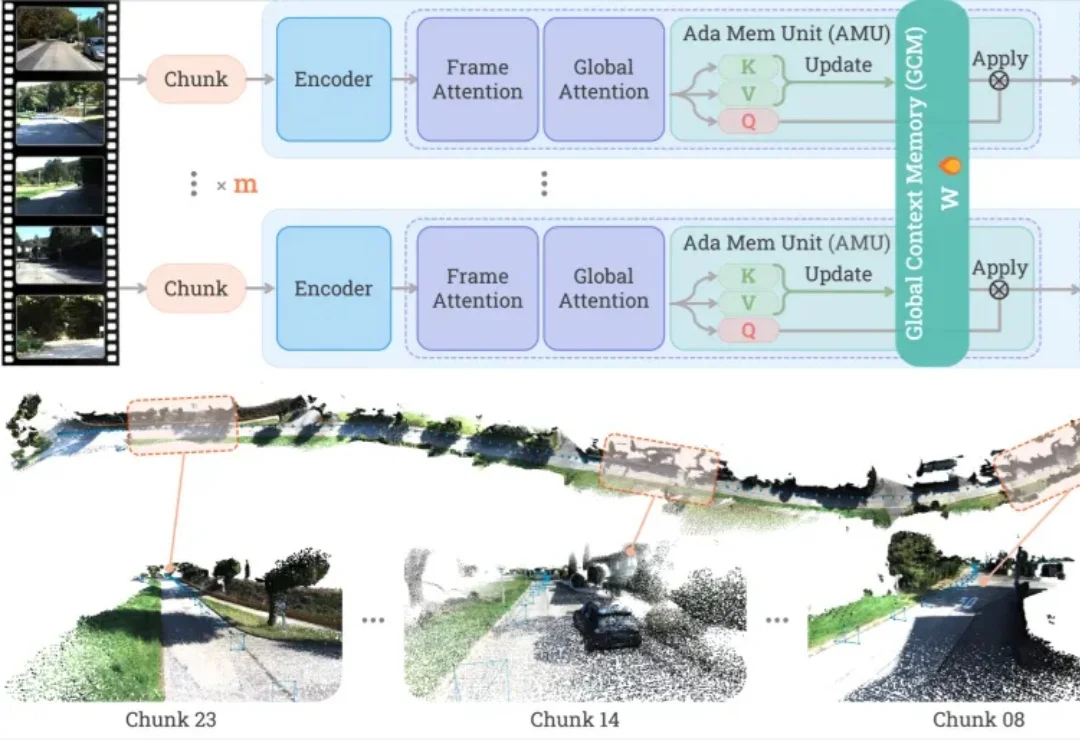
Anthropic一发布Multica就开源,这个4人团队想抢占AI协作层
Anthropic一发布Multica就开源,这个4人团队想抢占AI协作层4 月 9 日,Anthropic 在 X 上宣布 Claude Managed Agents 上线。同一天,一位 ID 叫 @jiayuan_jy 的中国创业者也发了一条推,“We created the open source version of Claude Managed Agents. Introducing Multica.”
来自主题: AI资讯
6144 点击 2026-05-06 14:56