
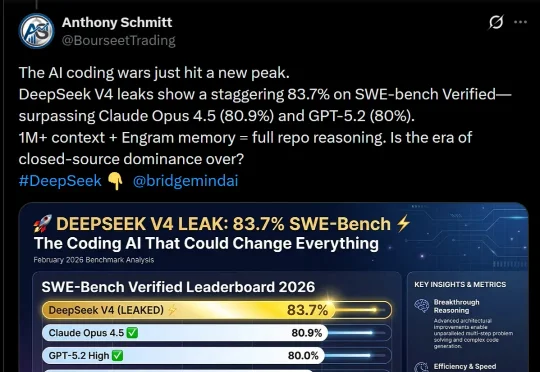
刚刚,DeepSeek V4基准测试泄露!疑似明天发布,全场惊呼新王归来
刚刚,DeepSeek V4基准测试泄露!疑似明天发布,全场惊呼新王归来DeepSeek V4,据说明天就要上线了?这是首个匹敌顶尖闭源模型的开源模型,被网友评为「一鲸落万物生」。泄露的基准测试显示,它在SWE-bench Verified上取得了83.7%,已经超越Opus 4.5和GPT-5.2!
来自主题: AI资讯
9768 点击 2026-02-16 20:04
DeepSeek V4,据说明天就要上线了?这是首个匹敌顶尖闭源模型的开源模型,被网友评为「一鲸落万物生」。泄露的基准测试显示,它在SWE-bench Verified上取得了83.7%,已经超越Opus 4.5和GPT-5.2!
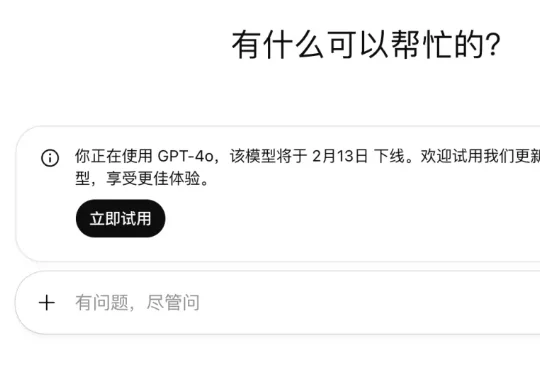
Jane 打开 ChatGPT,熟练地切换到 GPT-4o,屏幕上弹出那行熟悉的提示。 「你正在使用 GPT-4o,该模型将于 2 月 13 日下线。欢迎试用我们更新、更强大的模型,享受更佳体验。」

OpenClaw之父Peter Steinberger做客全球第一播客,首次披露Meta与OpenAI的收购争夺内幕。他用1小时原型撬动GitHub 18万星,打造出能自我修改源码的AI智能体,扬言将消灭80%的App,并宣称编程终将沦为「织毛衣」。一个奥地利独狼程序员,正在亲手颠覆整个软件行业。
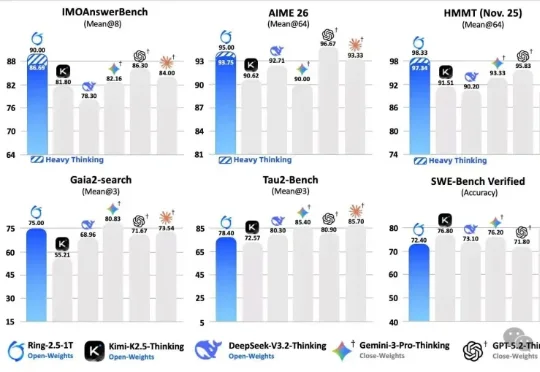
先介绍一下今天的主角。Ring-2.5-1T,蚂蚁百灵团队刚发布的万亿参数开源思考模型,全球首个混合线性注意力架构的万亿级选手。IMO 2025 国际奥数 35/42 拿到金牌水平,CMO 2025 中国奥数 105 分远超国家集训队线 87 分,GAIA2 通用 Agent 评测开源 SOTA。数字很漂亮,但数字谁都会贴。
当看到GLM-5正式发布后的能力,才惊觉前几天神秘模型Pony Alpha的热度还是有点保守了。

就是说,这几天还有哪档晚会节目是没有机器人现身的吗?
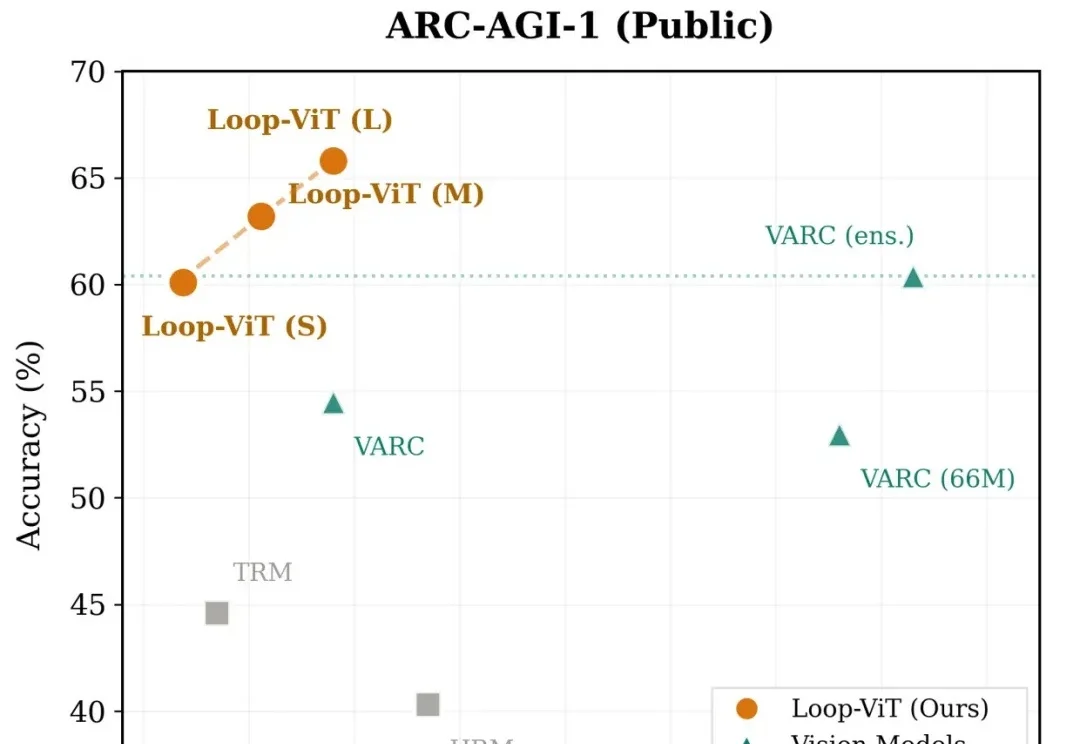
当我们解一道复杂的数学题或观察一幅抽象图案时,大脑往往需要反复思考、逐步推演。然而,当前主流的深度学习模型却走的是「一次通过」的路线——输入数据,经过固定层数的网络,直接输出答案。
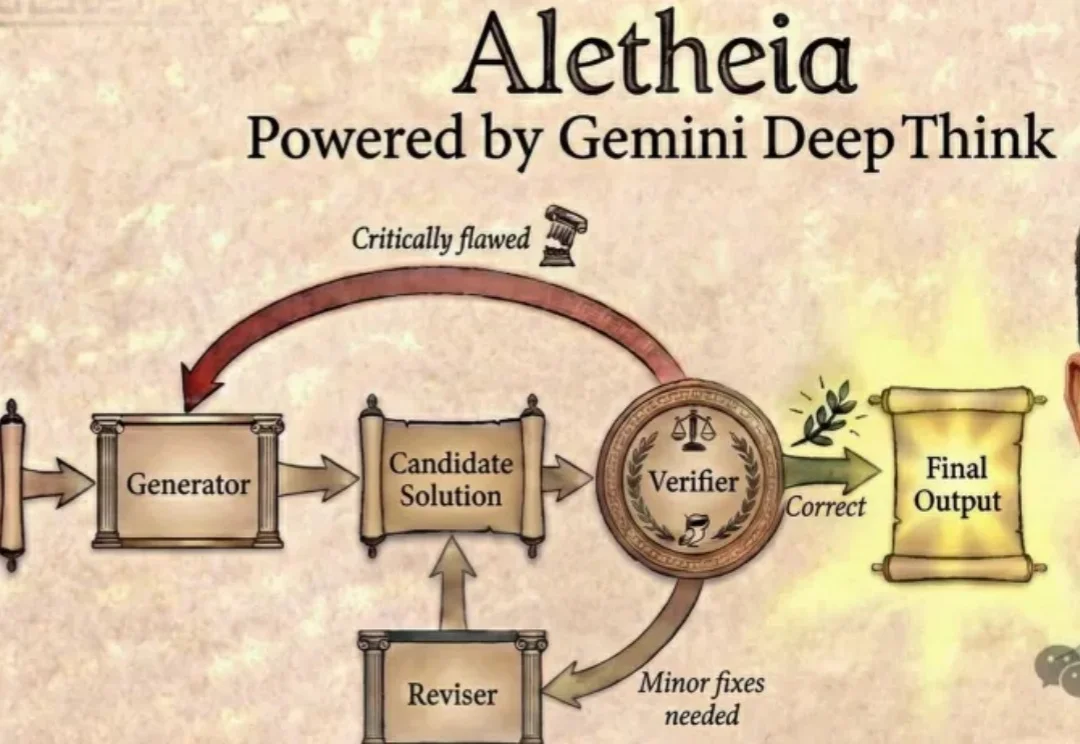
今天,谷歌DeepMind「AI数学家」Aletheia彻底杀疯了,攻克数学猜想,独立写论文。更令人震惊的是,拿下金牌的Gemini一举横扫18大核心科研难题。
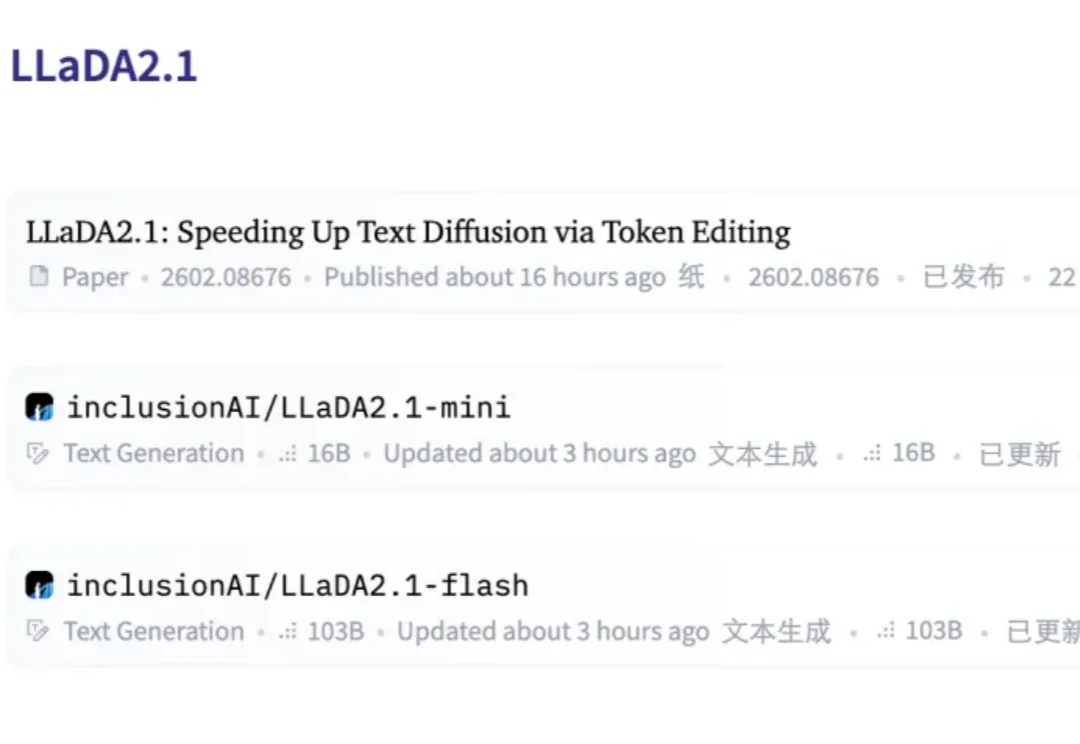
扩散语言模型(dLLM),这个曾被认为是「小众赛道」的研究方向,如今终于迎来了质变。

Anthropic刚刚扔出一份18页重磅炸弹:《2026年智能体编码趋势报告》。结论直接炸裂:程序员不再写代码了,他们变成了「指挥官」。