
指令遵循媲美Seedance 2.0!复旦腾讯联合提出Baton,多说话人场景M-WER暴降76%
指令遵循媲美Seedance 2.0!复旦腾讯联合提出Baton,多说话人场景M-WER暴降76%视频生成,早已不止于视觉。
来自主题: AI技术研报
7441 点击 2026-06-11 15:01
 搜索
搜索
视频生成,早已不止于视觉。

2026年的文娱行业,正在经历一场悄无声息的人事结构变革。

2007 年,乔布斯用一块 3.5 英寸的屏幕,将人类的信息交互折叠进了一个发光的二维平面。

几经波折之后,我们终于将手里的几台 iPhone 都更新到了 iOS 27,体验到了五年以来最重大的一次 Siri 更新。

无论「机器人女友」的反对声音多大,消费端已经开始买单。
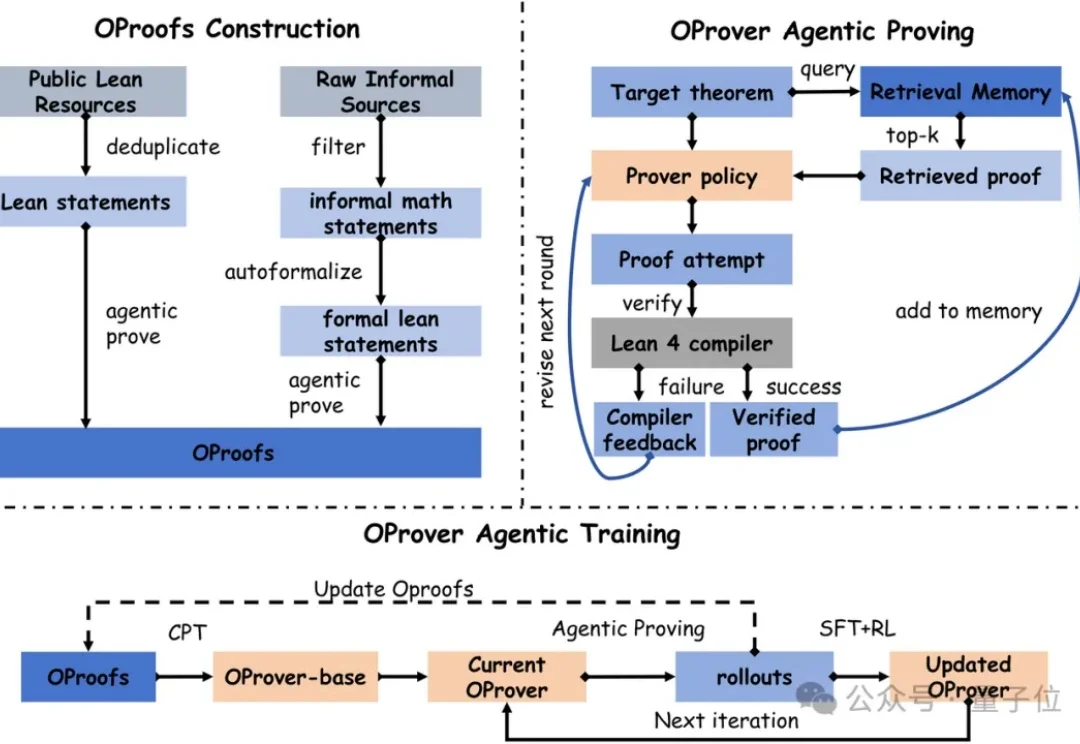
形式化定理证明,一直是LLM公认最严苛的推理试金石,每一步推导都必须通过Lean 4内核的机器验证。

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

太突然了!Sora核心骨干、17岁高中辍学天才Gabriel正式官宣离开OpenAI。他要押上全部,打造AGI前夜的「最后一个产品」。

致力于成为金融界“DeepSeek”。金融垂域大模型公司Grace Investment Machine(简称GIM)宣布一连完成过亿元天使轮和天使+轮融资。成立于2025年7月,GIM正在做一件事:为金融行业打造一个垂直领域的DeepSeek——专为投资决策而生的推理大模型。

英国当地时间6月7日,据《金融时报》援引知情人士的话披露,OpenAI正准备对ChatGPT进行自2022年推出以来规模最大的改版,新版将在未来几周内逐步上线。