

增速12.8%,人工智能成为上海经济发展重要动力
增速12.8%,人工智能成为上海经济发展重要动力上海前三季度GDP增5.5%,AI制造业增12.8%,成增长引擎。
来自主题: AI资讯
8033 点击 2025-10-23 11:36
上海前三季度GDP增5.5%,AI制造业增12.8%,成增长引擎。

整个Hugging Face的趋势版里,前4有3个OCR,甚至Qwen3-VL-8B也能干OCR的活,说一句全员OCR真的不过分。然后在我上一篇讲DeepSeek-OCR文章的评论区里,有很多朋友都在把DeepSeek-OCR跟PaddleOCR-VL做对比,也有很多人都在问,能不能再解读一下百度那个OCR模型(也就是PaddleOCR-VL)。
昨天晚上闲着没事,想在 DeepSeek 搜一下 AI 博主有哪些可以学习的。 结果没想到,搜索结果里竟然出现了我自己。 内心 OS:祖坟冒青烟了,妈妈我出息了,我被 AI 认证了,以后简历可以写被

生成式 AI 正在重写 3D 内容的生产流程:从“DCC 工具 + 外包”的线性供给,演进到“资产规模化生成 + 管线可用”的指数供给模式。过去五年,技术范式经历了从实时体积渲染,NeRF,到Score Distillation,3D扩散的快速迭代;需求侧则由游戏与影视,向3D 打印、电商样机、数字人、教育培训、以及AR/VR等长尾场景外溢。

甲骨文于上周发布全球最大云端AI超级计算机「OCI Zettascale10」,由80万块NVIDIA GPU组成,峰值算力高达16 ZettaFLOPS,成为OpenAI「星际之门」集群的算力核心。其独创Acceleron RoCE网络实现GPU间高效互联,显著提升性能与能效。该系统象征甲骨文在AI基础设施竞争中的强势布局。
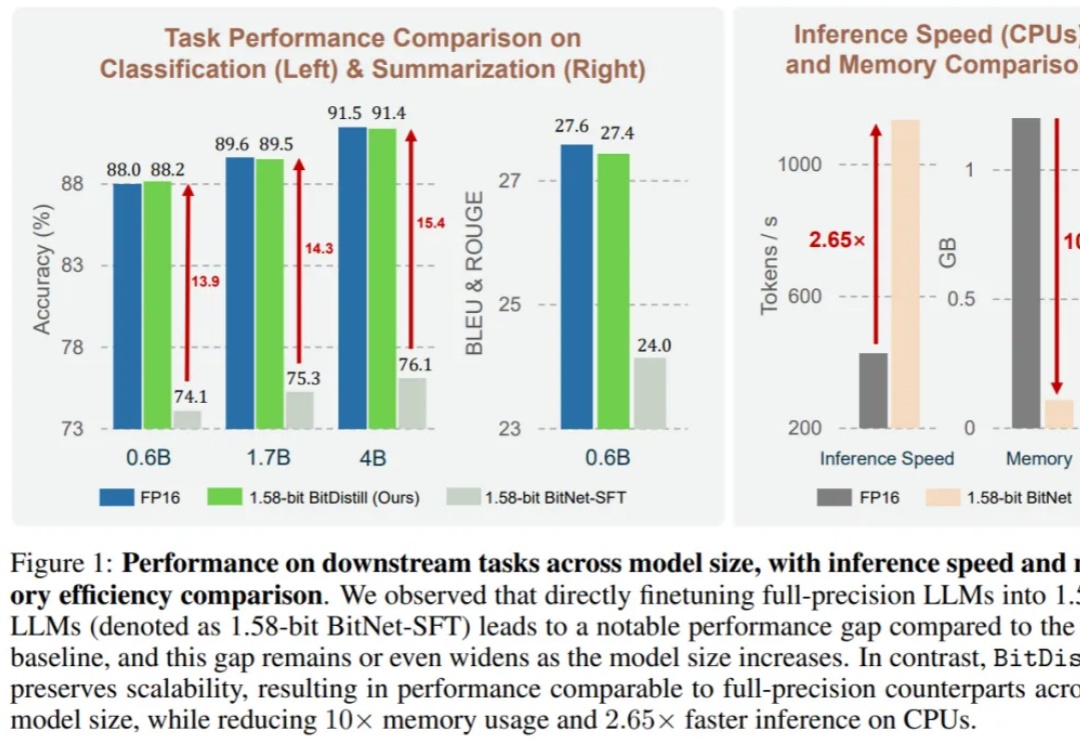
大语言模型(LLM)不仅在推动通用自然语言处理方面发挥了关键作用,更重要的是,它们已成为支撑多种下游应用如推荐、分类和检索的核心引擎。尽管 LLM 具有广泛的适用性,但在下游任务中高效部署仍面临重大挑战。
“我有两张券,分别为满1000减140、满2000减280,我看中商品的价格分别为……分两次结算怎么凑单最划算?”双11开启后,在社交平台上,有人向Deepseek抛出这个问题。

据业内人士透露,微软已向英特尔下达其下一代人工智能芯片Maia 2的晶圆代工订单,计划采用英特尔的18A或18A-P制程。该芯片或将用于微软Azure数据中心等人工智能基础设施。

刚刚,宇树发布第四款人形机器人 H2,高 180cm,重 70kg。和前代 H1 相比,今天发布的 H2 无论是在运动流畅性、还是仿生特征上,都有了相当大的升级。首先是整体的外观形态,和 H 系列都是 180cm 的身高一致,但是 H2 的重量突破性地来到了 70kg 左右,H1 仅有约 47kg。如果要计算它的 BMI,21.6 的结果,妥妥的一个健康好身材。
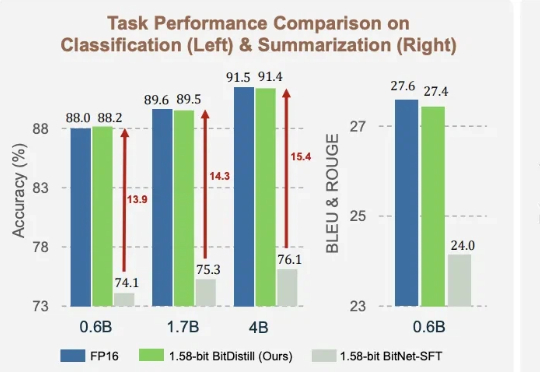
1.58bit量化,内存仅需1/10,但表现不输FP16? 微软最新推出的蒸馏框架BitNet Distillation(简称BitDistill),实现了几乎无性能损失的模型量化。