
受Fable 5封禁影响,GPT-5.6或将延迟发布!
受Fable 5封禁影响,GPT-5.6或将延迟发布!Fable 5被禁用,美国政府指Anthropic态度敷衍,Anthropic坚称是孤立事件。Dario把技术比作核弹,如今却因不愿关闭系统而陷入绝境,把美国整个AI行业拉下水。
来自主题: AI资讯
7018 点击 2026-06-16 10:22
 搜索
搜索
Fable 5被禁用,美国政府指Anthropic态度敷衍,Anthropic坚称是孤立事件。Dario把技术比作核弹,如今却因不愿关闭系统而陷入绝境,把美国整个AI行业拉下水。
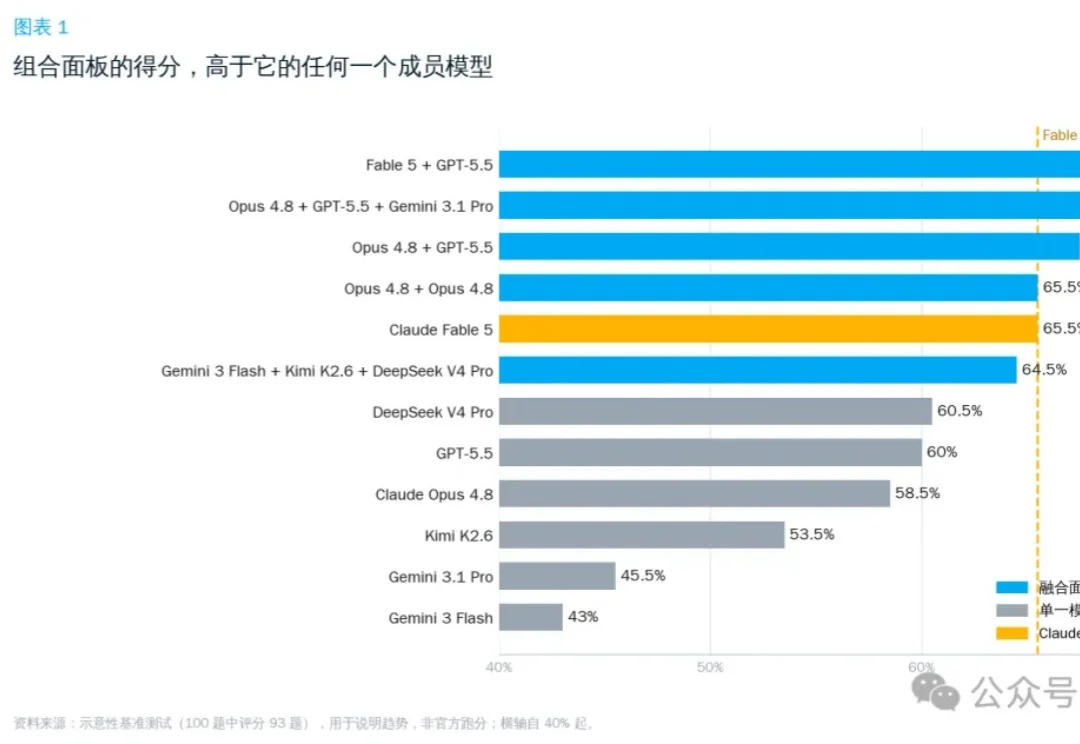
AI网关OrcaRouter最近上线了一套可编程路由策略Routing DSL,多个模型同时答题,自动仲裁出最优解。几个你现在就能调用的“常规模型”,给它来个组合编排,跑出来的综合胜率,直接掀翻了Fable 5的单体基准线。Opus 4.8打不过Fable 5,GPT-5.5也单挑不过,但这两个拼一组,结果就反超了。

新智元报道 【新智元导读】FuseSearch:学习型自适应并行执行 —— 一个40亿参数的模型,凭什么在代码定位上干过了商用闭源大模型?答案只有四个字:搜得更聪明。 在AI编程狂飙突进的今天,一个尴

如今手机拍照已成日常,后期修图是提升照片质感的关键。
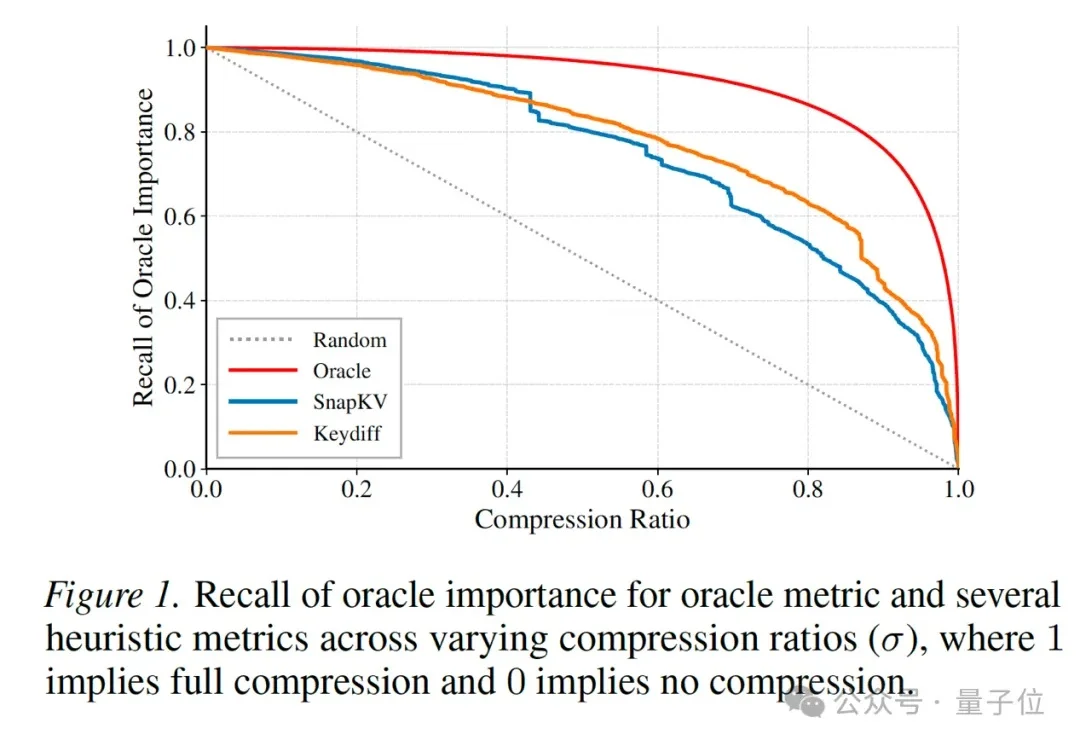
随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。

Minerva 正式公开上线了他们的 AI 营销平台,同时宣布完成了这轮融资。投资方名单相当亮眼:The General Partnership、8VC、Lingotto Innovation、Topology Ventures,还有 NBA 官方投资部门 NBA Investments。与此同时,他们还公布了与 OpenAI 的深度合作关系,

随着 Harvey 和 Legora 完成八位数融资轮次,法律工具已被证明是人工智能初创公司中增长最快、竞争最激烈的垂直领域之一。但尽管这些工具专注于私人执业,一些初创公司认为法律市场中仍有大量需求未被满足。
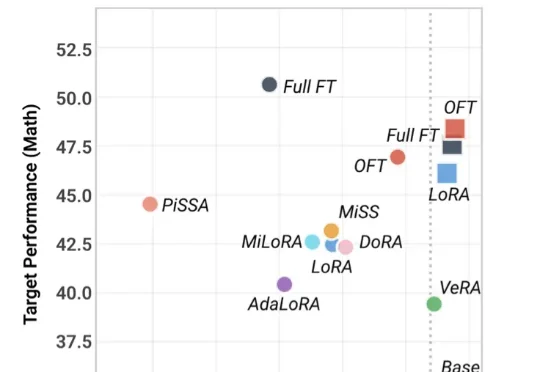
近期,来自香港中文大学、西湖大学、德国马普所等机构的研究者提出了 PEFT-Arena —— 一个从稳定性‑可塑性权衡(stability–plasticity trade-off)视角重新审视 PEFT 方法的评测基准与分析框架。该工作已在 ICLR 2026 相关 workshop 上进行了展示,并开源了完整代码。

谷歌DeepMind宣布:AGI,已经过时了!就在最近,谷歌DeepMind出了一份干货满满的57页报告,标题只有四个词:《从AGI到ASI》。论文地址:https://arxiv.org/abs/2606.12683

5 月中旬,一个名叫 anysearch-skill 的开源仓库出现在 GitHub 上,一周之内冲上了 Agent 技能市场 Skills.sh 的热榜第一。开发者们发现,给自己的 Agent 装上这个 Skill 之后,原本要搜七八轮才能拼凑完整的调研任务,常常一两次调用就能拿到结果,而且返回的不是网页链接,是可以直接进推理链路的结构化数据。