
「马嘉祺」让大模型翻车,而他一年前洗澡时就发现了问题
「马嘉祺」让大模型翻车,而他一年前洗澡时就发现了问题一家名为脸谱心智(FaceMind)的初创公司就在顶级学术会议 EMNLP 主会上系统性地揭示了这个问题,并给出了解法。更有意思的是,就在「马嘉祺」事件前不到两周,全球最强 AI 公司之一 Anthropic 也在自家产品中悄悄落地了一次高度相关的改造 —— 方向与脸谱心智一年前的论文几乎完全一致。
来自主题: AI技术研报
7651 点击 2026-05-30 10:05
 搜索
搜索
一家名为脸谱心智(FaceMind)的初创公司就在顶级学术会议 EMNLP 主会上系统性地揭示了这个问题,并给出了解法。更有意思的是,就在「马嘉祺」事件前不到两周,全球最强 AI 公司之一 Anthropic 也在自家产品中悄悄落地了一次高度相关的改造 —— 方向与脸谱心智一年前的论文几乎完全一致。
不用JAX,SpaceX正在用C语言编写的全新堆栈训练新模型。而且马斯克本人亲口承认,Grok 5已经用的就是这个新堆栈。按马斯克的说法,这种新堆栈能让大模型训练速度提升一个数量级。

当对话型 AI 服务于数十亿用户时,我们能否看见用户没说出口的那一层?JHU、MIT 和 Google Research 给出了新的解法。

GPT-5.5被扒出「假思考」,用两小时就被偷偷换成mini,200美元月费买了个「薛定谔的脑子」。Trace命令实锤,官方文档亲自认领。往后有纷纷吐槽:OpenAI,你糊弄谁呢?
SpaceX 2025 年全年营收是187 亿美元。这是这家火箭公司用了 23 年积累下来的成果——从 2002 年创立,到把猎鹰 9 号变成最可靠的运载火箭,再到星链卫星互联网,23 年换来的年收入数字。然后 Anthropic 来了一份合同:每年 150 亿美元。

Ashpreet 现在是 Agno 的创始人,以前在 Airbnb、Facebook 做过工程。Scout 是 Agno 新推出的开源项目,定位是「上下文智能体」——一个能在 Slack、Google Drive、Linear 里自由穿梭、替你把碎片化知识拼起来的 AI Agent。

Bloomberg曝光的一份xAI内部组织架构图显示,19人的管理、产品、工程三层架构里,几乎全是马斯克的老部下:SpaceX总裁、Starlink五年老兵、家族办公室总管、Tesla AI工程负责人逐一就位。

腾讯科技、 SkillHub与腾讯玄武实验室联合发布 TRACE 严选框架,为快速增长但缺乏统一标准的 AI Skill 市场建立一套可参照的评测体系。它是一个包含安全扫描、no-skill对照实验、证据包审计、触发率测试、资源代价评估的系统性严选框架,也是国内首个面向Skill真实使用场景的严选评测体系。
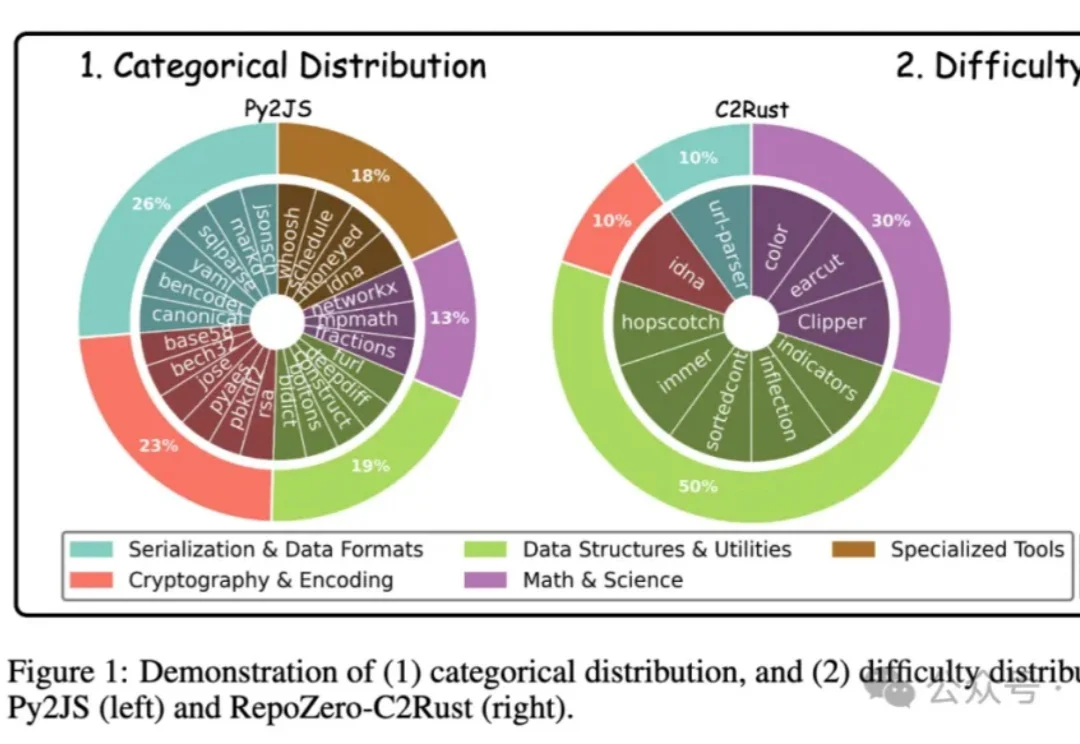
投稿来自北京大学与百度联合团队,他们提出了首个面向“从零生成完整代码仓库”的评测基准 RepoZero,通过跨语言复现任务与自验证框架 ACE,推动代码补全更近一步迈向自动化软件工程。
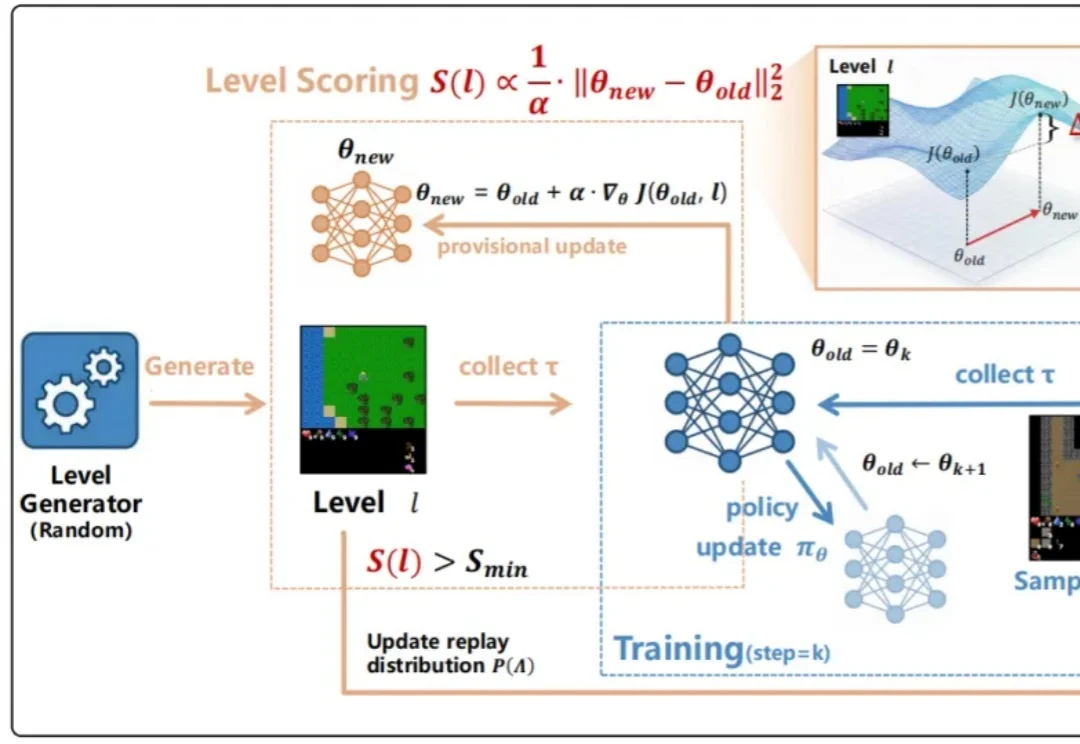
训练强化学习智能体时,一个常见问题是:有些 level 太简单,智能体跑几遍就会;有些 level 又太难,智能体几乎得不到有效反馈。前者只是在重复已有能力,后者则会把训练预算消耗在无效探索上。真正有价值的训练环境,往往位于二者之间。