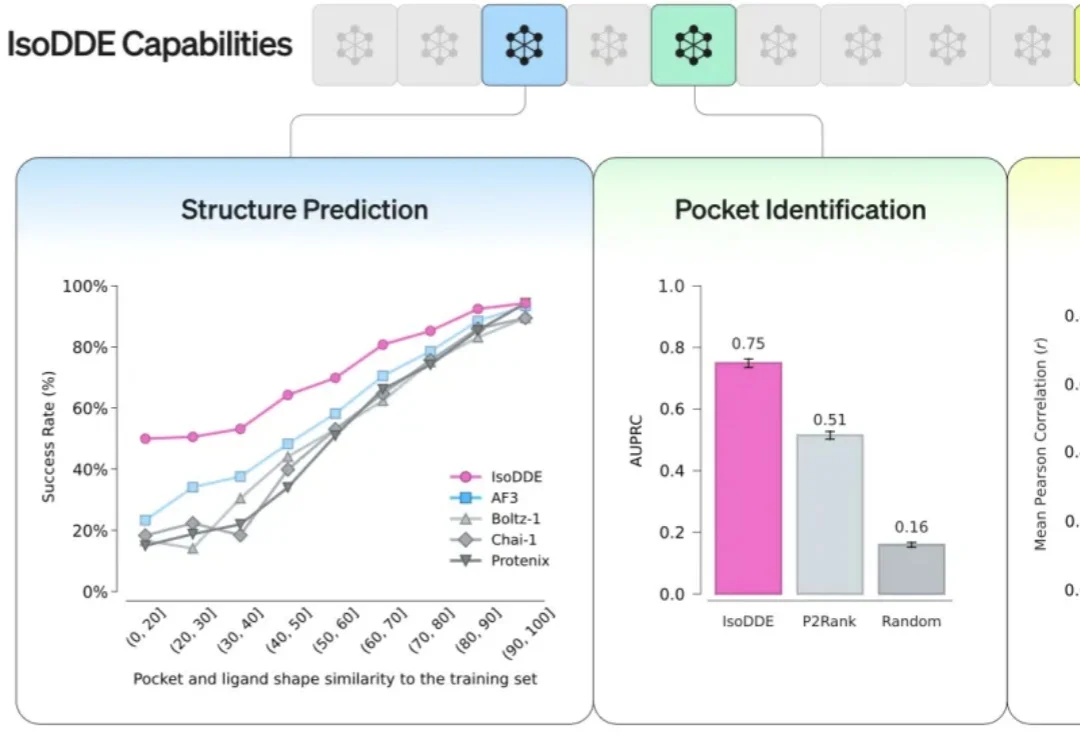
刚刚,最强AI制药模型问世,谷歌诺奖天团力作,碾压AlphaFold3,生物医药一夜变天!
刚刚,最强AI制药模型问世,谷歌诺奖天团力作,碾压AlphaFold3,生物医药一夜变天!谷歌DeepMind和Isomorphic Labs合作,祭出了药物设计之王。
来自主题: AI资讯
7077 点击 2026-02-12 15:40
 搜索
搜索
谷歌DeepMind和Isomorphic Labs合作,祭出了药物设计之王。

关于那个神秘的「Pony Alpha」模型的传言,已经在互联网发酵了一周。
过去一年,大模型写代码的能力几乎以肉眼可见的速度提升。从简单脚本到完整功能模块,GPT、Claude、DeepSeek 等模型已经能够在几秒钟内生成看起来相当 “专业” 的代码。

深夜,GLM-5来了。
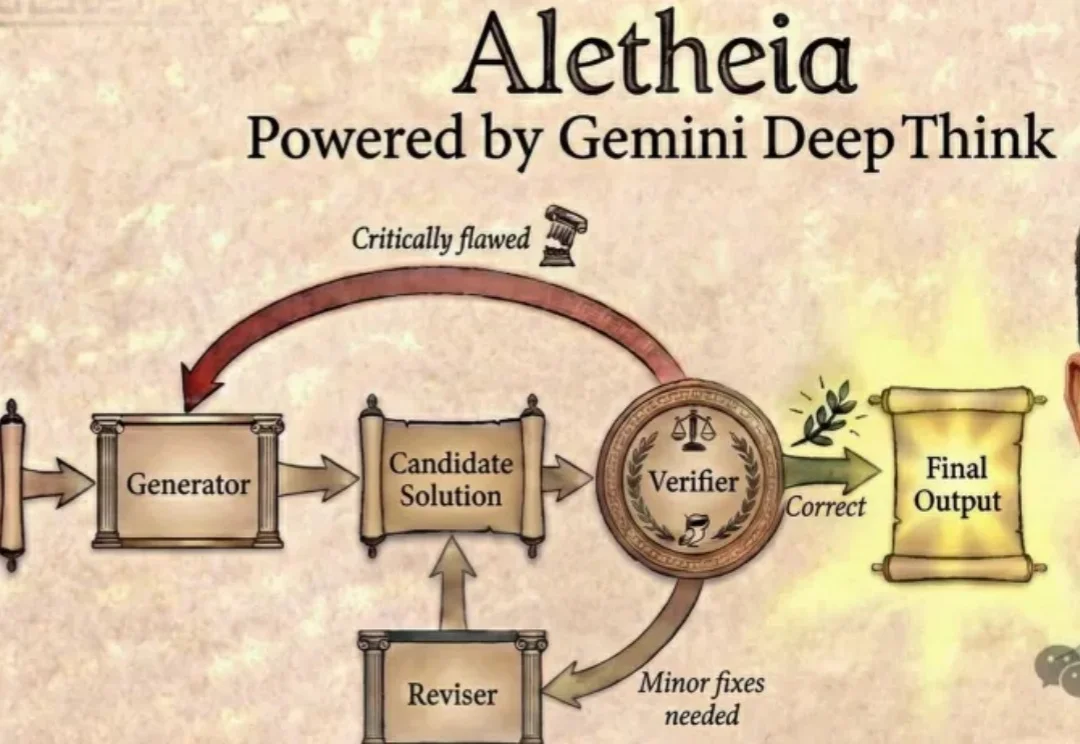
今天,谷歌DeepMind「AI数学家」Aletheia彻底杀疯了,攻克数学猜想,独立写论文。更令人震惊的是,拿下金牌的Gemini一举横扫18大核心科研难题。
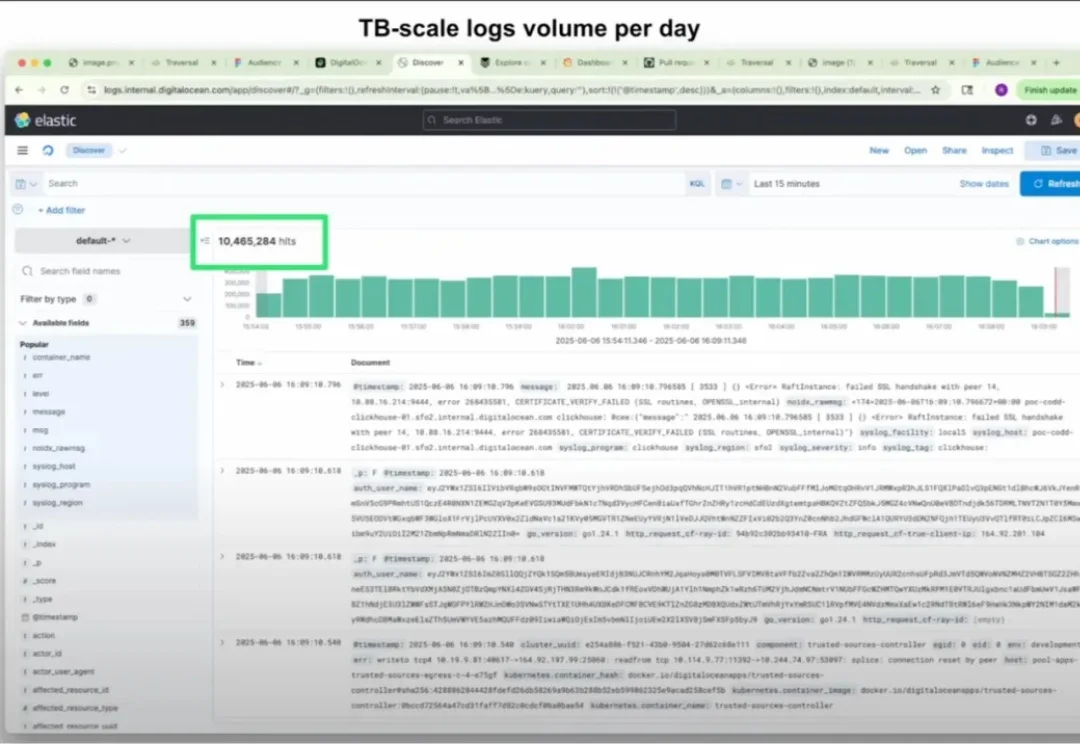
代码运维一直是开发者的痛点,AI Coding 的飞速进步放大了运维难度:Claude Code 贡献的代码 push 已经占到了公开 Github 的 4%,但 AI 写的系统逻辑会有人类很难捕捉的问题,开发者将其称为“Claude Hole”现象。
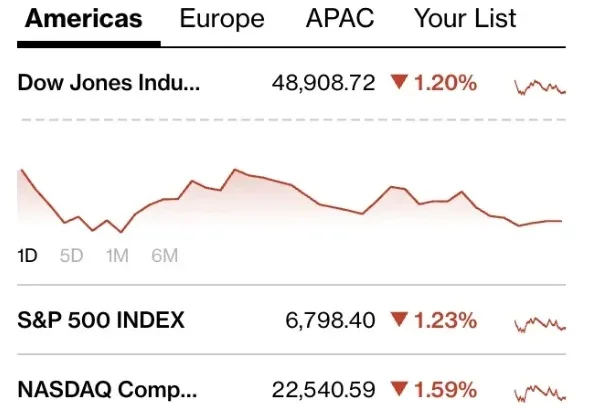
最强的大模型,已经把scaling卷到了一个新维度:百万级上下文。
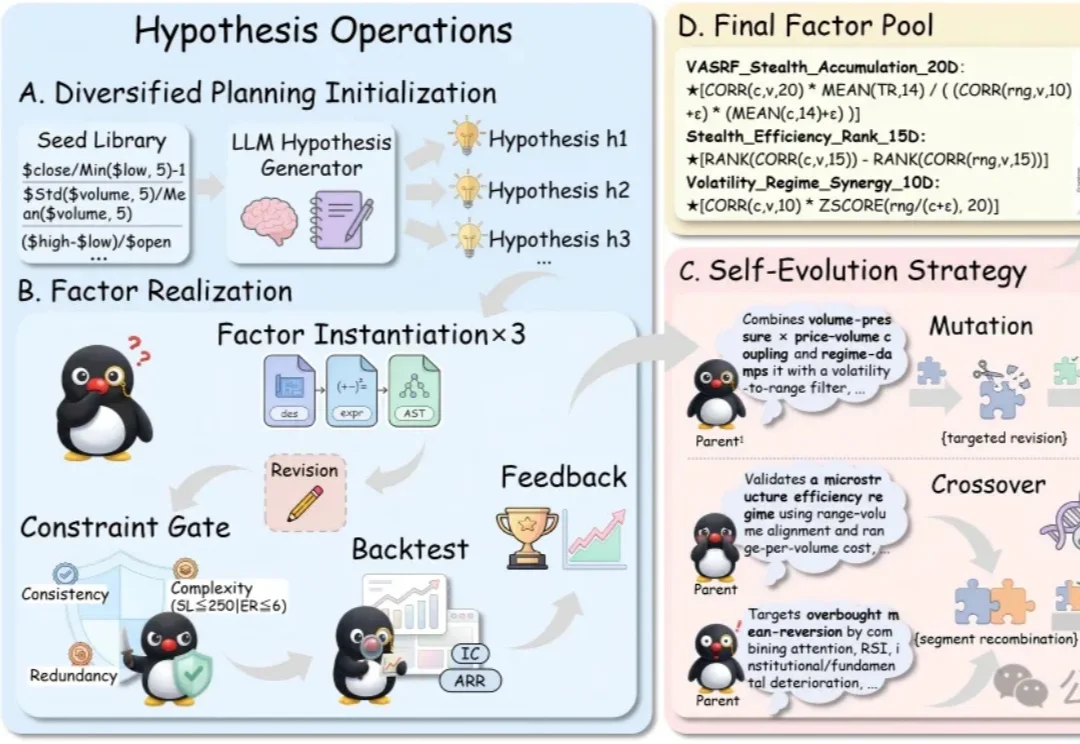
在量化金融的底层,Alpha因子本质上是一段可执行的代码逻辑,它们试图将嘈杂的市场数据映射为精准的交易信号。
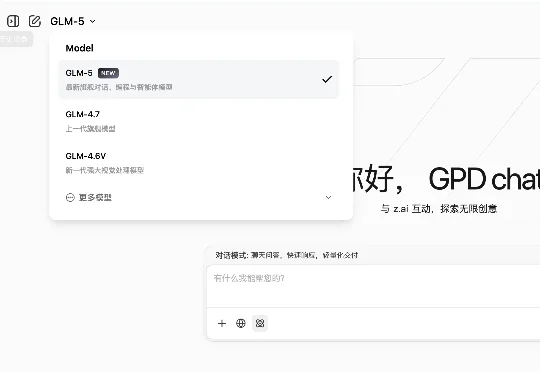
2月11日深夜,智谱AI官宣新一代旗舰大模型GLM-5。之前在OpenRouter上神秘出现的"Pony Alpha",身份终于揭晓。据DoNews报道:Pony Alpha就是GLM-5的低调测试版。

过去几年,AI 行业几乎把所有注意力都投向了“会不会想”:更强的推理、更大的模型、更快的生成。但在真实世界里,很多问题并不是想不想得出来,而是你到底记不记得发生过什么——尤其是视频。