
Vibe Coding,是怎么「玩废」程序员的?
Vibe Coding,是怎么「玩废」程序员的?「自然语言就是新的编程语言。」这句话在过去一年里被无数人奉为圭臬。特斯拉前 AI 总监 Andrej Karpathy 带火的 「Vibe Coding」(氛围编程)更是让这种狂热达到了顶峰——你不需要懂语法,不需要管实现,只要对着 AI 喊出需求,然后 Check 一下感觉(Vibe)对不对就行了。
来自主题: AI资讯
10205 点击 2026-02-23 18:42
 搜索
搜索
「自然语言就是新的编程语言。」这句话在过去一年里被无数人奉为圭臬。特斯拉前 AI 总监 Andrej Karpathy 带火的 「Vibe Coding」(氛围编程)更是让这种狂热达到了顶峰——你不需要懂语法,不需要管实现,只要对着 AI 喊出需求,然后 Check 一下感觉(Vibe)对不对就行了。
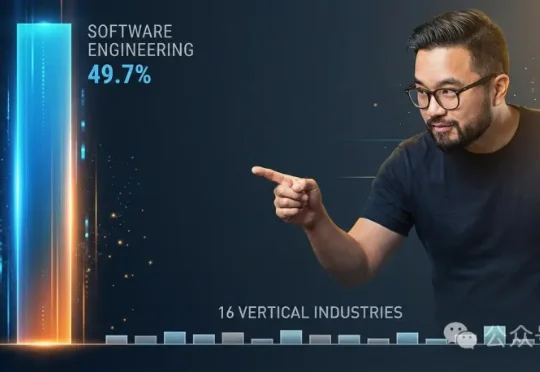
Anthropic最新报告揭示,AI智能体近半数使用量集中在软件工程,其余16个垂直行业各占不到9%。AI已具备连续工作5小时的能力,但用户目前最多只让它跑42分钟,信任远未跟上技术。Y Combinator CEO陈嘉兴断言:这片几乎空白的行业版图里,藏着下一代300个独角兽。
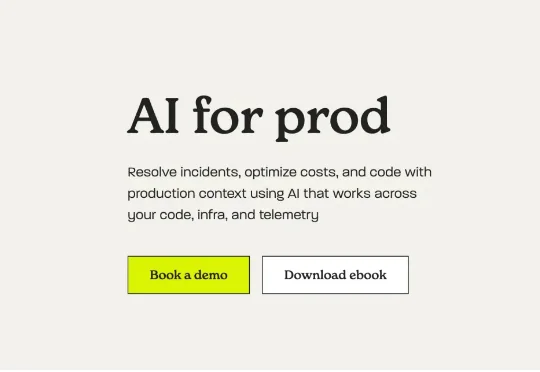
这个矛盾正是Resolve AI要解决的核心问题。这家成立仅16个月的公司刚刚完成了1.25亿美元的A轮融资,估值达到10亿美元。我认为,他们正在定义一个全新的品类:AI for prod,也就是用AI来运行和维护生产环境中的软件。

2月以来,OpenClaw(前身为Clawdbot、Moltbot)卷疯AI圈。在2月21日OpenClaw发布的最新版本中,正式接入了Google Gemini 3.1 Pro预览版,还将Discord引入实时语音与连续路由功能。

自从OpenClaw爆火后,各种Claw开始轮番登场。NanoClaw、ZeroClaw、PicoClaw刷屏,连卡帕西都坐不住了,为了“抓虾”,他一个百米冲刺奔向苹果店抢Mac Mini,要好好拆解一番爆火的各种Claw们。

掌管OpenAI命运的,竟是6个波兰天才?OpenAI首席科学家Jakub Pachocki,接替Ilya之后,完成了后者多年来求而不得的突破。奥特曼甚至专门发了一篇短文,提到OpenAI两位不可或缺的人物:Jakub Pachocki和Szymon Sidor。

我很难用熟悉的软件分类去安放 Typeless。它跟传统输入法格格不入——界面里几乎看不到键盘,最显眼的是一个语音按钮。它也跟那些自称「AI 加持」的输入法不太像,那些产品总喜欢把功能铺满首页,Typeless 的功能反而少得可怜,像是故意把选择题删成了一道填空题。
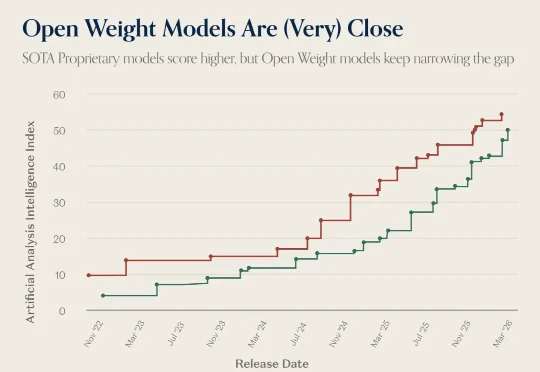
a16z 昨天发了一张图,把 GLM-5 和 Claude Opus 4.6 并排标注在 Artificial Analysis Intelligence Index 的时间线上。原文的说法是: A proprietary model (Claude Opus 4.6) is still the 'most intelligent,' but the gap between

在最近一期 TechCrunch 的《Equity》播客节目中,负责谷歌云全球初创业务的副总裁 Darren Mowry 指出,以这些为卖点的初创公司,已经亮起了「引擎故障灯」。

刚刚,Anthropic发布代码安全工具Claude Code Security,直接让安全股一夜蒸发百亿市值!网络安全龙头CrowdStrike的股价直接原地跌超6.5%,市场陷入极度恐慌:传统安全工具,从此全凉了?