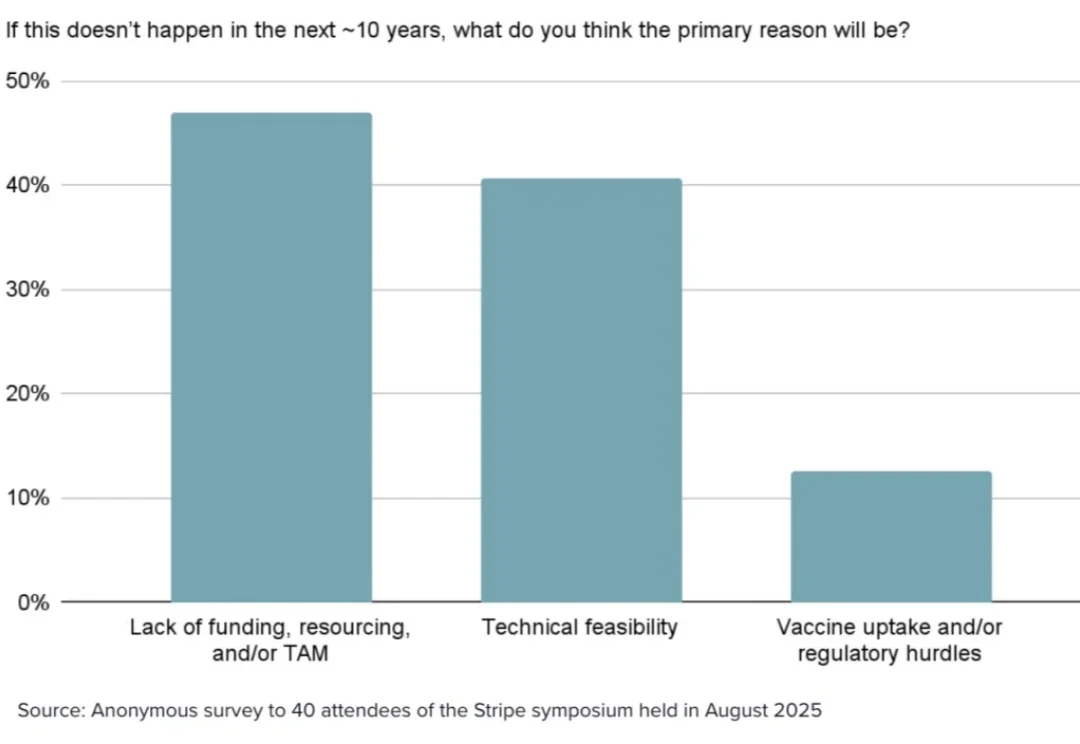
速递!OpenAI发布最新GPT-5.6模型,共有Sol、Terra、Luna 三档模型
速递!OpenAI发布最新GPT-5.6模型,共有Sol、Terra、Luna 三档模型OpenAI 于 6 月 26 日开始有限预览 GPT-5.6 系列模型。新系列包括三款模型:旗舰模型 Sol、均衡型模型 Terra,以及主打低成本和高速度的 Luna。根据 OpenAI 官方介绍,Sol 是 GPT-5.6 系列中能力最强的模型,重点提升了编码、生物工作流、网络安全和长周期智能体任务表现。
来自主题: AI资讯
12507 点击 2026-06-27 01:43