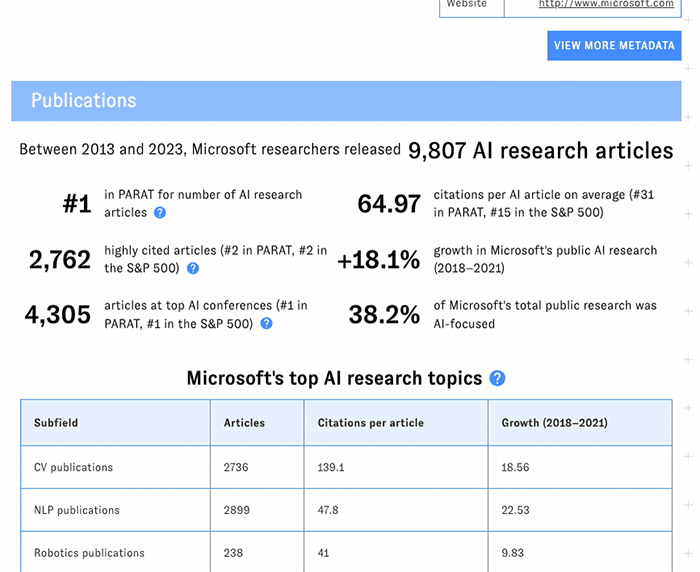
Nature:谷歌AI研究引用量登全球榜首,中国企业表现亮眼
Nature:谷歌AI研究引用量登全球榜首,中国企业表现亮眼在AI领域,硅谷巨头Alphabet(谷歌母公司)和微软的论文引用量最高,远超其他公司。 不过,中国企业百度和腾讯在专利方面领先。
来自主题: AI资讯
9441 点击 2024-08-02 16:30
 搜索
搜索
在AI领域,硅谷巨头Alphabet(谷歌母公司)和微软的论文引用量最高,远超其他公司。 不过,中国企业百度和腾讯在专利方面领先。

现在,大模型可以做私人导游,为你规划Citywalk路线了——

网友:学术圈该有的样子! 现在,arXiv的每篇论文,都能直接提问讨论了! 只需把URL中的arXiv替换成AlphaXiv,就能对任意一篇论文发布提问或讨论。

谷歌DeepMind的小模型核弹来了,Gemma 2 2B直接击败了参数大几个数量级的GPT-3.5和Mixtral 8x7B!而同时发布的Gemma Scope,如显微镜一般打破LLM黑箱,让我们看清Gemma 2是如何决策的。

7 月,大模型公司 Cohere 宣布 D 轮融资 5 亿美元,估值 55 亿,比去年高了一倍多。 跟 OpenAI、Anthropic 甚至法国 AI 公司 Mistral 相比,成立于加拿大的 Cohere 略显低调,没有推出自己的 Chatbot、文生图或者文生视频产品,不涉足个人消费端产品;即使是推出的开源大模型 Command R+,似乎也没有那么引人注意。
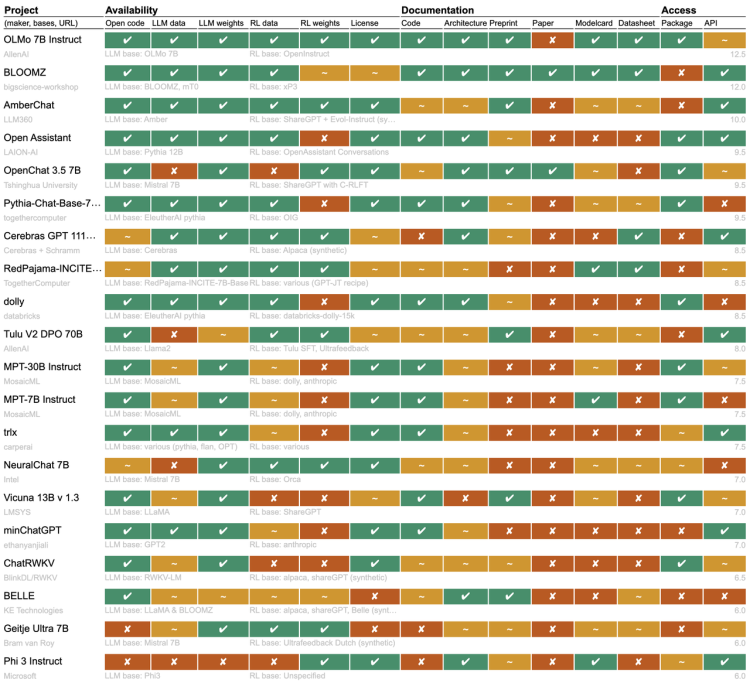
最近一段时间开源大模型市场非常热闹,先是苹果开源了70亿参数小模型DCLM,然后是重量级的Meta的Llama 3.1 和Mistral Large 2相继开源,在多项基准测试中Llama 3.1超过了闭源SOTA模型。 不过开源派和闭源派之间的争论并没有停下来的迹象。

“假如你有幸年轻时在巴黎生活过,那么你此后一生中不论去到哪里她都与你同在,因为巴黎是一席流动的盛宴。” 海明威如此记录下他1921年-1926年的巴黎岁月。一个世纪后,巴黎这席流动的盛宴依旧浪漫松弛。 但流动的不再仅是人文历史与艺术,AI技术也在摩拳擦掌等待登台——从运动员的赛前准备到在电视机前的观赛群众,AI在以不同的形式,提升效率和体验。

随着海内外底层模型能力差距的不断缩小,未来AI应用领域也极有概率由大批中国企业组成头部阵营。

第一次拜访K-Scale Labs的时候,好像走进了美剧《硅谷》的拍摄现场。

音视频大语言模型在处理视频内容时,往往未能充分发挥语音的作用。video-SALMONN模型通过三部分创新:音视频编码和时间对齐、多分辨率因果Q-Former、多样性损失函数和混合未配对音视频数据训练。该模型不仅在单一模态任务上表现优异,更在视听联合任务中展现了卓越的性能,证明了其全面性和准确性。