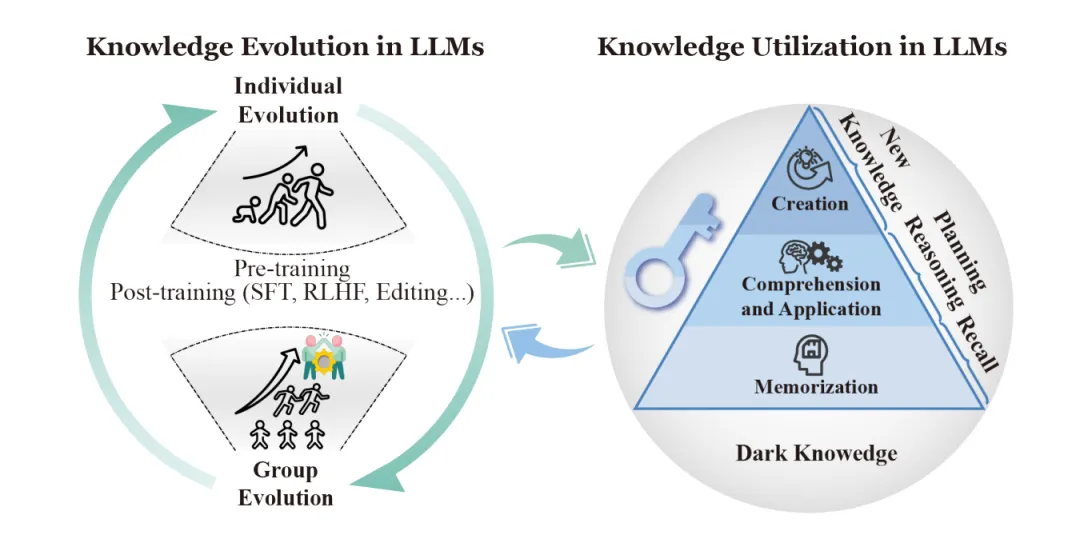
34页,超200篇文献,浙江大学最新综述,揭秘大语言模型中知识的利用机制
34页,超200篇文献,浙江大学最新综述,揭秘大语言模型中知识的利用机制ChatGPT的出现引发了一场AI革命,它展示了通过简单对话就能完成各种任务的强大能力,并且将不同的 AI 功能整合到一个统一的平台上。还记得小编第一次使用 ChatGPT 的时候给我带来极大震撼。
来自主题: AI技术研报
9060 点击 2024-09-04 09:25
 搜索
搜索
ChatGPT的出现引发了一场AI革命,它展示了通过简单对话就能完成各种任务的强大能力,并且将不同的 AI 功能整合到一个统一的平台上。还记得小编第一次使用 ChatGPT 的时候给我带来极大震撼。

涉足各个领域的知识工作,是这波 AI 最大的一个特点,编程、法律、会计等领域都涌现出了大量优秀的 AI 产品。而在相对专业的学术领域,也正呈现出 AI 的巨大价值。

罗盟,本工作的第一作者。新加坡国立大学(NUS)人工智能专业准博士生,本科毕业于武汉大学。主要研究方向为多模态大语言模型和 Social AI、Human-eccentric AI。

人工神经网络、深度学习方法和反向传播算法构成了现代机器学习和人工智能的基础。但现有方法往往是一个阶段更新网络权重,另一个阶段在使用或评估网络时权重保持不变。这与许多需要持续学习的应用程序形成鲜明对比。

今天,KDD 2024大奖结果新鲜出炉!华人学者收获颇丰,浙大校友Jundong Li获新星奖,博士论文奖的冠亚军均有华人学者上榜。

ACM SIGKDD(国际数据挖掘与知识发现大会,KDD) 会议始于 1989 年,是数据挖掘领域历史最悠久、规模最大的国际顶级学术会议,也是首个引入大数据、数据科学、预测分析、众包等概念的会议。

本文对AI增强的VR在医疗应用中的技术细节、工作流程和下游应用进行了全面审视,并提出了一个系统性的分类方法,将相关工作分为医学视觉增强、VR医学数据处理和VR辅助干预三个主要类别,为未来跨学科研究提供了基础。
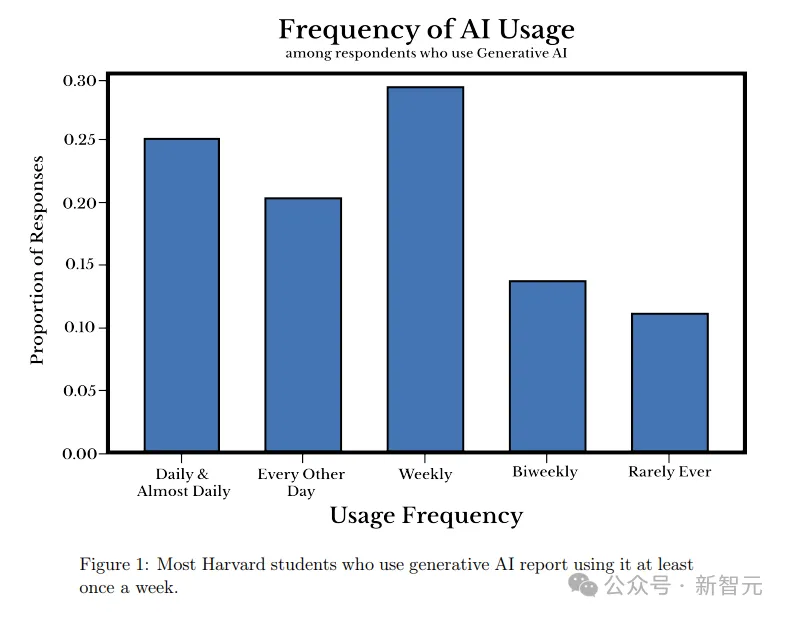
哈佛大学的一项最新研究表明,大语言模型已经深入学生的日常生活。为何学生们对AI的兴趣如此浓厚,背后的原因恐怕是这所大学的教授们。

这篇文章对如何进行领域模型训练进行一个简单的探讨,主要内容是对 post-pretrain 阶段进行分析,后续的 Alignment 阶段就先不提了,注意好老生常谈的“数据质量”和“数据多样性”即可。

神经网络是一种灵活且强大的函数近似方法。而许多应用都需要学习一个相对于某种对称性不变或等变的函数。图像识别便是一个典型示例 —— 当图像发生平移时,情况不会发生变化。等变神经网络(equivariant neural network)可为学习这些不变或等变函数提供一个灵活的框架。