
Kimi Work Beta 版邀你体验:你的工作,分我一半
Kimi Work Beta 版邀你体验:你的工作,分我一半今天,我们邀请你体验 Kimi Work Beta 版。
来自主题: AI资讯
7901 点击 2026-06-04 09:15
 搜索
搜索
今天,我们邀请你体验 Kimi Work Beta 版。
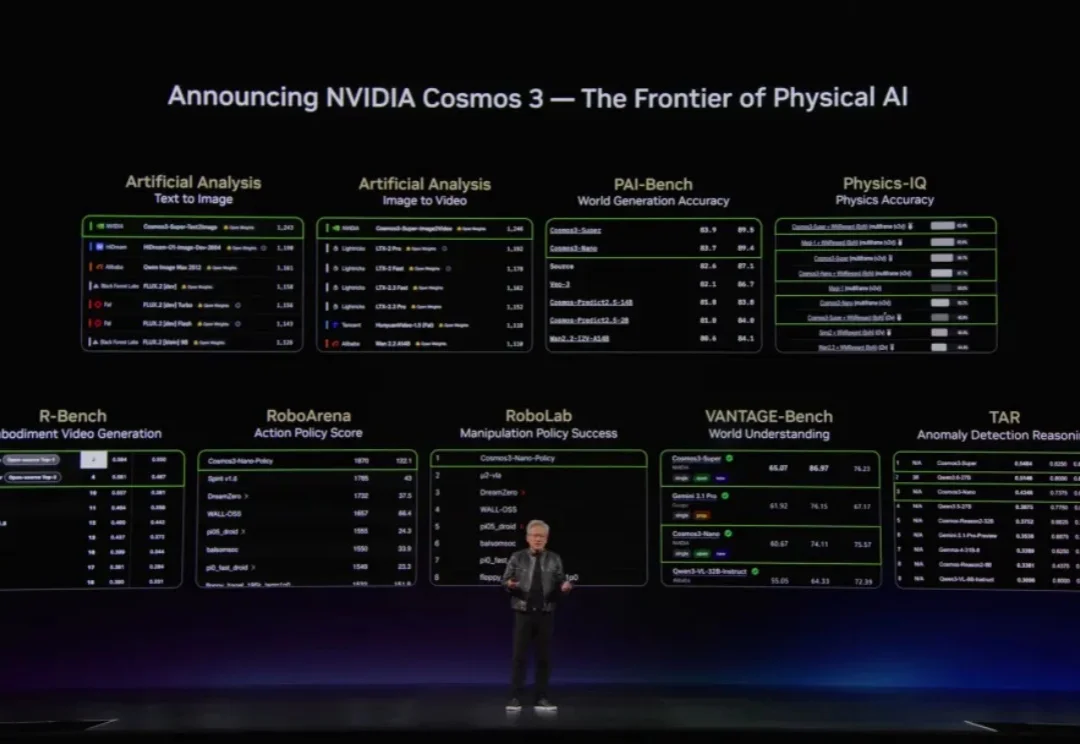
6 月 1 日,老黄在 GTC 上用了不小的篇幅讲物理 AI 和具身智能,并重磅发布了 Cosmos 3。英伟达将其定义为面向 Physical AI 的最新前沿模型,也是全球首个完全开放的全能模型,原生具备视觉推理、世界生成和动作生成能力。

一直有在关注的一个 AI 短剧工具最近终于上线了,那就是群核科技的 LuxReal 短剧版。

刚刚过去的GTC Taipei上,最备受关注的,莫过于Cosmos 3。

赋予机器人物理理解和预测能力是通用操作的关键。蚂蚁灵波等机构提出的 LingBot-VA 试图将视频帧预测与动作推理统一起来,让机器人通过自回归扩散框架学会“一边思考一边行动”。

你有没有想过,作为一个软件创业者,你每个月到底在对账和财务事务上浪费了多少时间?银行流水要确认,薪资系统要对齐,Stripe 里的收款记录要归类,还有各种供应商发票要处理。这些事情不难,甚至可以说很机械,但它们每个月都会悄无声息地吃掉你好几个小时。
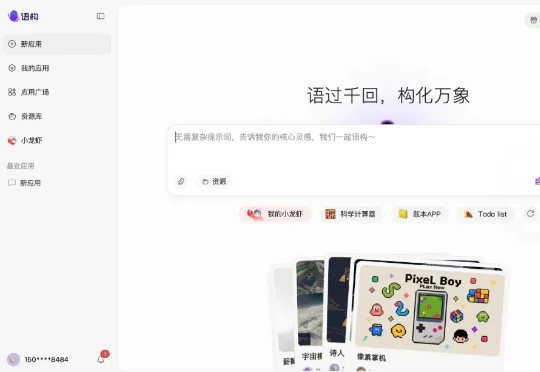
我在想一个问题。 现在做Vibe Coding的产品挺多的了,如果又有大厂跳出来说要做这个,能整出什么差异化? 《读佳》独家获知,阿里达摩院正式推出AI原生开发平台“语构”,这款产品以Vibe Cod

感觉大家对追新这事,没那么上头了。

这篇文章想回答几个大家更关心的基础问题:Vector Lakebase 能解决你的什么问题,什么场景下用它最合适,如何用好Vector Lakebase 。
这一切都是关于让我们抛弃我们所知道的关于音乐的一切,让我们尝试从零开始。它只是一个声波。这只是每秒采样48000次。它是一个连续的浮动32号。让我们弄清楚如何建模。