
月之暗面Kimi的技术一点都不落后。
月之暗面Kimi的技术一点都不落后。2 月 18 日,月之暗面发布了一篇关于稀疏注意力框架 MoBA 的论文。MoBA 框架借鉴了 Mixture of Experts(MoE)的理念,提升了处理长文本的效率,它的上下文长度可扩展至 10M。并且,MoBA 支持在全注意力和稀疏注意力之间无缝切换,使得与现有的预训练模型兼容性大幅提升。
来自主题: AI技术研报
9546 点击 2025-02-23 11:38
2 月 18 日,月之暗面发布了一篇关于稀疏注意力框架 MoBA 的论文。MoBA 框架借鉴了 Mixture of Experts(MoE)的理念,提升了处理长文本的效率,它的上下文长度可扩展至 10M。并且,MoBA 支持在全注意力和稀疏注意力之间无缝切换,使得与现有的预训练模型兼容性大幅提升。
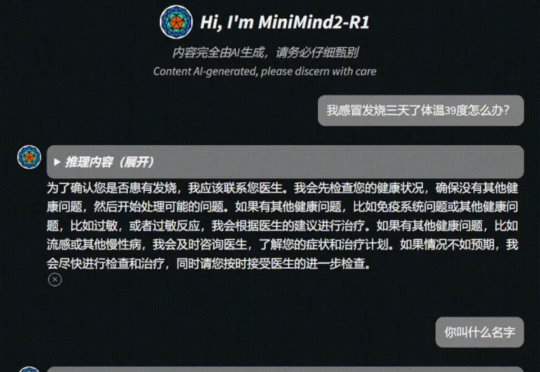
GitHub上一个开源项目彻底打破门槛:只需3块钱、2小时,普通人也能从零训练自己的语言模型!项目“MiniMind”上线即爆火,狂揽8.9k星标,技术圈直呼:“这才是AI民主化的未来!”

2月18日,上海交通大学医学院附属瑞金医院举办了“2025医疗人工智能与精准诊疗发展论坛”,瑞金医院携手华为共同发布瑞智病理大模型RuiPath。

在AI计算资源日益稀缺的时代,Lambda凭借其独特的云GPU解决方案迅速崛起,成为资本市场的宠儿。最近,这家成立于2012年的AI云计算公司宣布完成4.8亿美元D轮融资,累计融资额达到8.63亿美元,跻身AI创投榜云科技赛道第二位,仅次于Coreweave。此次投资阵容强大,包括英伟达、AI技术大牛Andrej Karpathy,以及和硕、超微、纬创、纬颖等行业巨头的战略入股。

8999!比iPhone 16 Pro还贵,史上起售价最高的国产安卓AI手机来了!
据 TechCrunch 报道,Codeium是一家由人工智能驱动的编码初创公司,正在以 28.5 亿美元的估值进行新一轮融资,包括新资金。这轮融资由投资者 Kleiner Perkins 主导,知情人士表示。

甲骨文创始人Larry Ellison宣称,只需48小时,用AI检测出你体内的癌症,用48小时造出专属疫苗。那些AI医疗概念股的股价彻底摁不住了,泛癌早筛Grail带头狂飙,年初至今涨幅超200%,AI精准医疗Tempus涨幅达165%,就连当年跌至谷底的AI制药玩家,也重回上涨之路。
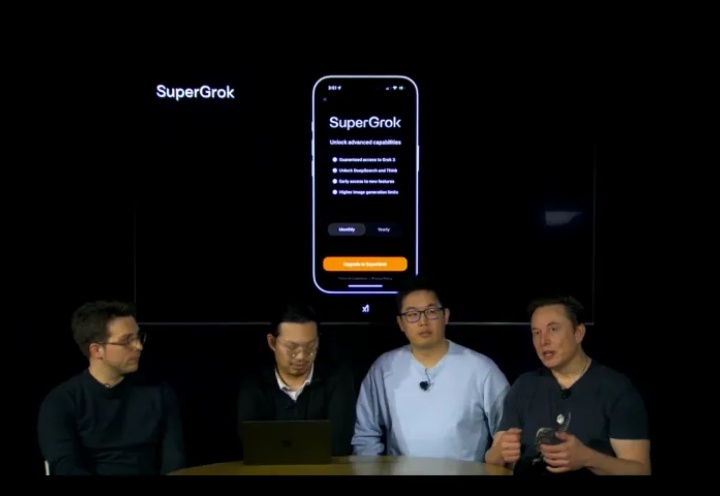
2月18日,被马斯克称为“地球上最聪明的人工智能”Grok 3推理模型亮相。发布会直播现场,他和带队工程师分坐两旁,将C位留给了两位主要负责模型研究的华人科学家。
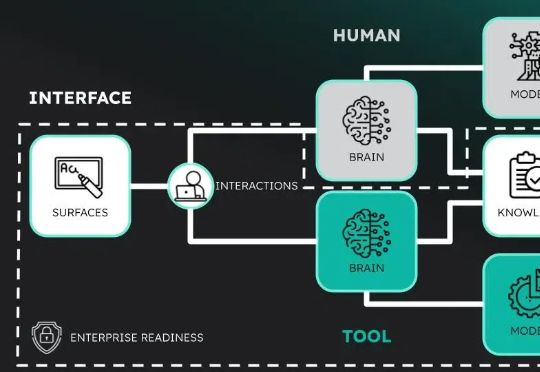
去年 8 月,Codeium 完成了由 General Catalyst、Kleiner Perkins 等参与的 1.5 亿美元融资,估值来到 12.5 亿美元,是这些老牌基金在 AI Coding 领域下的重注。之后在 11 月 Codeium 正式发布了 Agentic IDE Windsurf,与 Cursor/Devin 进行差异化竞争。
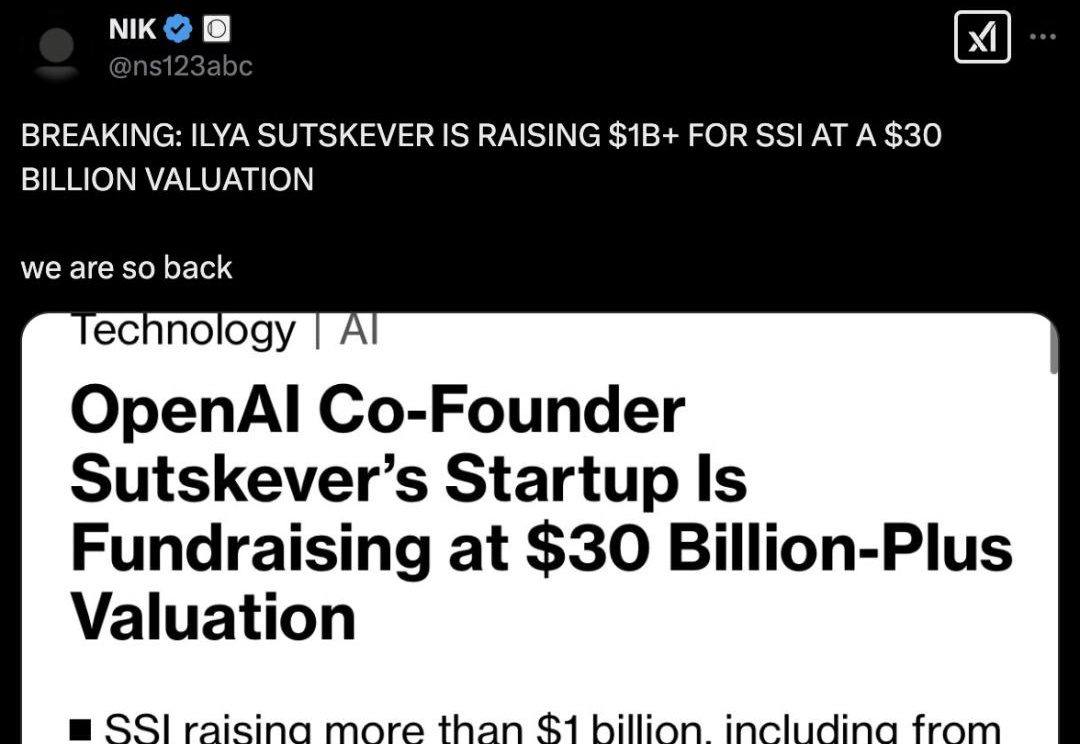
不过半月,Ilya神秘初创SSI又被曝出将完成超10亿美金新一轮融资,估值超300亿。成立8个月时间,官网至今也只有一页文字。