
上线狂揽10万Discord用户,DeepMind走出AI视频生成黑马,获顶级机构近亿美金美元投资
上线狂揽10万Discord用户,DeepMind走出AI视频生成黑马,获顶级机构近亿美金美元投资Moonvalley 是一家位于洛杉矶 AI 生成视频公司,在 Discord 上拥有超过 10 万名用户,discord 提供了一个互动平台,用户可以分享经验、反馈和创作。
来自主题: AI资讯
9019 点击 2024-12-16 14:54
 搜索
搜索
Moonvalley 是一家位于洛杉矶 AI 生成视频公司,在 Discord 上拥有超过 10 万名用户,discord 提供了一个互动平台,用户可以分享经验、反馈和创作。

据DEFENSESCOOP 报道,美国军方在追求新型人工智能工具的过程中,Palantir 和 Anduril 这两家公司在国防技术领域的地位日益突出。

在Ilya探讨完「预训练即将终结」之后,关于Scaling Law的讨论再次引发热议。
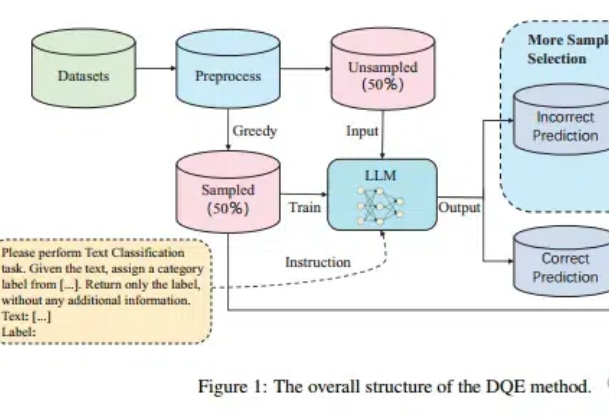
Scaling Law不仅在放缓,而且不一定总是适用! 尤其在文本分类任务中,扩大训练集的数据量可能会带来更严重的数据冲突和数据冗余。
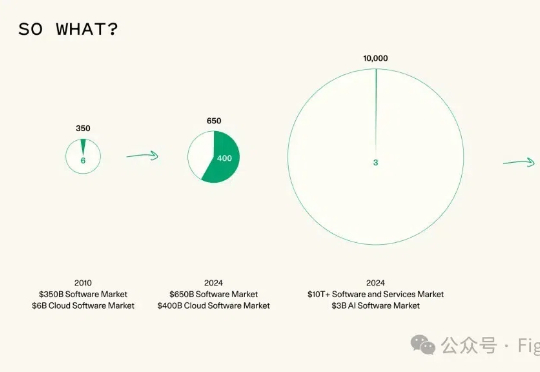
Sequoia Capital(红杉资本) 最近发表了一篇文章《AI in 2025: Building Blocks Firmly in Place》,对2025年的AI发展趋势做了三个预测,一定程度上反映了资本对于大模型方向一些定性判断。

Mamba 这种状态空间模型(SSM)被认为是 Transformer 架构的有力挑战者。近段时间,相关研究成果接连不断。而就在不久前,Mamba 作者 Albert Gu 与 Karan Goel、Chris Ré、Arjun Desai、Brandon Yang 一起共同创立的 Cartesia 获得 2700 万美元种子轮融资。

苹果首款 AI 芯片「Baltra」2026 年量产。

「Scaling Law」和「打脸时刻」,绝对是2024年科技智能领域的年度关键词。
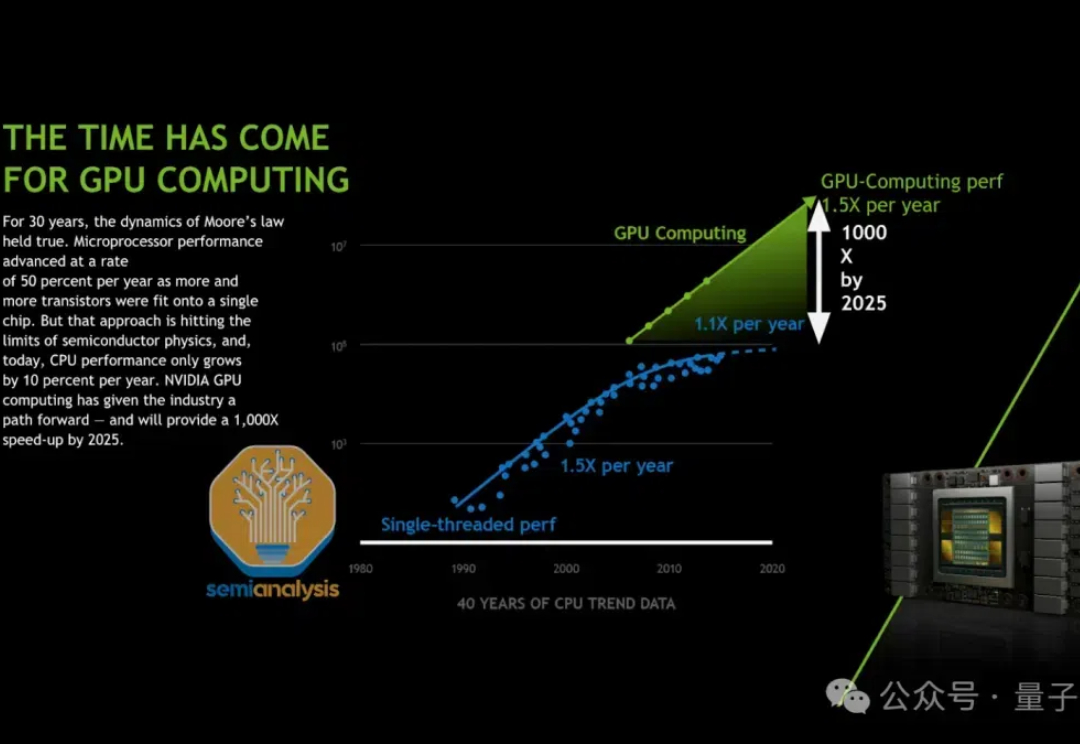
传闻反转了,Claude 3.5 Opus没有训练失败。 只是Anthropic训练好了,暗中压住不公开。 semianalysis分析师爆料,Claude 3.5超大杯被藏起来,只用于内部数据合成以及强化学习奖励建模。 Claude 3.5 Sonnet就是如此训练而来。

关于当前的局势和未来的走势,最近流传很多悲观的论调。但我以前就说过,接下来的周期,只是失去了过去那种确定性的发展主旋律,并不意味着个体没有发展的机会和空间。