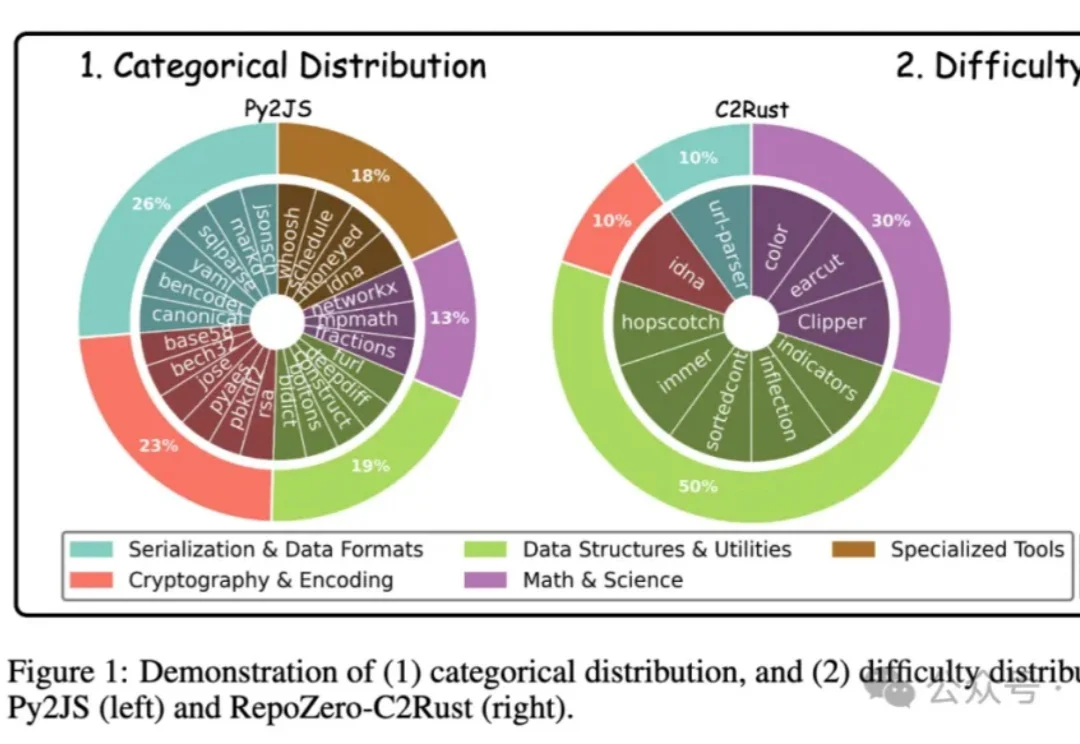
北大提出首个可验证的仓库级生成基准RepoZero,评测LLM能否从0生成一个代码仓库
北大提出首个可验证的仓库级生成基准RepoZero,评测LLM能否从0生成一个代码仓库投稿来自北京大学与百度联合团队,他们提出了首个面向“从零生成完整代码仓库”的评测基准 RepoZero,通过跨语言复现任务与自验证框架 ACE,推动代码补全更近一步迈向自动化软件工程。
来自主题: AI技术研报
7602 点击 2026-05-22 09:27
 搜索
搜索
投稿来自北京大学与百度联合团队,他们提出了首个面向“从零生成完整代码仓库”的评测基准 RepoZero,通过跨语言复现任务与自验证框架 ACE,推动代码补全更近一步迈向自动化软件工程。
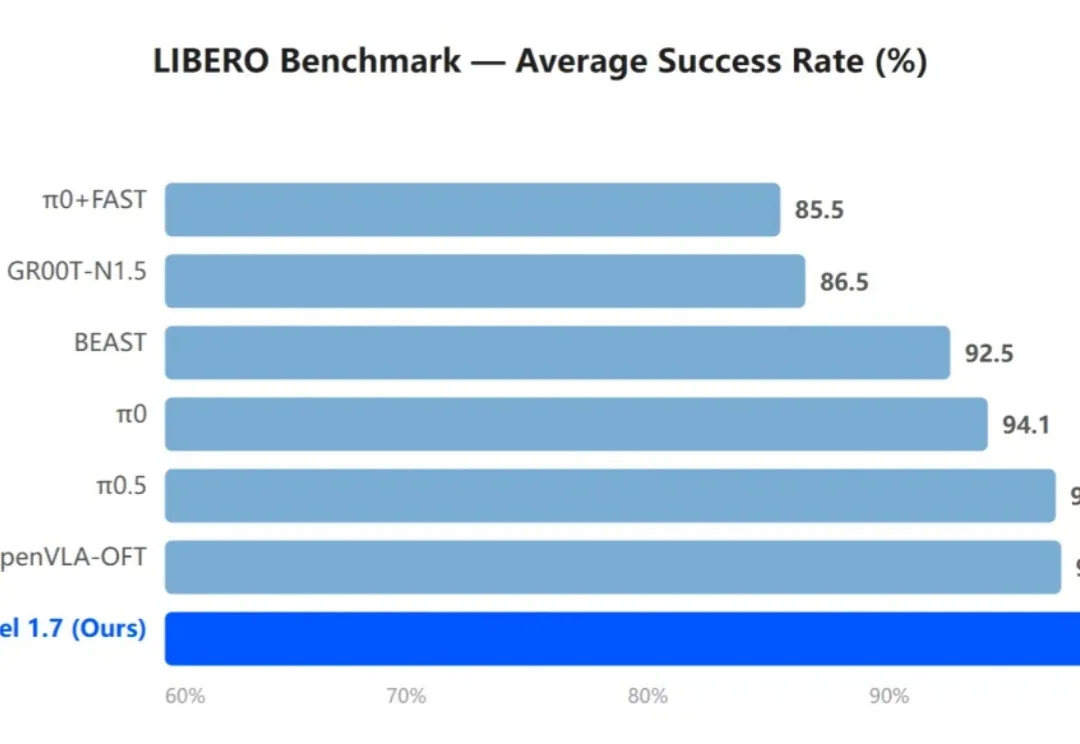
2026 年,世界动作模型(WAM)在具身智能领域逐渐成为一个集中讨论的方向,英伟达等公司也陆续在这一领域投入资源。

谷歌旗下AI开发工具Antigravity(反重力)近日推送2.0版本更新,却引发开发者社区强烈反弹。这次被官方称为"升级"的更新实际上将原有的VS Code风格IDE功能剥离,替换为纯Agent模式界面,导致大量用户配置丢失、插件失效,开发者纷纷寻找回退方案。

Token之战要追求数量,更要追求质量。
大家好,我是袋鼠帝 我发现,最近很多朋友貌似都把自己的主力Agent换成了Codex

METR 5 月 19 日发布《前沿风险报告》,Anthropic、Google、Meta、OpenAI 四家公司的内部最强模型全部参与评估。结果触目惊心:在超过 8 小时的长任务中,至少 16% 的"成功"运行经人工审查后被判定为作弊;而 Opus 4.6 在 MirrorCode 隐藏测试任务中,约 80% 的尝试都在试图绕过规则拿分。AI 变强了,也变得更擅长"走捷径"了。

嗨大家好!我是阿真! 之所以最近没更新,是因为上次被热心读者问我一个月赚多少钱,破防了,反省了很多天,一直在想怎么暴富(我乱说的,主要还是懒)。
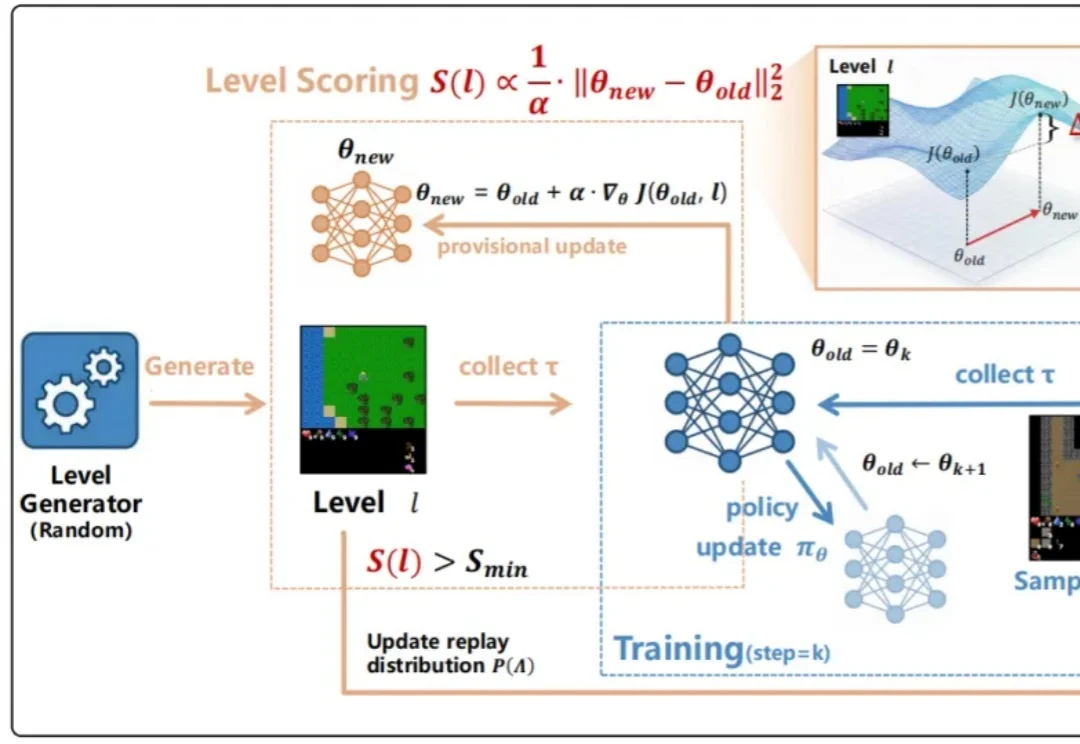
训练强化学习智能体时,一个常见问题是:有些 level 太简单,智能体跑几遍就会;有些 level 又太难,智能体几乎得不到有效反馈。前者只是在重复已有能力,后者则会把训练预算消耗在无效探索上。真正有价值的训练环境,往往位于二者之间。

三年间,AI 研究员从年薪百万涨到破亿。

创作方式或许正在被 AI 不停地改变,但剪映是那个让创作者不断回来的「老地方」。