
AI吞数据,谁买单?
AI吞数据,谁买单?企业在AI数据竞赛中面临数据抓取挑战,聚合器通过网页抓取或用户同意绕过限制,导致控制丧失、安全风险和品牌侵蚀。解决方案包括强化合同条款、API协议控制、数据泄露防护和主动维权,如Reddit诉Anthropic案启示合同作为AI数据管理框架。
来自主题: AI监管政策
10590 点击 2025-08-21 14:00
 搜索
搜索
企业在AI数据竞赛中面临数据抓取挑战,聚合器通过网页抓取或用户同意绕过限制,导致控制丧失、安全风险和品牌侵蚀。解决方案包括强化合同条款、API协议控制、数据泄露防护和主动维权,如Reddit诉Anthropic案启示合同作为AI数据管理框架。
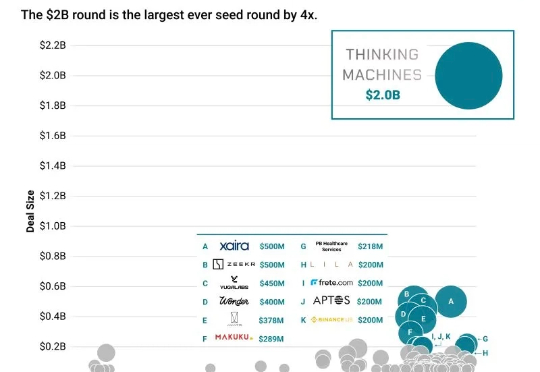
硅谷各个模型公司在这个季度,开始分化到各个领域,除了 Google Gemini 和 OpenAI 还在做通用的模型;Anthropic 分化到 Coding、Agentic 的模型能力;Mira 的 Thinking Machines Lab 分化到多模态和下一代交互。
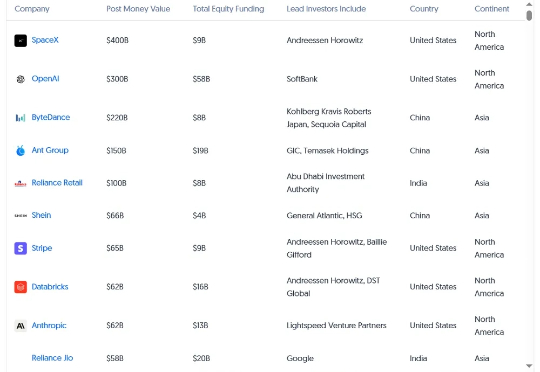
智东西8月20日报道,昨日,AI数据分析平台Databricks宣布,该公司已经签署了K轮融资的条款清单,预计将在现有投资者的支持下很快完成,这轮融资对Databricks的估值已经超过了1000亿美元(约合人民币7179.1亿元),估值与8个月前的620亿美元(约合人民币4451.0亿元)相比,上涨了超61%。

在生成式 AI 时代,全球数据总量正以惊人速度增长,据 IDC 预测,2025 年将突破 180ZB,其中 80% 为非结构化内容,传统数据分析在应对多模态信息和打破结构化数据技术壁垒方面尽显乏力,“人工找数 + 手动分析” 的模式严重抑制甚至沉没了数据价值。
年初,DeepSeek 前脚带来模型在推理能力上的大幅提升,Manus 后脚就在全球范围内描绘了一幅通用 Agent 的蓝图。新的范本里,Agent 不再止步于答疑解惑的「镶边」角色,开始变得主动,拆解分析需求、调用工具、执行任务,最终解决问题……

近年来,AI社交赛道作为一个快速崛起的“品种”,曾凭借玩法新颖与技术想象力迅速吸引了市场关注。然而,随着入局者增加,赛道逐渐暴露出增长瓶颈:玩法趋于固化、功能高度同质化、用户体验缺乏持续吸引力。种种迹象都在指向一个信号:市场正在走向降温与饱和。

QuestMobile 发布了 2025 年国内 AI 应用的上半年报告,总的来说,相比海外市场 app 和 web 市场都很火热的情况,国内市场的情况差别比较大。

AI行业对数据的渴求程度,质量大于数量。

最近在看中国出海的 AI 应用,看到一篇风投公司 A16Z 发布的报告,觉得很有意思,梳理一下分享给大家。结尾点击阅读全文可以跳转到原文。
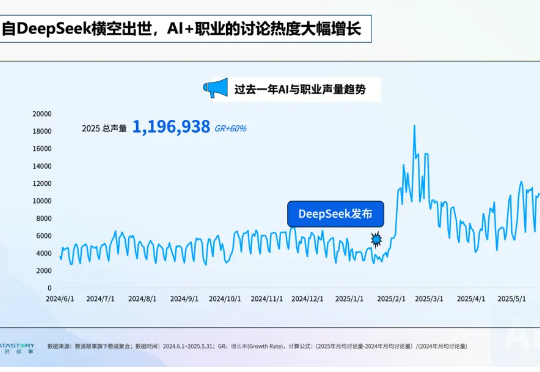
ShowMeAI 参与了腾讯新闻热问年中《DeepSeek半年之后》专题策划,回顾上半年 AI 发展以及对多个行业的影响。