首发| 阿里大牛融资:AI新物种诞生了
首发| 阿里大牛融资:AI新物种诞生了“消除人类无聊工作”。
来自主题: AI资讯
5614 点击 2026-05-21 10:14
 搜索
搜索
“消除人类无聊工作”。
让 AI 来管理代码的话,每次读 500 行反而比读 1000 行更费 Token,而且人工编排流程真不如让大模型自己定,「很多的事儿,还是很反直觉的」

OpenAI又双叒搞数学了。

Agent不再只住在云端——联想携手此芯科技,把190 TOPS本地AI算力装进手掌大小的AI主机,让每个人都能拥有一座7×24小时运行的私人Token工厂。
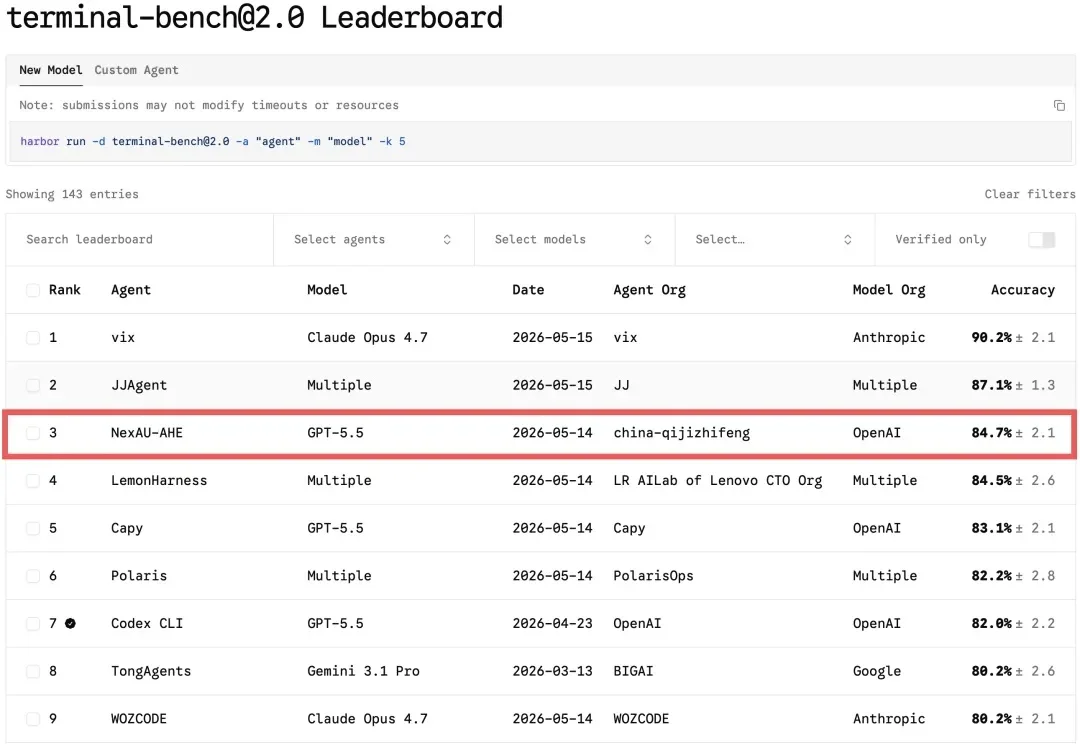
2026 年以来,OpenAI、Anthropic、LangChain 等机构纷纷发布关于 Harness Engineering 的技术博客,OpenClaw、Hermes Agent 等项目的火爆更让 Harness Engineering 成为业界热词。人们的共识正在形成:模型的能力释放,依赖于一套精密的外部框架。

智联招聘《2025雇佣关系趋势报告》显示,高达78.2%的职场人每周都会借助AI开展工作;另一份调研则指出,近五成职场人在过去一年被要求提升AI使用能力。

那天晚上,《潘神的迷宫》二十周年4K修复版刚放映结束。灯光亮起,大导演德尔·托罗走上台,直接对着麦克风大喊一句:Fuck AI.

央视近日报道,部分电商平台的评论区里,大量AI生成的精美“买家秀”正在取代真实的用户实拍。社交媒体上,不少消费者也在吐槽类似的经历,有些网店里从商品展示图到商品评价里的买家秀,都是由AI生成,仿佛进入一个“楚门的商铺”。

数据标注正成为一项更有技术含量的工作。

过去AI视频是「生成内容」,Omni直接升级成「生成世界」。它懂动能、重力、因果,还能把复杂概念瞬间可视化。人类距离「言出法随」的梦想,还剩几个Gemini Omni的距离?