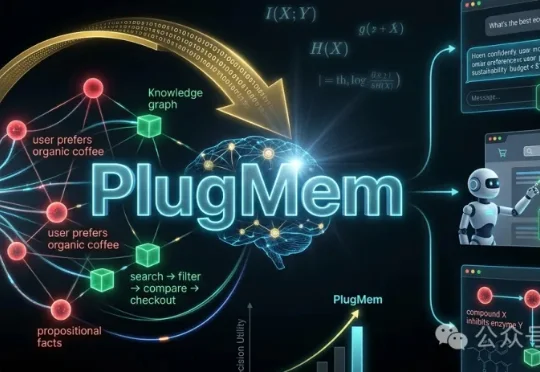
MemoryLake让你养虾省91%词元!AI记忆公司质变科技用1亿个多模态文件验证了!
MemoryLake让你养虾省91%词元!AI记忆公司质变科技用1亿个多模态文件验证了!一家企业花了七周时间部署 AI:第 1 周精准回答行业分析问题,团队欢呼;第 3 周反复回答相同的错误结论,因为它“忘了”上周的修正;第 5 周在董事会汇报中引用了已被否定的数据,造成决策偏差;第 7 周项目暂停,“AI 不可信”成为共识。问题不在于 AI 不够聪明,而在于它每次醒来都是一张白纸。
来自主题: AI资讯
8810 点击 2026-03-25 14:18