
与AI共舞,RISC-V芯片加速落地生根
与AI共舞,RISC-V芯片加速落地生根自计算机诞生以来,指令集架构一直是计算机体系结构中的核心概念之一。目前市场上主流的指令集架构两大巨头是x86和ARM,前者基本垄断了PC、笔记本电脑和服务器领域,后者则在智能手机和移动终端市场占据主导地位。
来自主题: AI技术研报
6360 点击 2024-05-11 11:08
 搜索
搜索
自计算机诞生以来,指令集架构一直是计算机体系结构中的核心概念之一。目前市场上主流的指令集架构两大巨头是x86和ARM,前者基本垄断了PC、笔记本电脑和服务器领域,后者则在智能手机和移动终端市场占据主导地位。
多层感知器(MLP),也被称为全连接前馈神经网络,是当今深度学习模型的基础构建块。MLP 的重要性无论怎样强调都不为过,因为它们是机器学习中用于逼近非线性函数的默认方法。
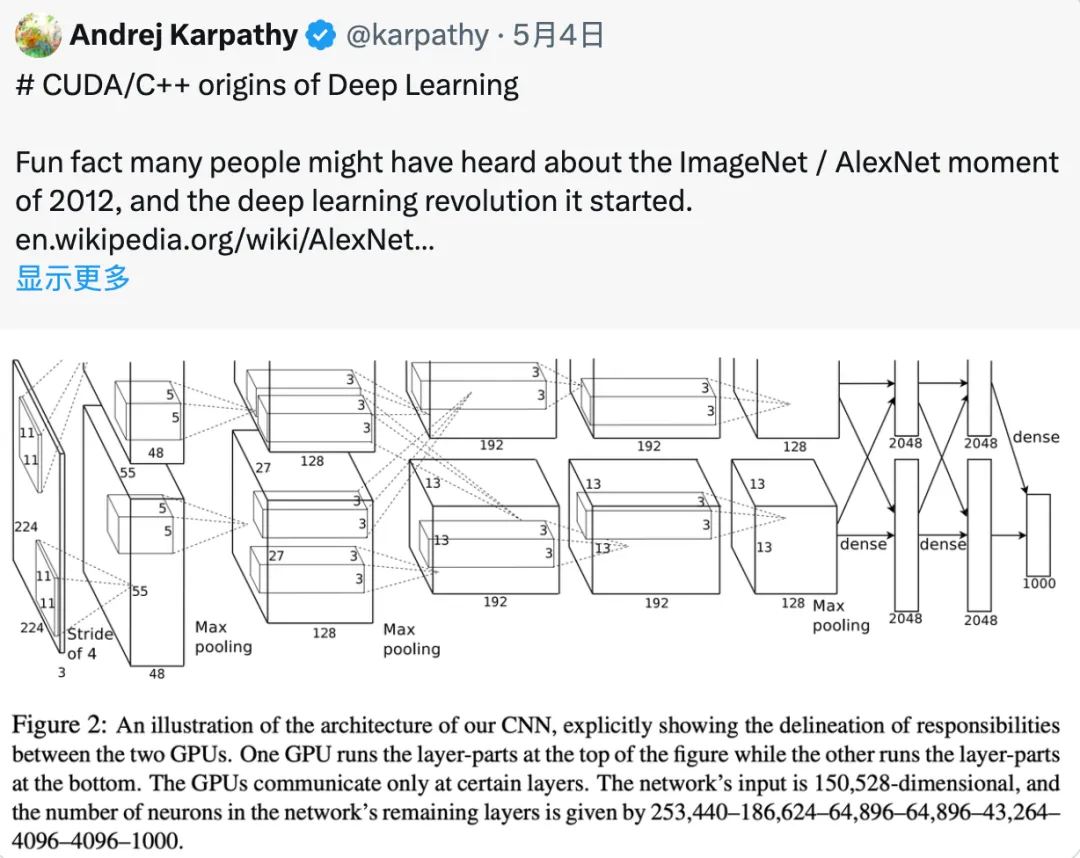
没想到,自 2012 年 AlexNet 开启的深度学习革命已经过去了 12 年。

机器如何能像人类和动物一样高效地学习?机器如何学习世界运作方式并获得常识?机器如何学习推理和规划……

使用测序 (scATAC-seq) 技术对转座酶可及的染色质进行单细胞测定,可在单细胞分辨率下深入了解基因调控和表观遗传异质性,但由于数据的高维性和极度稀疏性,scATAC-seq 的细胞注释仍然具有挑战性。现有的细胞注释方法大多集中在细胞峰矩阵上,而没有充分利用底层的基因组序列。
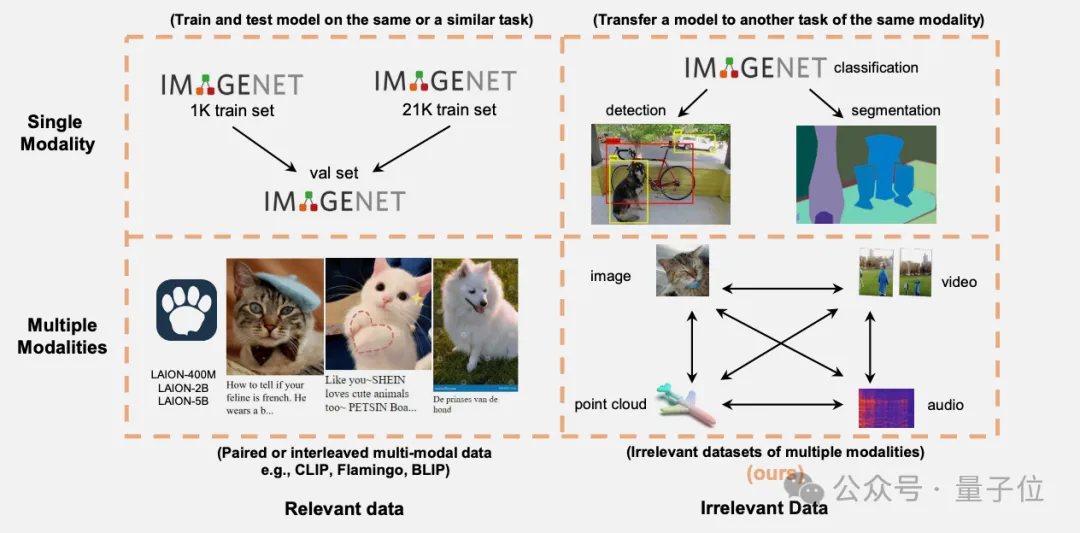
万万没想到,与任务无直接关联的多模态数据也能提升Transformer模型性能。

探索视频理解的新境界,Mamba 模型引领计算机视觉研究新潮流!传统架构的局限已被打破,状态空间模型 Mamba 以其在长序列处理上的独特优势,为视频理解领域带来了革命性的变革。

想象一下,你仅需要输入一段简单的文本描述,就可以生成对应的 3D 数字人动画的骨骼动作。而以往,这通常需要昂贵的动作捕捉设备或是专业的动画师逐帧绘制。这些骨骼动作可以进一步的用于游戏开发,影视制作,或者虚拟现实应用。来自阿尔伯塔大学的研究团队提出的新一代 Text2Motion 框架,MoMask,正在让这一切变得可能。

抛弃传统方法,只采用Transformer来解码真实场景!

在人物说话的过程中,每一个细微的动作和表情都可以表达情感,都能向观众传达出无声的信息,也是影响生成结果真实性的关键因素。