企业养虾时代开启?Anthropic连夜更新架构,中国大厂已经跑通
企业养虾时代开启?Anthropic连夜更新架构,中国大厂已经跑通代码成本趋近于零,产品护城河正在消失。AI下半场,真正决定胜负的,是那套让上万只虾同时稳稳干活的「养虾厂」。
来自主题: AI资讯
8614 点击 2026-05-23 09:59
 搜索
搜索
代码成本趋近于零,产品护城河正在消失。AI下半场,真正决定胜负的,是那套让上万只虾同时稳稳干活的「养虾厂」。
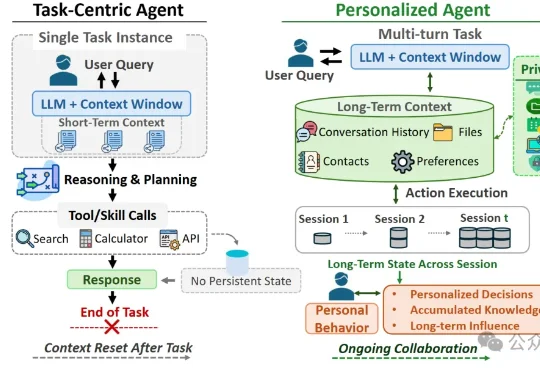
日常聊天可能在不经意间污染个性化Agent的长期记忆,使其在未来任务中偏离用户真实意图。研究人员通过ULSPB基准测试发现,即使无恶意提示,日常对话也可能改变Agent的安全边界。

重庆一家科技公司就推出了一个起床神器:「Sunflower X AI唤醒灯」。在现代社会,手机闹钟几乎零成本,但一盏功能类似的台灯,却要319美元(约合人民币2168元),而这还是他们在Kickstarter上的早鸟价。
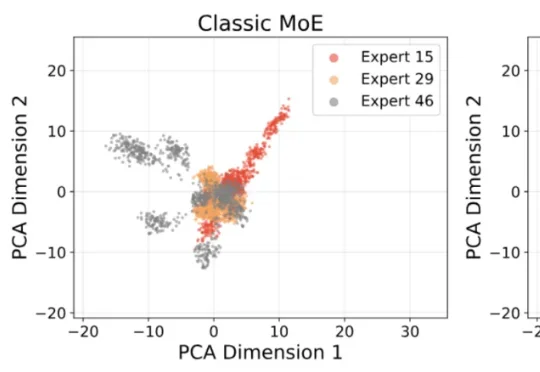
近年来,Mixture-of-Experts(MoE)已经成为大模型扩展的重要架构之一。相比稠密 Transformer,MoE 通过稀疏激活机制,在每个 token 上只调用少量专家,从而在控制计算成本的同时扩大模型容量。然而,一个长期存在的问题是:专家越多,并不意味着专家真的学得越 “专”。

Jim Fan 押注的这条 “先预测世界,再生成动作” 的新路,正是当下具身智能领域最炙手可热的下一代范式 —— 世界动作模型(World Action Models,简称 WAM)。虽然 WAM 正在迅速成为各大顶尖实验室的核心发力点,但业界至今仍然缺乏对它的统一标准和系统梳理。近期,复旦大学可信具身智能研究院,上海创智学院,新加坡国立大学发表了首篇 WAM 的详细综述。
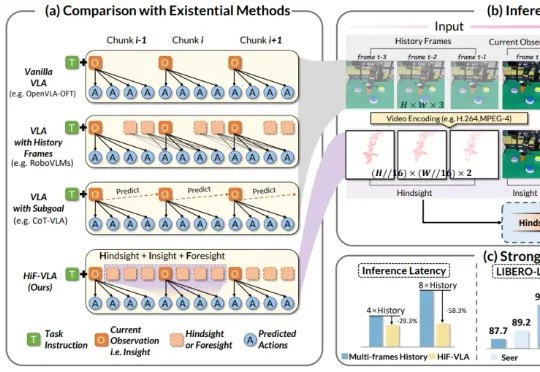
来自西湖大学、浙江大学、西湖机器人等机构的研究团队提出了一种以运动(Motion)为中心的全新双向时空推理框架 HiF-VLA。抛弃冗余的像素级输入,HiF-VLA 巧妙提取低维紧凑的 Motion 向量作为动态先验,在一个创新的「联合专家」模块中,同步完成未来视觉运动的预测与高精度动作序列的生成。

说实话,我原本以为 DeepSeek 的限时优惠会在5月31日结束。毕竟降价75%,打了2.5折,怎么看都像是一波限时引流。5月22号晚上,DeepSeek发了个通知,我看了两遍才确认没看错——DeepSeek V4-Pro永久降价!

今天,百川智能发布了AI家庭医生产品“百小医”,并展示了即将发布的百川新一代医疗大模型Baichuan-M4。“百小医”目前已经上线各大应用市场,而Baichuan-M4会在下个月开放API服务。
就在今天,美团龙猫大模型团队突然开源了商用级数字人视频生成模型 LongCat-Video-Avatar 1.5。在权威评测中,它的用户偏好胜率全面超越 Kling Avatar 2.0、OmniHuman-1.5 和 HeyGen 这三个头部玩家,并且直接以 MIT 协议开放,连商用限制都懒得设。

刚刚,Cohere放出2180亿参数的MoE大模型Command A+,单张B200可跑,支持48种语言,还带原生引用能力。但这次发布最炸的,不在参数表上,而在那一个许可证:Apache 2.0。