
全球首个世界统一模型发布,机器人家庭成员来了!
全球首个世界统一模型发布,机器人家庭成员来了!就在刚刚,自变量机器人发布了全球首个世界统一模型架构的具身智能基础模型:WALL-B。基于世界统一模型,WALL-B解决了传统VLA架构在模块间数据搬运上的bug点——
来自主题: AI资讯
6695 点击 2026-04-22 18:52
 搜索
搜索
就在刚刚,自变量机器人发布了全球首个世界统一模型架构的具身智能基础模型:WALL-B。基于世界统一模型,WALL-B解决了传统VLA架构在模块间数据搬运上的bug点——

用AI跑批量任务的人,手里基本都有一个干活的模型,不是最聪明,但要快、要便宜,稳定不出岔子。
神秘模型Elephant的面纱,终于被揭开了。

先说一个很多人没意识到的事实:2026年了,每个主流Agent框架底下的工具调用训练数据,格式全是乱的。

AI科技评论独家获悉,卡内基梅隆⼤学机器⼈研究院(CMURI)博⼠后、悉尼⼤学(USYD)⻓聘助理教授WilliamZhi联合创办具⾝智能公司⸺ZenoAI(芝诺机器⼈),致⼒于打造通⽤全栈物理智能(Full-stackPhysicalAI),提供可靠的全⾝灵巧操作解决⽅案。
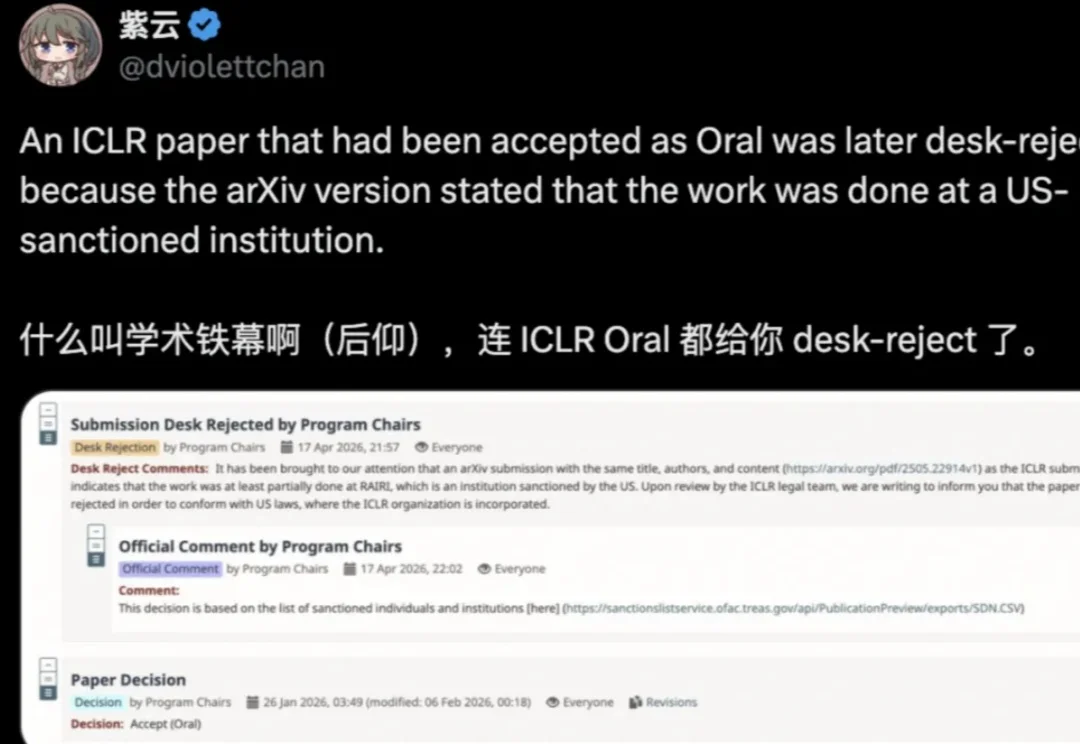
「学术铁幕!连 ICLR Oral 都给 desk-reject 了。」
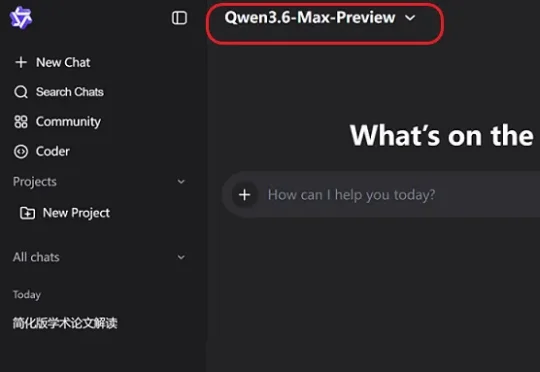
今天,阿里发布了其下一代旗舰模型的早期预览版:Qwen3.6-Max-Preview。在第三方评测榜单Artificial Analysis的智能指数排名中,Qwen3.6-Max-Preview的得分为52分,小幅超过GLM-5.1、MiniMax-M2.7,成为这一榜单上得分最高的国产模型。
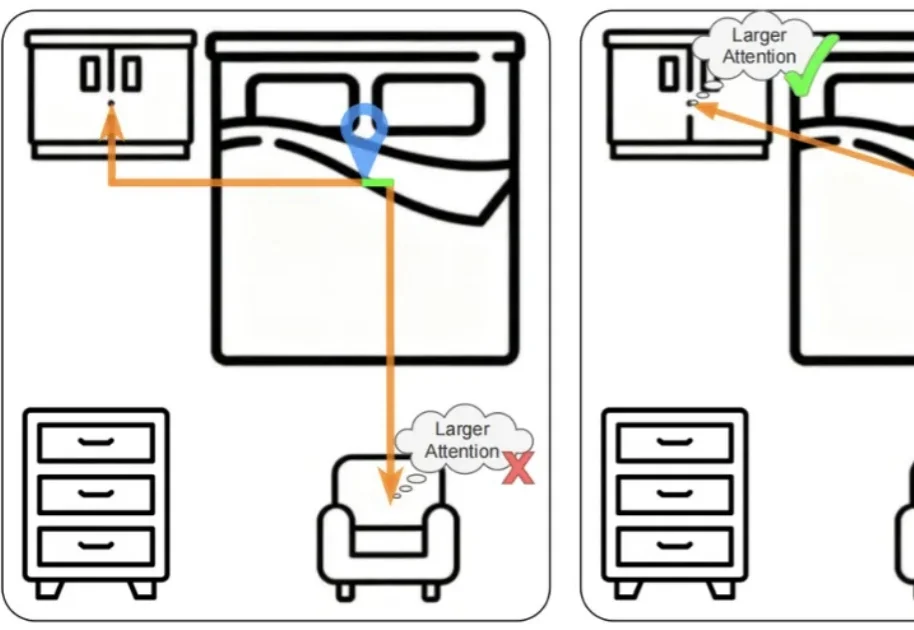
本文主要介绍来自该团队的最新论文:Scalable Object Relation Encoding for Better 3D Spatial Reasoning in Large Language Models。

如何创建大规模的Physical AI数据,来加速Physical AI开发者的进展。我们采取的方法,本质上是用算力去换数据;
前段时间有个叫 Happy Horse 的模型实火了一把,在知名 AI 评测分析平台 Artificial Analysis 上,直接把 Seedance 2.0 挤到了第二。