427亿!马斯克SpaceXAI拿下AI算力大单
427亿!马斯克SpaceXAI拿下AI算力大单昨晚,美国开源AI初创公司Reflection AI宣布,已与SpaceXAI签署算力协议,将获得Colossus 2数据中心的额外算力支持,用于训练和迭代更强的开放模型。另据TechCrunch报道,Reflection AI将从2026年7月1日起,每月支付1.5亿美元(约合人民币10.2亿元),
来自主题: AI资讯
8724 点击 2026-06-25 10:43
 搜索
搜索
昨晚,美国开源AI初创公司Reflection AI宣布,已与SpaceXAI签署算力协议,将获得Colossus 2数据中心的额外算力支持,用于训练和迭代更强的开放模型。另据TechCrunch报道,Reflection AI将从2026年7月1日起,每月支付1.5亿美元(约合人民币10.2亿元),

谷歌留不住人了!诺奖得主离职后,Gemini两大核心将一同入职Anthropic。同一天,Gemini 3.5 Pro已延期至7月。

近日,西班牙AI机器人公司 Theker 宣布完成7300万欧元(约合8500万美元)的A轮融资。这是欧洲机器人领域史上规模最大的A轮融资。时尚巨头Zara的母公司Inditex不仅是公司早期投资方,公司机器人已在Inditex的实际生产设施中运行。
一个模型能模拟7种环境。
6月17日,X 上 OpenAI Codex 团队负责人 Tibo(@thsottiaux)发了一条推文,提醒大家 Codex App、CLI 和 SDK 现在可以接任何开源模型,不只限于 OpenAI 自己的模型。
今天,华盛顿大学即将毕业的博士生 Alisa Liu 要加入 OpenAI 的消息上了 X 热搜。主贴浏览量已突破百万,她表示这次找工作的过程比想象中更有挑战,但也收获满满。所以她写了一篇小博客,分享一路走来学到的经验,也希望能让下一个经历这个过程的人少一点困惑。
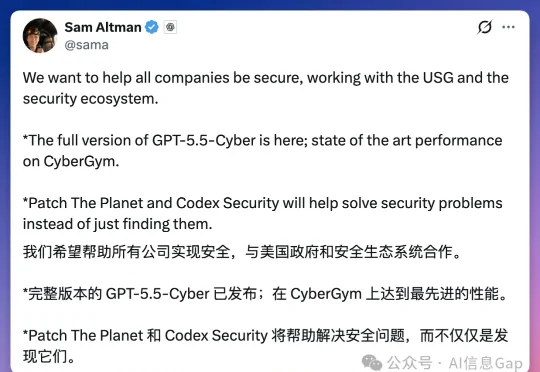
就在刚刚,OpenAI 直接放出了满血版 GPT-5.5-Cyber。CyberGym 安全评测排行榜,GPT-5.5-Cyber 得分 85.6%,单模型最高分。Claude Mythos 5 第二,83.8%。Claude Opus 4.7 排末尾,73.1%。
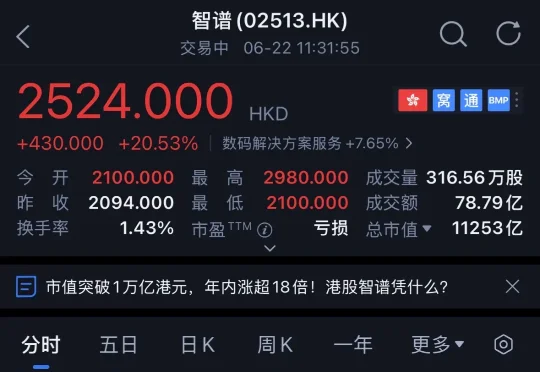
今日港股开盘后,智谱总市值首次突破1万亿港元,年内涨超2000%。截至今日11点31分,其股价为每股2524港元(约合人民币2181元),相比昨日收盘价上涨20.53%,总市值达到11253亿港元(约合人民币9722亿元)。
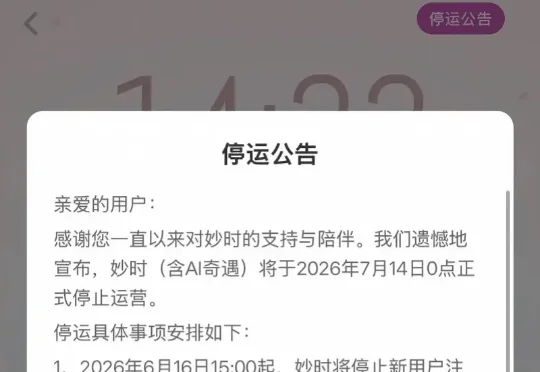
公告显示,“妙时”(含AI奇遇)将于7月14日0时正式停止运营。目前,平台已停止新用户注册、充值及会员购买等服务。停运后,“妙时”将全面关闭所有功能。用户账号中剩余的妙时币、曲奇币、电波及会员费用,可于8月14日前通过邮件申请退款。

刚刚, OpenAI、Google DeepMind、Anthropic三大AI巨头CEO与G7领导人在法国阿尔卑斯山共进工作午餐,历史首次。上一次这些领导人坐在一起,讨论的是二毛、中东、全球供应链这些问题。现在AI公司的CEO被请到了同一张桌子上。