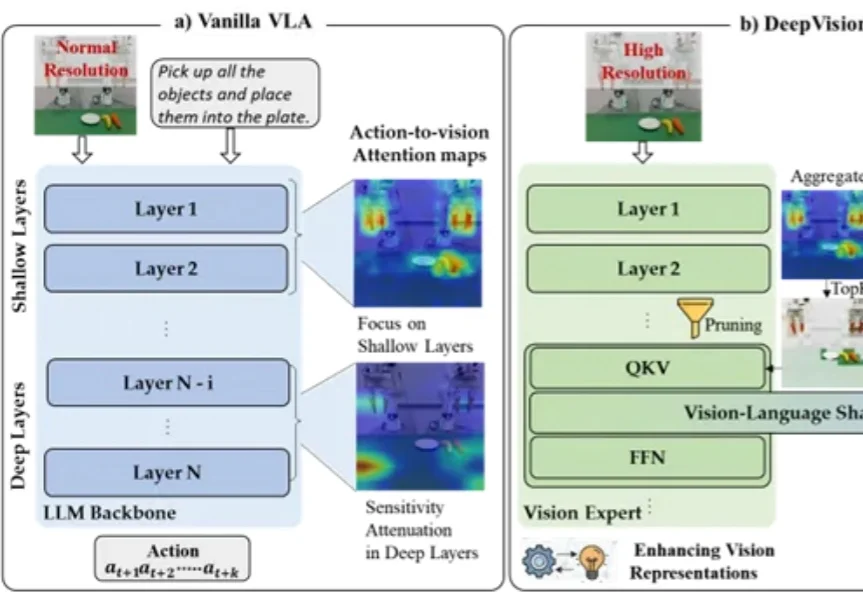
VLA别再「走神」:即插即用提升视觉泛化,相对Pi0.5提升18%
VLA别再「走神」:即插即用提升视觉泛化,相对Pi0.5提升18%“把水果放进盘子里”——机器人看懂了指令,开始执行,却在最后关头抓偏了。
来自主题: AI技术研报
6422 点击 2026-03-26 10:48
 搜索
搜索
“把水果放进盘子里”——机器人看懂了指令,开始执行,却在最后关头抓偏了。

AI视频生成领域或从「技术狂热」回归「商业理性」。

视频编辑应用 Captions 的开发商 Mirage 已从 General Catalyst 的客户价值基金(CVF)筹集了 7500 万美元的增长融资。

近年来,随着 Sora、Seedance 等文本到视频(T2V)扩散模型的飞速发展,AI 视频生成在视觉保真度与动态表现上已取得突破性进展。特别是近期备受瞩目的 Seedance 2.0,展现出了极其强大的多镜头叙事与复杂分镜控制能力。

过去的一两年里,AI生成视频的浪潮几乎席卷了每一个内容平台。

xAI华人高管潮水般离开时,所有人以为它要凉,结果Grok Imagine突然三杀登顶!
3 月 17 日,亚布力论坛年会现场,宇树科技创始人王兴兴被问及中国 AI 进展时,点名表扬了一款国产 AI:「今年一月份字节跳动 Seedance 2.0 视频生成软件,我觉得是全球目前最好的,全球遥遥领先。」
就在刚刚,世界第一个用Seedance 2.0做底层模型的AI短剧Agent,正式上线了。
来自天工AI的SkyReels-V4,没打招呼,直接登顶Artificial Analysis文转视频(含音频)全球榜,超越Veo 3.1、Sora 2。一个月前,其Preview版本才刚拿下该榜全球第2。

我昨天发了一篇文章,中间有一个观点。 就是AI时代,你的产品,可能得同时为了人类和Agent共同设计。