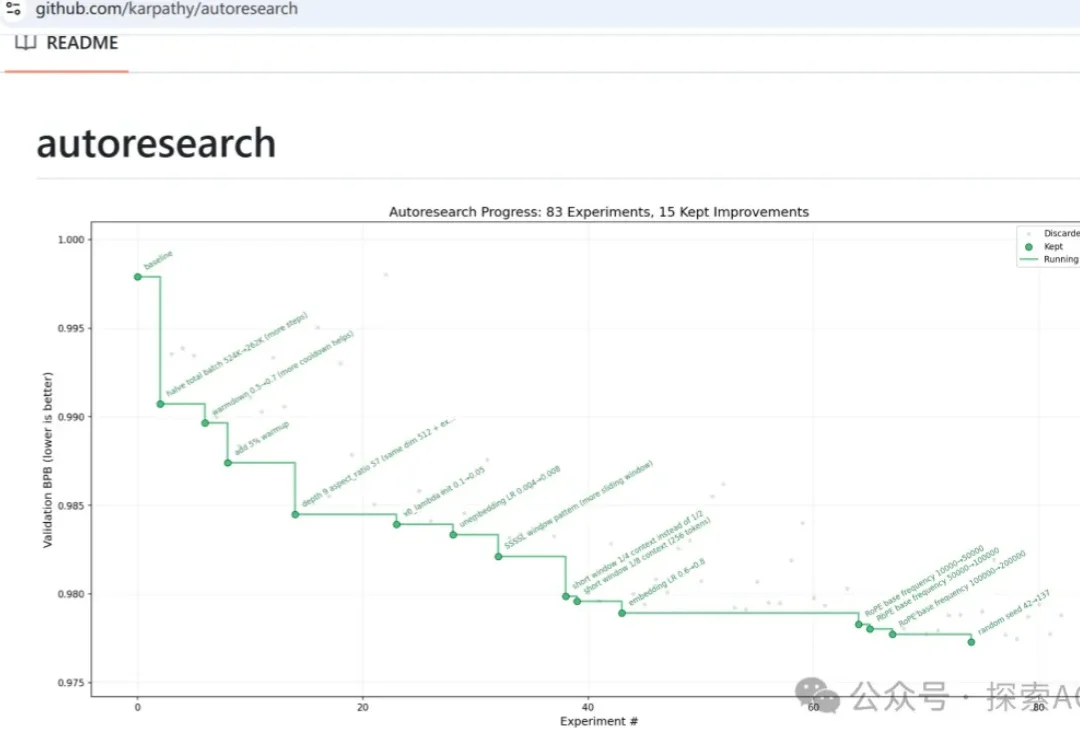
养了这么久的虾,你应该能发现,skills有多重要了。

UIUC研究团队打造ResearchArcade,将ArXiv论文、OpenReview评审、图表代码等碎片数据连接成动态知识图谱。模型可直接学习引用关系、修改轨迹与审稿互动,让AI更好辅助科研写作、修订与预测,为下一代科研智能体奠定统一数据基础。
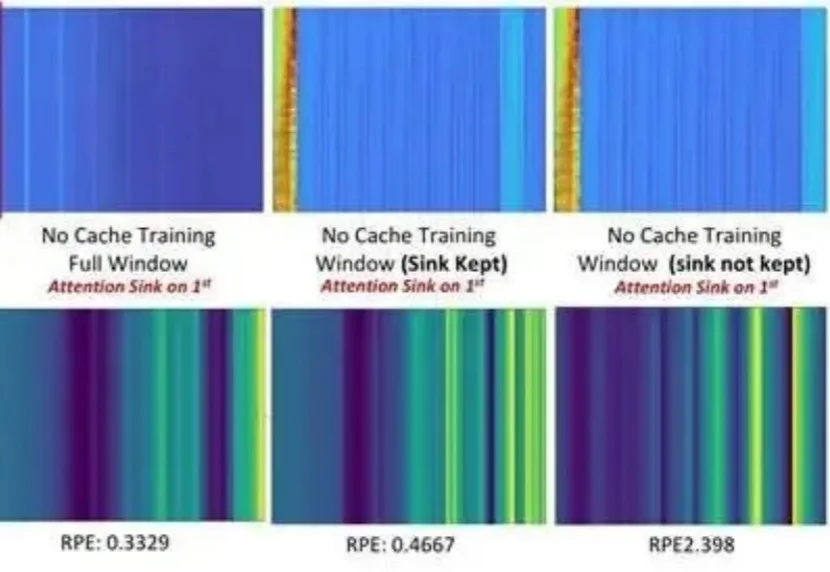
在自动驾驶、具身智能、AR/VR应用中做3D重建,大家都想解决一个终极问题: 模型能不能像人一样,一边往前看,一边持续构建三维世界?