
Agent 刚拿到自己的邮箱和钱包,人类的收件箱已经挤爆了
Agent 刚拿到自己的邮箱和钱包,人类的收件箱已经挤爆了Agent 正在逐渐获得「人权」。
来自主题: AI资讯
6913 点击 2026-06-30 10:45
 搜索
搜索
Agent 正在逐渐获得「人权」。
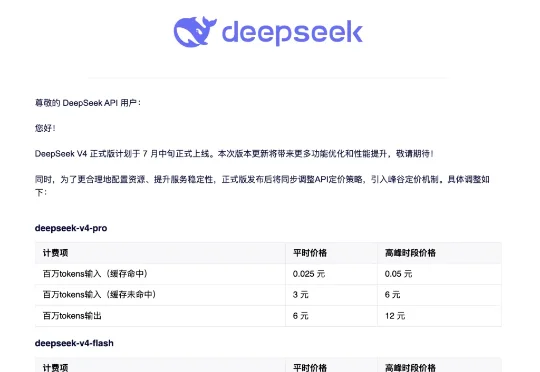
记者获悉,DeepSeek宣布价格调整,引入峰谷计费机制:以DeepSeek-v4-pro为例,其输入价格(缓存命中)平时为0.025元/百万tokens,高峰时期为0.05元/百万tokens;输入价格(缓存未命中)平时为3元/百万tokens,高峰时期为6元/百万tokens;输出价格平时为6元/百万tokens,高峰时期为12元/百万tokens。

Z Potentials独家获悉,柔性具身智能公司深圳擎羽科技有限公司(以下简称:擎羽科技)已完成 Pre-A 轮融资。本轮融资由顺为资本、五源资本联合投资,高鹄资本担任独家财务顾问。这也是继德迅投资、东方富海等一线机构相继出手后,擎羽科技在半年内完成的第三轮融资。

6月22日Claude全家桶集体宕机,只是冰山一角。当最强大模型被丢进真实机房直面「幽灵故障」,AISHPerf-智算运维智能体评测基准给出残酷答案:全军覆没,无一过50分。这道鸿沟,第一次被量化。
周末跟几个之前的老朋友吃饭。 大家也都不由自主的聊到了AI,然后也聊到了Vibe Coding。

2026 年 6 月,大模型行业正在经历一场前所未有的「开源海啸」:英伟达放出了 550B 参数的混合架构模型,谷歌送出多模态的 Gemma 新版本,智谱用最宽松的协议全量开源了自家旗舰模型。

2026年,具身智能迎来融资狂潮。
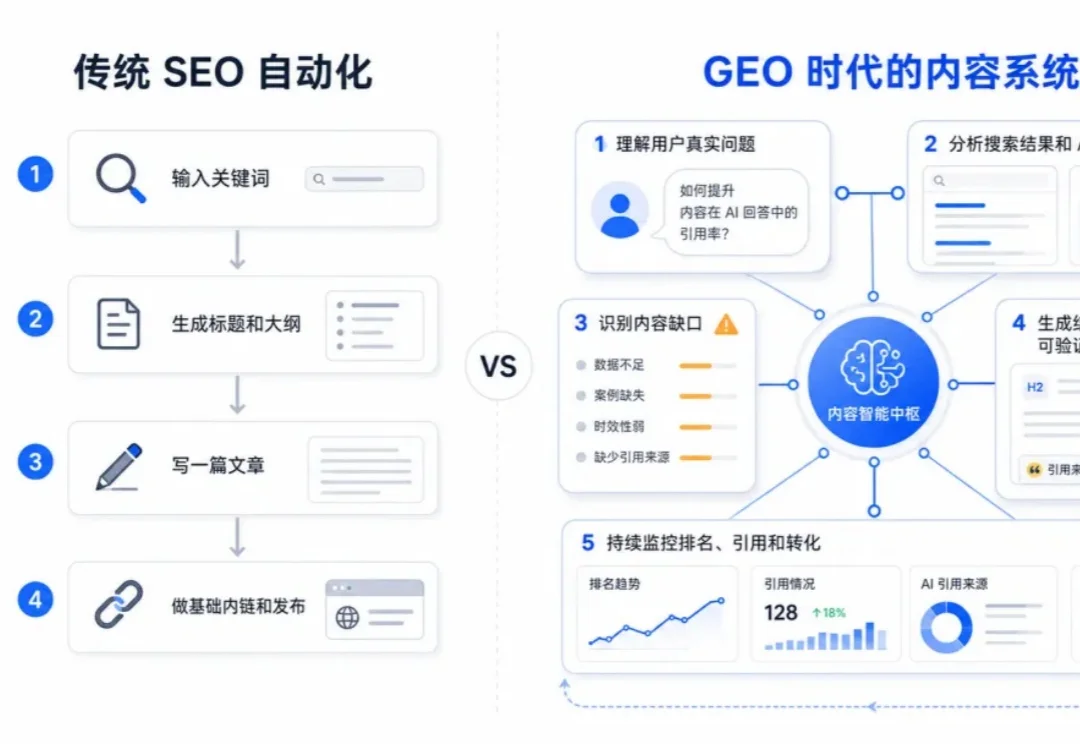
最近,有很多朋友来请教我们一个问题,GEO到底要怎么做,才能让生成的内容质量更高。

独家获悉,清华系初创公司「厘清智能」宣布完成数亿元种子轮融资,投资方阵容堪称豪华:由顺为资本、红杉中国、高瓴创投、峰瑞资本、星连资本、水木清华校友种子基金、SEE FUND等一线基金,与智元机器人、灵心巧手、世纪金源等产业资本共同投资。其中,顺为资本与红杉中国更是连续多轮追加投资。
Patronus AI 今天官方宣布公司完成由 Greenfield Partners 领投的 5000 万美元 B 轮融资,Lightspeed Venture Partners、Notable Capital、Datadog、三星、Gokul Rajaram、Factorial Capital 以及来自我们实验室和新实验室的众多人工智能领军人物也参与了本轮融资。