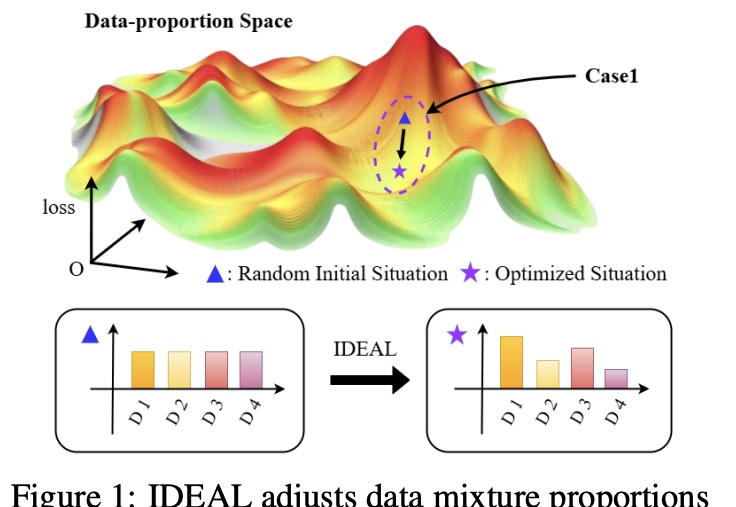
一招缓解LLM偏科!调整训练集组成,“秘方”在此 | 上交大&上海AI Lab等
一招缓解LLM偏科!调整训练集组成,“秘方”在此 | 上交大&上海AI Lab等大幅缓解LLM偏科,只需调整SFT训练集的组成。
来自主题: AI技术研报
8093 点击 2025-06-11 12:01
 搜索
搜索
大幅缓解LLM偏科,只需调整SFT训练集的组成。

不仅是大模型本身,Meta 也要成为 AI 基建大厂。

今年苹果在 AI 上宣布的诸多所谓新功能,例如实时翻译、快捷指令等,并无太多革命性;至于视觉智能 (visual intelligence),不仅功能落后 Google Lens 六七年,交互体验上也远未达到一众 Android 友商的内置 AI/Agent 产品在 2025 上半年水平。

测试时扩展(Test-Time Scaling)极大提升了大语言模型的性能,涌现出了如 OpenAI o 系列模型和 DeepSeek R1 等众多爆款。那么,什么是视觉领域的 test-time scaling?又该如何定义?

辍学MIT创业八年,走上人生巅峰
Scale AI 即将获得 Meta 高达数十亿美元的投资,金额可能超过 100 亿美元,这将成为有史以来规模最大的私营企业融资事件之一。
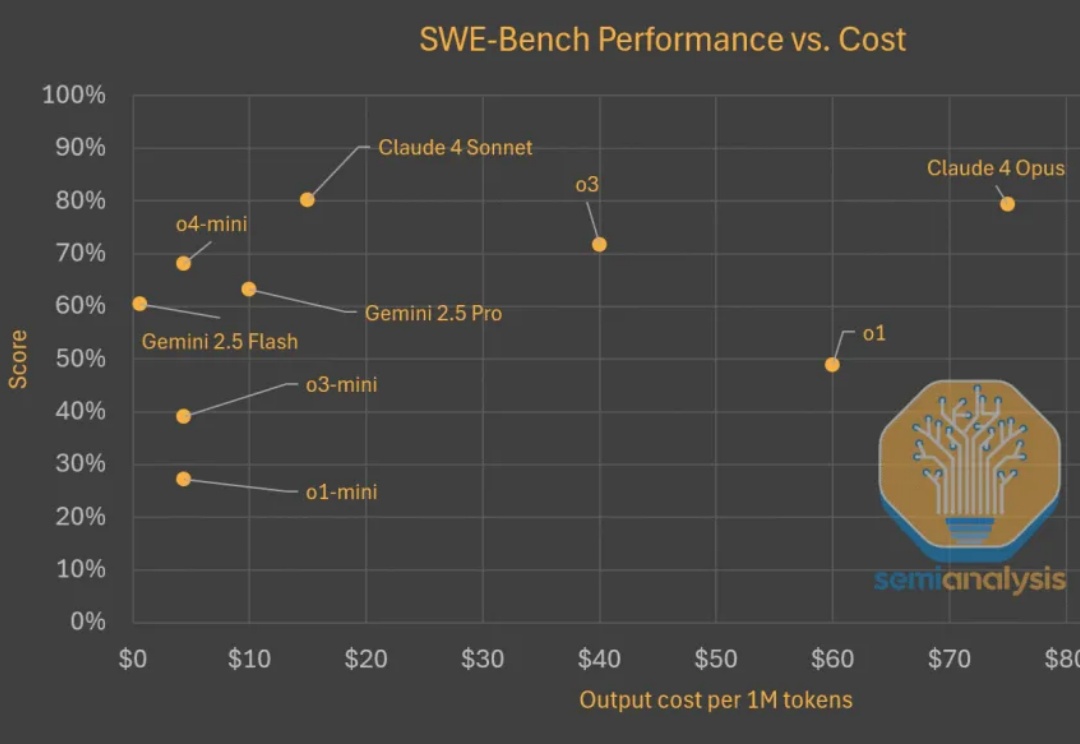
Test time scaling范式蓬勃发展。推理模型持续快速改进,变得更为高效且价格更为亲民。在评估现实世界软件工程任务(如 SWE-Bench)时,模型以更低的成本取得了更高的分数。以下是显示模型变得更便宜且更优秀的图表。

2025 年 6 月 4 日 ——AI 驱动的金融科技公司 Aibidia 宣布完成 2800 万美元 B 轮融资,资金将用于拓展其在美国的税务科技业务。本轮融资由 Activant Capital 领投,老股东 DN Capital、FPV 和 Icebreaker.vc 跟投。

Decoder是由The Verge 主编 Nilay Patel 主持的深度访谈节目。在这一期中,Decoder邀请到了 Runway 联合创始人兼 CEO Cris Valenzuela,一位既是技术推动者,也是理想主义创作者的创业者

马斯克xAI联合Scale AI训练语音模型,提升自然对话与安全管控。6月6日消息,据媒体获取的文件显示,埃隆·马斯克旗下的人工智能公司xAI正利用一系列问题训练其AI语音模型