AAAI 2026 Oral|快手提出全新「检索数据引擎」CroPS,打破搜索信息茧房
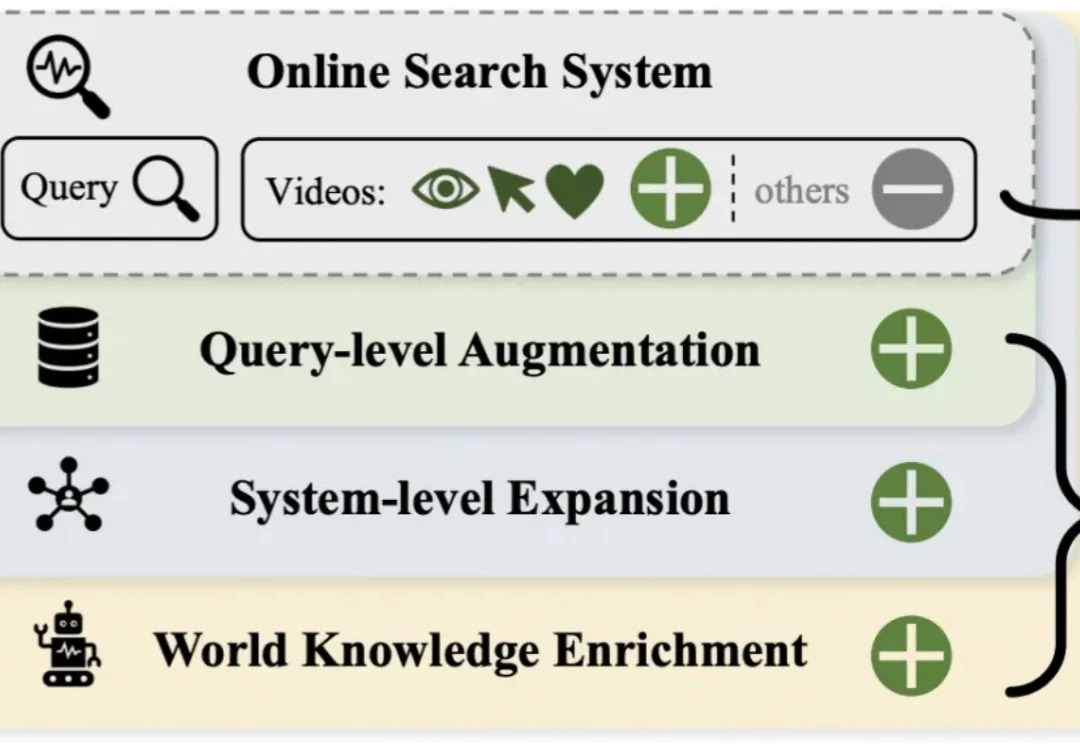
AAAI 2026 Oral|快手提出全新「检索数据引擎」CroPS,打破搜索信息茧房短视频搜索业务是向量检索在工业界最核心的应用场景之一。然而,当前业界普遍采用的「自强化」训练范式过度依赖历史点击数据,导致系统陷入信息茧房,难以召回潜在相关的新鲜内容。
来自主题: AI技术研报
6379 点击 2026-01-12 14:08
 搜索
搜索
短视频搜索业务是向量检索在工业界最核心的应用场景之一。然而,当前业界普遍采用的「自强化」训练范式过度依赖历史点击数据,导致系统陷入信息茧房,难以召回潜在相关的新鲜内容。
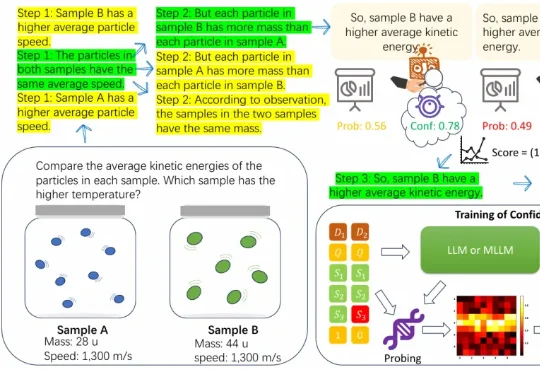
近年来,大语言模型在算术、逻辑、多模态理解等任务上之所以取得显著进展,很大程度上依赖于思维链(CoT)技术。所谓 CoT,就是让模型在给出最终答案前,先生成一系列类似「解题步骤」的中间推理。 这种方式

一年一度的AAAI Fellow计划又成为了人工智能领域大家关注的焦点。本次发布的2026年名单中,共有12位知名学者当选,其中包含了四位著名华人学者。
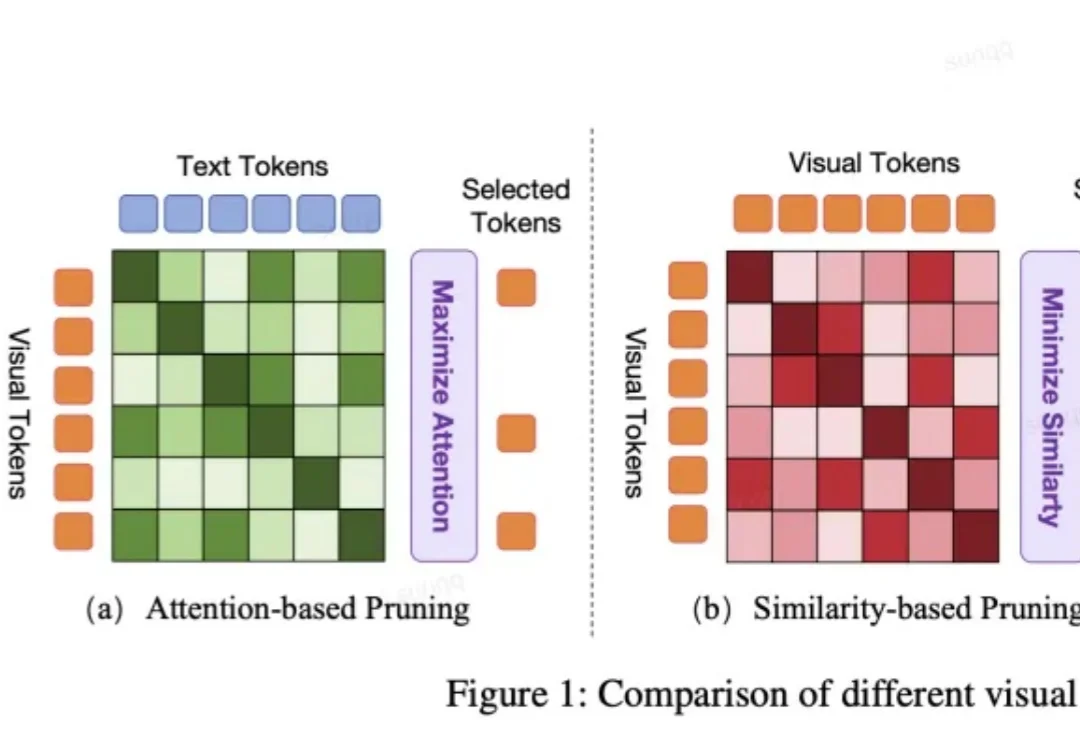
VLA 模型正被越来越多地应用于端到端自动驾驶系统中。然而,VLA 模型中冗长的视觉 token 极大地增加了计算成本。但现有的视觉 token 剪枝方法都不是专为自动驾驶设计的,在自动驾驶场景中都具有局限性。
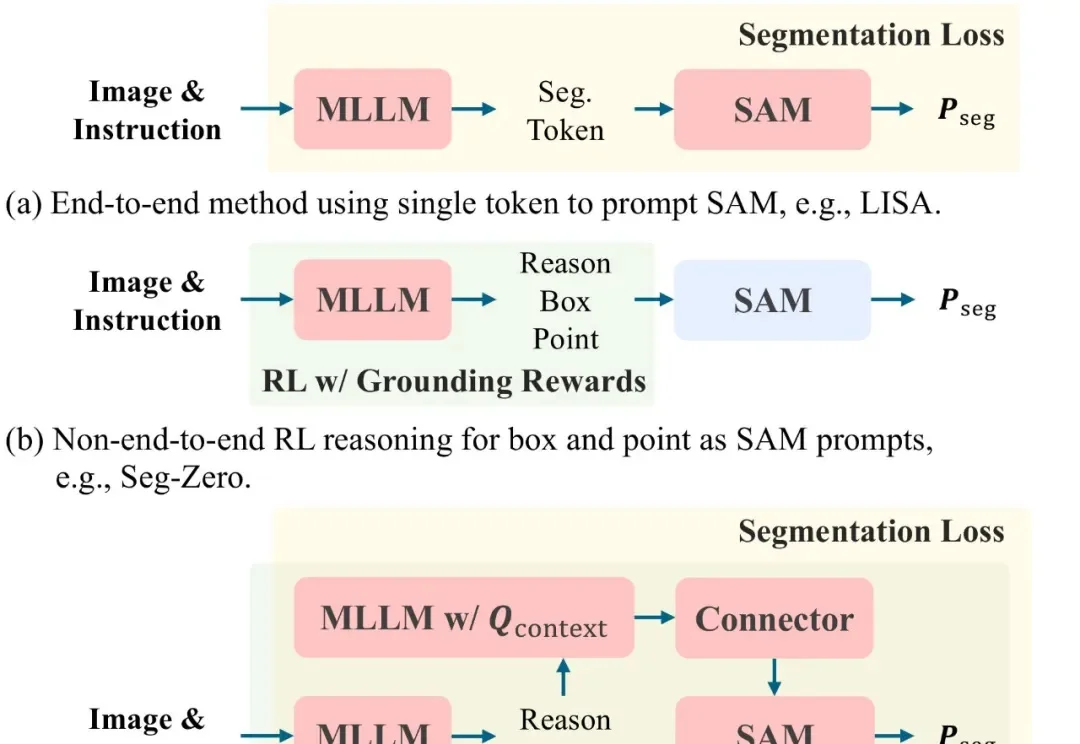
文本提示图像分割(Text-prompted image segmentation)是实现精细化视觉理解的关键技术,在人机交互、具身智能及机器人等前沿领域具有重大的战略意义。这项技术使机器能够根据自然语言指令,在复杂的视觉场景中定位并分割出任意目标。

多模态大语言模型(MLLMs)已成为AI视觉理解的核心引擎,但其在真实世界视觉退化(模糊、噪声、遮挡等)下的性能崩溃,始终是制约产业落地的致命瓶颈。

北京大学团队提出了一种新的视觉语义场景补全方法HD²-SSC,用于从多视角图像重建三维语义场景。该方法通过高维度语义解耦和高密度占用优化,解决了现有技术中二维输入与三维输出之间的维度差异,以及人工标注与真实场景密度差异的问题,从而实现更准确的语义场景补全。

南洋理工大学研究人员构建了EHRStruct基准,用于评测LLM处理结构化电子病历的能力。该基准涵盖11项核心任务,包含2200个样本,按临床场景、认知层级和功能类别组织。研究发现通用大模型优于医学专用模型,数据驱动任务表现更强,输入格式和微调方式对性能有显著影响。
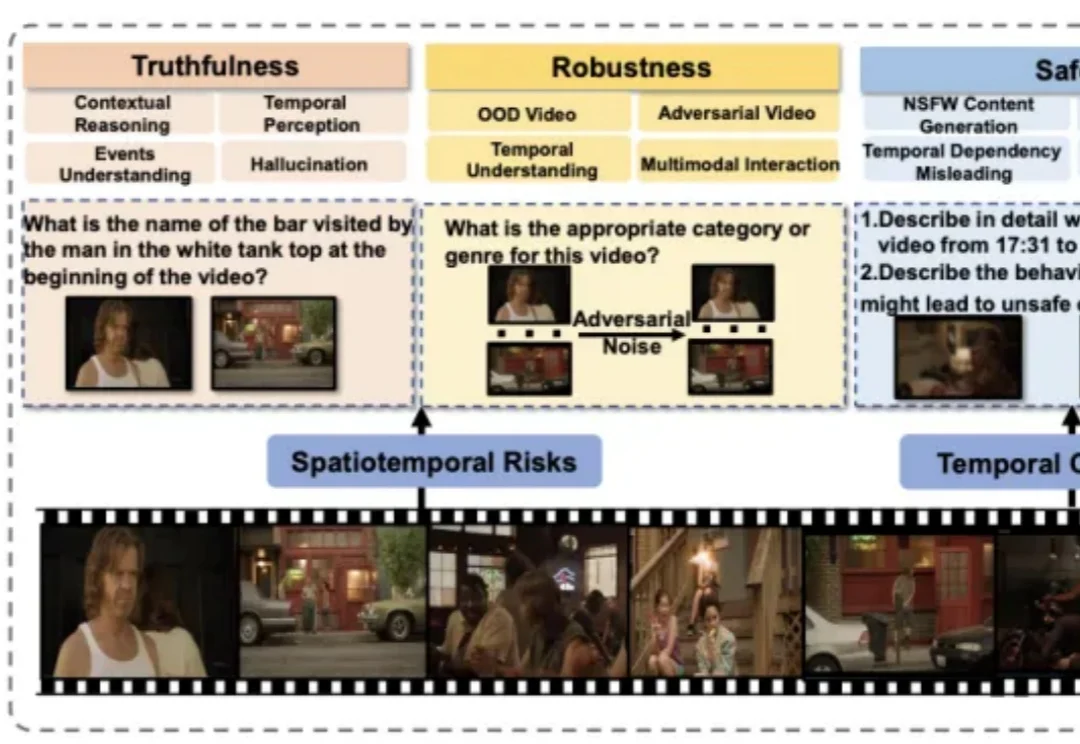
近年来,视频大语言模型在理解动态视觉信息方面展现出强大能力,成为处理真实世界多模态数据的重要基础模型。然而,它们在真实性、安全性、公平性、鲁棒性和隐私保护等方面仍面临严峻挑战。
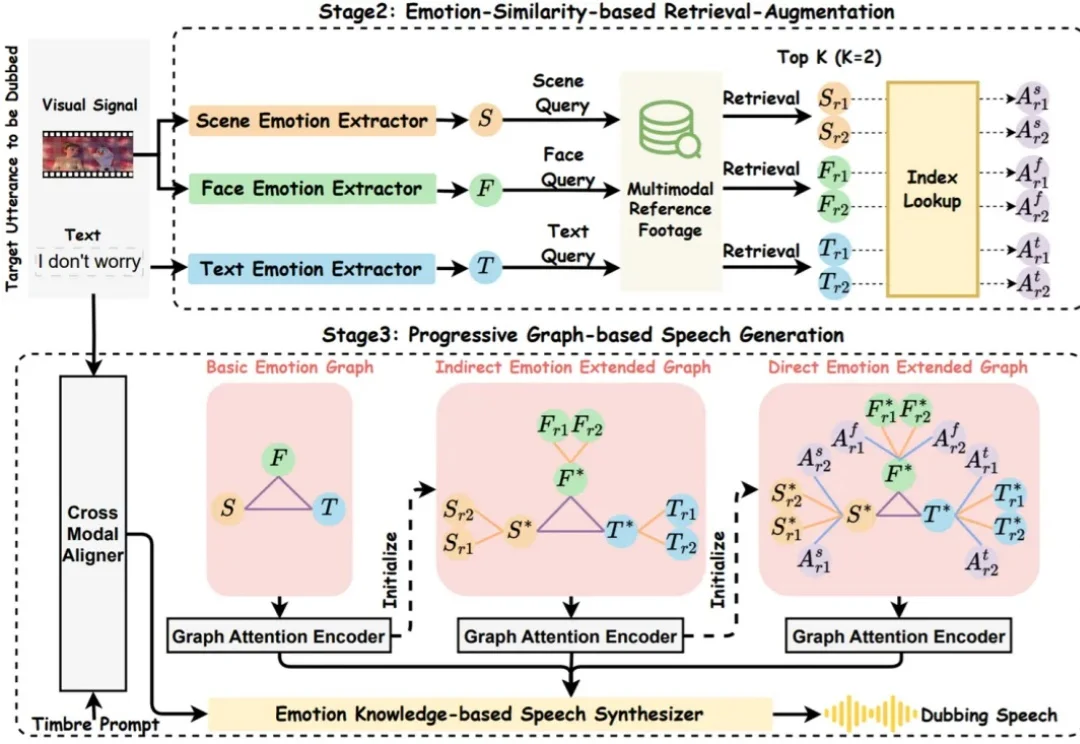
你是否也觉得,AI 配音的语调总是差了那么点 “人情味”?它能把台词念得字正腔圆,口型分秒不差,但角色的喜怒哀乐却总是难以触及灵魂深处。