
上海跑出超级隐形冠军:年入3.8亿,国内第一
上海跑出超级隐形冠军:年入3.8亿,国内第一最近,上海跑出一个超级隐形冠军:进馨科技,在美国纳斯达克成功上市。
来自主题: AI资讯
8044 点击 2024-12-25 09:48
 搜索
搜索
最近,上海跑出一个超级隐形冠军:进馨科技,在美国纳斯达克成功上市。
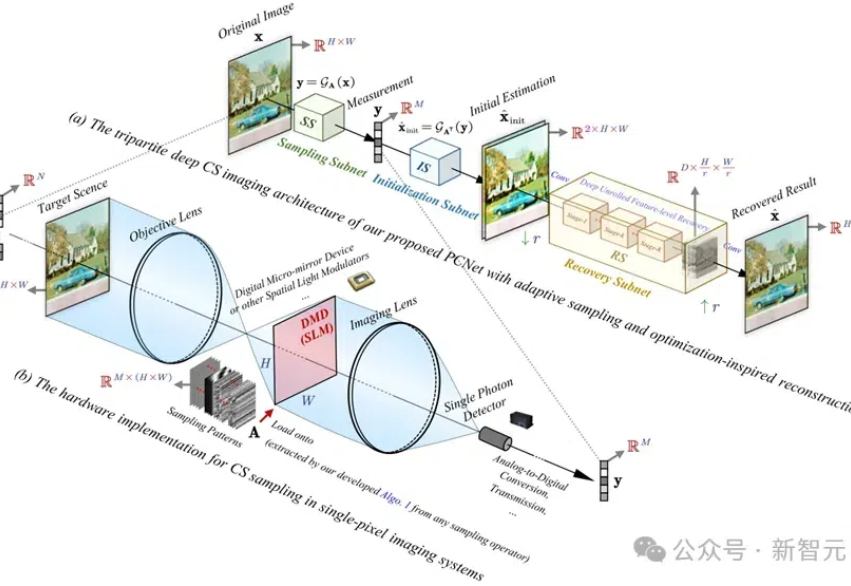
PCNet网络具有创新的协同采样算子和优化的重建网络,实验结果证明,其在图像重建精度、计算效率和任务扩展性方面均优于现有方法,为高分辨率图像的压缩感知提供了新的解决方案。

研究人员提出首个可以渲染高动态范围(High Dynamic Range, HDR)自然光的3DGaussian Splatting模型HDR-GS,以用于新视角合成(Novel View Synthesis, NVS)。
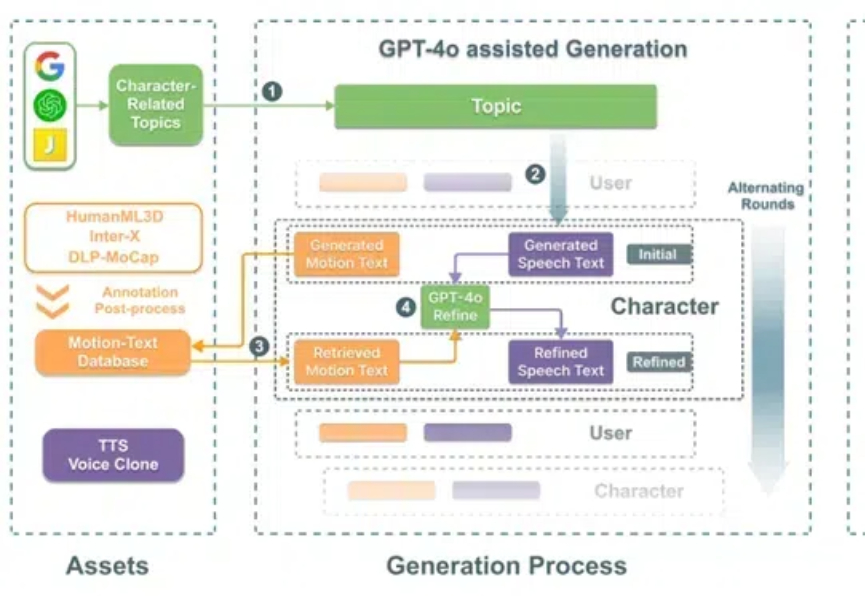
SOLAMI是一个创新的VR端3D角色扮演AI系统,用户可以通过语音和肢体语言与虚拟角色进行沉浸式互动。该系统利用先进的社交视觉-语言-行为模型,结合合成的数据集,提供更自然的交流体验,超越了传统的文本和语音交互。
在数字化浪潮席卷全球的今天,数据已成为企业最宝贵的资产之一。如何从海量数据中提取有价值的信息,转化为决策支持,是每个企业都在积极探索的问题。
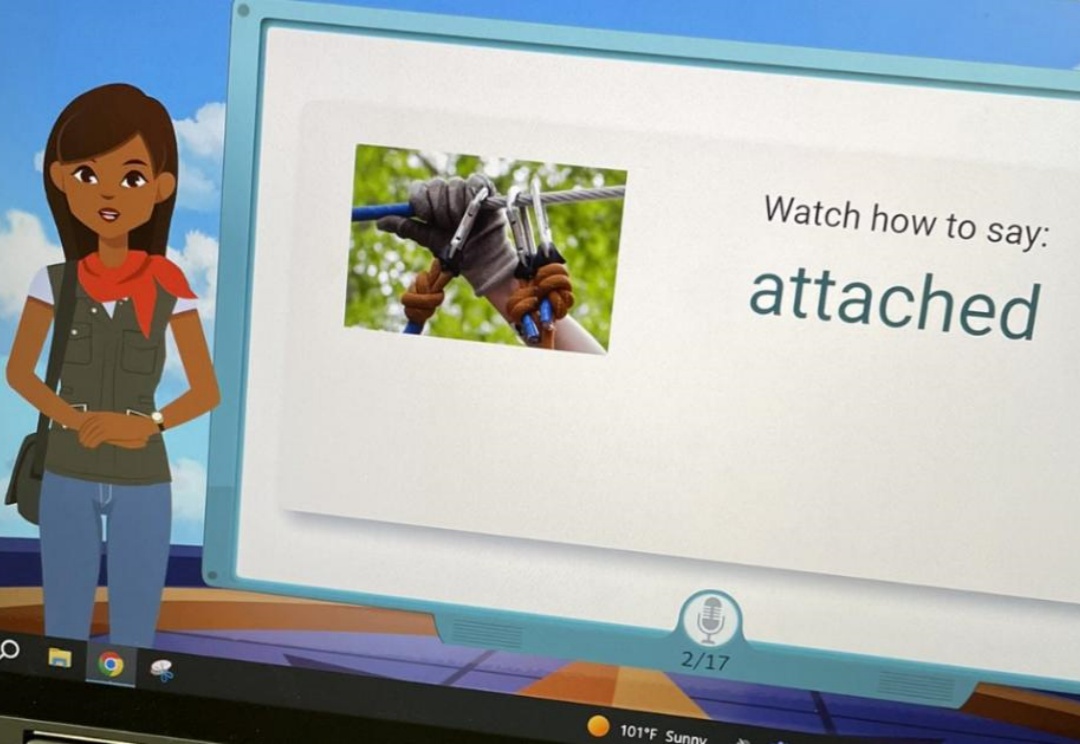
Amira的AI老师擅长语音识别技术。

Jiaming Song详细介绍了Diffusion模型在视觉生成领域的前沿研究,强调其在提升生成视觉模型质量中的关键作用。他分享了自己从斯坦福大学的博士研究到加入NVIDIA和Luma AI的历程,展示了如何将贝叶斯非参数模型的知识应用到生成式AI中,推动了视觉模型在生成质量和速度上的显著提升。

在金融市场中,动态知识图谱(Dynamic Knowledge Graphs,DKGs)是一种表达对象之间随时间变化的多种关系的流行结构。它们可以有效地表示从复杂的非结构化数据源(如文本或图像)中提取的信息。在金融应用中,基于从金融新闻文章中获取的信息,DKGs 可用于检测战略性主题投资的趋势。

字节的AI爆款有戏吗? 今年最火的两款全球AI产品,当属视频生成大模型产品Sora和音乐生成大模型产品Suno。

TL;DR:DuoAttention 通过将大语言模型的注意力头分为检索头(Retrieval Heads,需要完整 KV 缓存)和流式头(Streaming Heads,只需固定量 KV 缓存),大幅提升了长上下文推理的效率,显著减少内存消耗、同时提高解码(Decoding)和预填充(Pre-filling)速度,同时在长短上下文任务中保持了准确率。