AI圈水太深:OpenAI保密、Meta作弊!国产MoE却异军突起
AI圈水太深:OpenAI保密、Meta作弊!国产MoE却异军突起从GPT-2到Llama 4,大模型这几年到底「胖」了多少?从百亿级密集参数到稀疏MoE架构,从闭源霸权到开源反击,Meta、OpenAI、Mistral、DeepSeek……群雄割据,谁能称王?
来自主题: AI技术研报
9279 点击 2025-07-16 16:18
 搜索
搜索
从GPT-2到Llama 4,大模型这几年到底「胖」了多少?从百亿级密集参数到稀疏MoE架构,从闭源霸权到开源反击,Meta、OpenAI、Mistral、DeepSeek……群雄割据,谁能称王?
大模型在潜空间中推理,带宽能达到普通(显式)思维链(CoT)的2700多倍?
疯狂,太疯狂了~ 大神卡帕西预测的「下一代GUI系统」这就水灵灵地实现了?!

在5月中旬,谷歌发布了AlphaEvolve。不仅30天内攻克了18年未解的难题,或将开启了一场无需「灵感」的科学革命:未来,科学家将不再依赖直觉,而是靠AI解决难题!

2023年感恩节,OpenAI创始人奥特曼被炒鱿鱼,五天五夜的科技圈大戏席卷全网。亚马逊斥资4000万美元,将这段「AI圈权游」搬上大银幕,Andrew Garfield化身奥特曼,带你重温那场惊心动魄的逆转剧情!

还在质疑AI生物制药「纸上谈兵」?Chai-2已经把抗体设计成功率从0.1%提升到16%,而且还是零样本!不仅是技术奇迹,这更是范式革命:下一代药神,可能不是生物学博士,而是提示词工程师。
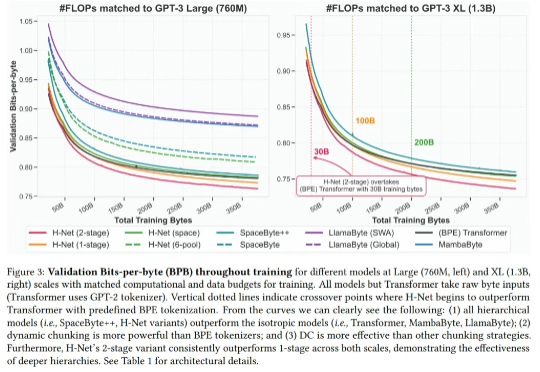
最近,Mamba 作者之一 Albert Gu 又发新研究,他参与的一篇论文《 Dynamic Chunking for End-to-End Hierarchical Sequence Modeling 》提出了一个分层网络 H-Net,其用模型内部的动态分块过程取代 tokenization,从而自动发现和操作有意义的数据单元。
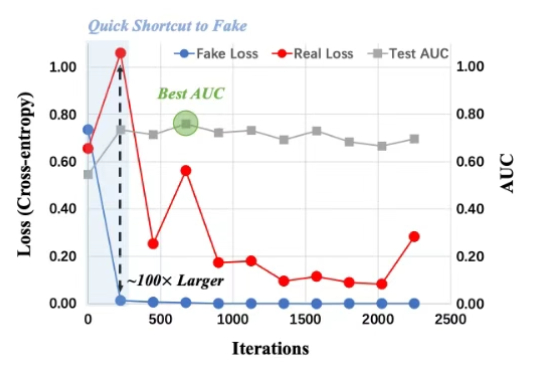
随着 OpenAI 推出 GPT-4o 的图像生成功能,AI 生图能力被拉上了一个新的高度,但你有没有想过,这光鲜亮丽的背后也隐藏着严峻的安全挑战:如何区分生成图像和真实图像?

独家获悉,全球跨境支付与金融平台Airwallex(空中云汇)近日完成3亿美元F轮融资。投资方包括Square Peg、DST Global、Blackbird、Airtree、Salesforce Ventures等风投机构,还有多家养老基金,Visa Ventures作为战略投资者参与。

GPT-4o引爆全球「吉卜力风格」风潮后,其核心成员——华南理工学霸Lu Liu与伯克利博士Allan Jabri——双双跳槽Meta,两人曾在OpenAI主导多模态AI研究,与奥特曼同台展示关键功能。此次挖角再次凸显OpenAI内部动荡后的人才流失危机。