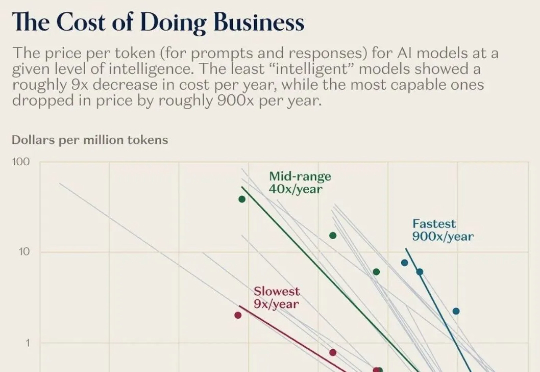
AI跌价900倍,连一瓶矿泉水都比它贵!
AI跌价900倍,连一瓶矿泉水都比它贵!过去一年,AI模型的价格暴跌百倍!同样一句话,去年要10块,现在只要几分钱。可与此同时,家政、育儿、心理咨询、维修.....这些「手工活」越来越贵。科技正在疯狂通缩,生活却越来越通胀。这不是经济学笑话,而是Jevons与Baumol共同制造的现实:当机器更聪明,人工就更昂贵。
来自主题: AI资讯
9610 点击 2025-11-06 09:43
 搜索
搜索
过去一年,AI模型的价格暴跌百倍!同样一句话,去年要10块,现在只要几分钱。可与此同时,家政、育儿、心理咨询、维修.....这些「手工活」越来越贵。科技正在疯狂通缩,生活却越来越通胀。这不是经济学笑话,而是Jevons与Baumol共同制造的现实:当机器更聪明,人工就更昂贵。
是孩子该看的东西。
用外卖的打法做AI模型?美团这是跟“又快又稳”杠上了(doge)。

当AI模型排行榜开始被各种刷分作弊之后,谁家大模型最牛这个问题就变得非常主观,直到一家线上排行榜诞生,它叫:LMArena。在文字、视觉、搜索、文生图、文生视频等不同的AI大模型细分领域,LMArena上每天都有上千场的实时对战,由普通用户来匿名投票选出哪一方的回答更好。
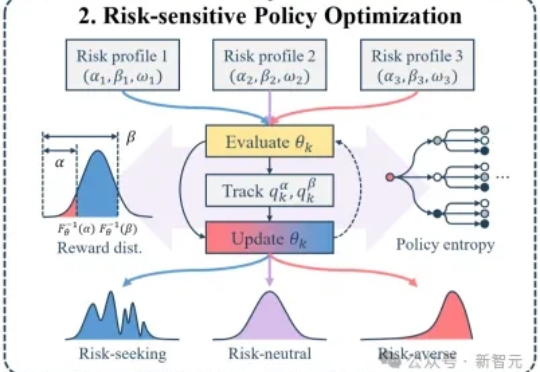
大模型后训练的痛点:均值优化忽略低概率高信息路径,导致推理能力停滞。RiskPO双管齐下,MVaR目标函数推导梯度估计,多问题捆绑转化反馈,实验中Geo3K准确率54.5%,LiveCodeBench Pass@1提升1%,泛化能力强悍。

香港科技大学KnowComp实验室提出基于《欧盟人工智能法案》和《GDPR》的LLM安全新范式,构建合规测试基准并训练出性能优异的推理模型,为大语言模型安全管理提供了新方向。
在 iPhone 上部署端侧 AI 模型,成了互联网的新显学。在 iPhone 上体验端侧模型,门槛其实不算高。打开 App Store,搜索 PocketPal AI,下载安装。如果不习惯英文界面,可以在设置 (Setting) 里找到语言 (Language) 选项,切换成中文。

AI模型是现在,Physical AI是未来
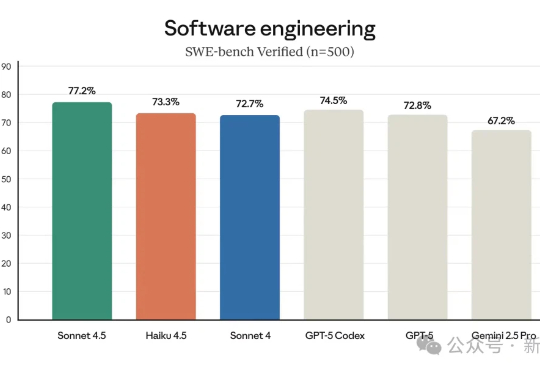
Anthropic用Haiku 4.5打响了AI性价比之战!曾经的顶配性能,如今以三分之一的价格、两倍的速度下放,可以说是对高价AI模型的一次降维打击。

奥特曼亲自飞赴首尔,与韩国总统、两大财阀巨头会晤并达成合作。三星电子与SK海力士将加速生产先进存储芯片,目标月产能达90万片DRAM晶圆,以满足OpenAI模型的需求。随着奥特曼逐渐握紧硬件的咽喉,留给竞争对手的时间,不多了。