
Midjourney新副业曝光:50万个传感器藏进浴池,60秒生成你的3D身体地图
Midjourney新副业曝光:50万个传感器藏进浴池,60秒生成你的3D身体地图搞AI绘画的Midjourney,要干上Spa了???
来自主题: AI资讯
8541 点击 2026-06-19 10:45
 搜索
搜索
搞AI绘画的Midjourney,要干上Spa了???
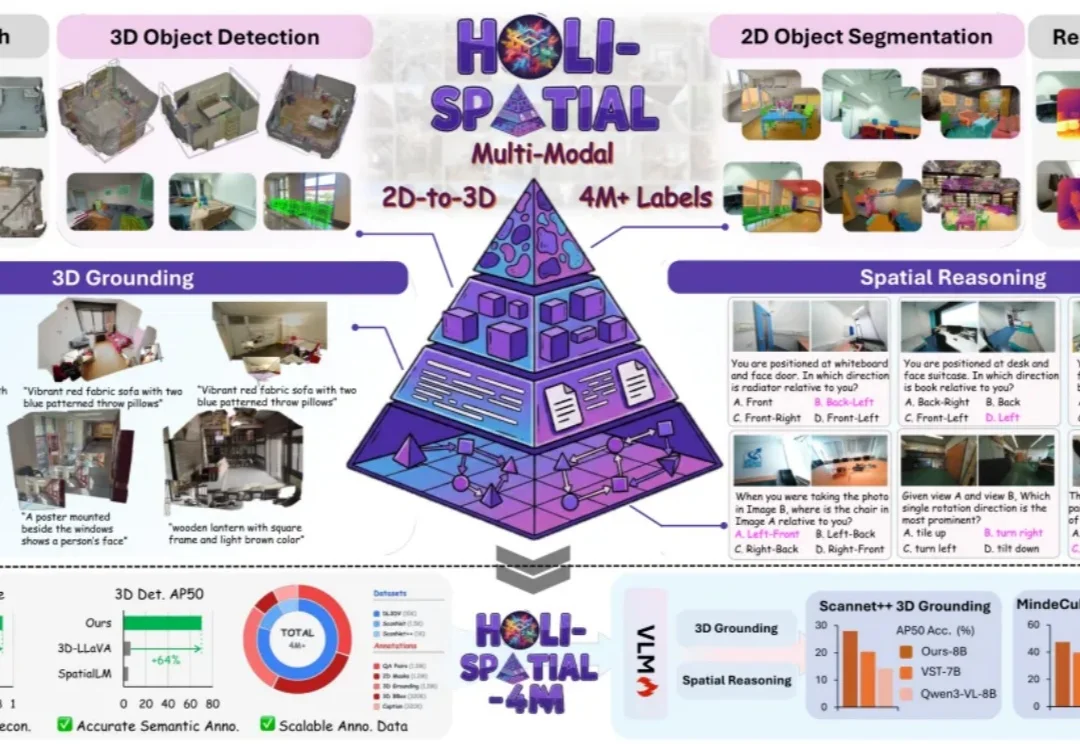
从原始视频出发,无需人工介入,自动生成 3D 重建、深度、2D mask、3D 框、实例描述、3D grounding 和空间问答。Holi-Spatial 试图把「空间智能」的数据生产,推进到自动化、可扩展的新阶段。

投中网独家获悉,专注于因果世界模型(Causal World Model)的人工智能公司Aether AI 正式宣布完成首轮融资,募集资金总额约2000万美元。该轮融资由经纬创投领投,英诺基金、SWC Global、九合创投等机构联合参投。
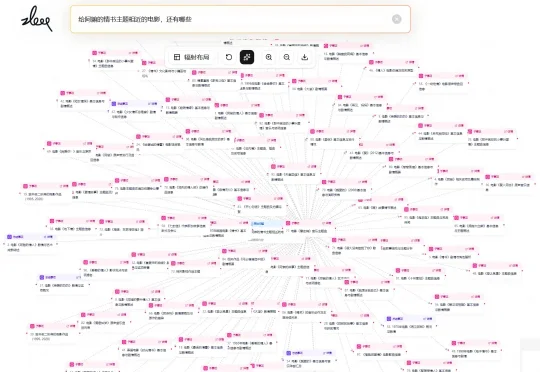
广州智跃深空人工智能科技有限公司 Zleap AI 提出的 SAG(SQL-Retrieval Augmented Generation) 出场了。其实,名字已经点题了——不是 Graph、Hippo,而是 SQL-Retrieval。它的核心想法是在离线阶段,SAG 先把原始文本先整理成「事项 + 实体」的数据库结构。等查询来了,再围绕当前问题,用 SQL 动态串出一张局部线索网。

模型还不够完美,但机器人必须开始干活。Ferrata 想解决的,正是 Physical AI 从 Demo 走向真实现场之前,最缺的那层安全绳。

KOID是美股首支覆盖具身智能和Physical AI全生态的ETF,持仓50家公司,横跨美国、中国、日本、欧洲市场,目前持有16家中国公司(文末有清单)。KOID不仅押注人形机器人整机厂商,更侧重上游零部件、芯片等核心资产,整体投资思路是复刻“卖铲子”和“卡脖子”逻辑。

九章云极能成为AI时代的“公共基础设施”吗?

Salesforce 公司已同意以约 36 亿美元收购 Fin——一家开发人工智能驱动型顾客服务代理的公司,这家软件企业正致力于为企业级 AI 赢得新业务。Fin 的旗舰产品 AI Agent 可通过聊天、电子邮件、WhatsApp、短信、短信、电话和 Slack 处理顾客查询。

今日,SENASIC琻捷(6675.HK)正式登陆港交所,成为港股市场首家聚焦Physical AI端侧感算芯片赛道的上市公司。上市首日,SENASIC琻捷高开72.11%报31.6港元,市值逼近120亿港元。
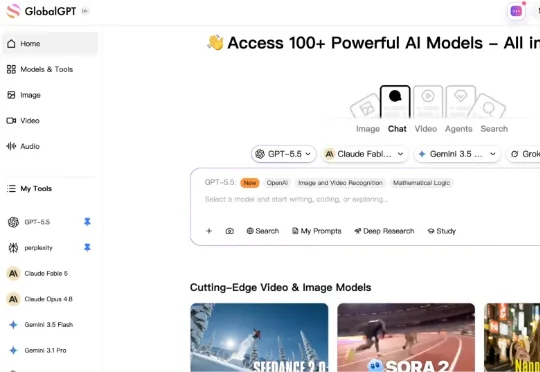
GlobalGPT 是一款很典型的 AI 套壳产品,一份订阅访问市面上几乎所有主流 AI 模型,目前全球累计用户超过 300 万,ARR 做到 1000 万美金。创始人李焕之,律师出身,2022 年开始连续创业,经历了 LegalDAO(Web3 法律社区)、LegalNow(AI 法律产品)的两次pivot后,在 2024 年初团队现金流只剩 1 个月时做出了 GlobalGPT。