
VAST完成5000万美元A轮融资,加速构建世界模型与UGC互动内容平台
VAST完成5000万美元A轮融资,加速构建世界模型与UGC互动内容平台通用人工智能公司 VAST 今日宣布完成 5000 万美元 A 轮融资。本轮融资由阿里、恒旭资本联合领投,元禾璞华、BV 百度风投、东方嘉富等跟投,形成覆盖顶级资本、产业巨头、知名战投的全方位赋能格局。
来自主题: AI资讯
6796 点击 2026-03-06 10:36
 搜索
搜索
通用人工智能公司 VAST 今日宣布完成 5000 万美元 A 轮融资。本轮融资由阿里、恒旭资本联合领投,元禾璞华、BV 百度风投、东方嘉富等跟投,形成覆盖顶级资本、产业巨头、知名战投的全方位赋能格局。
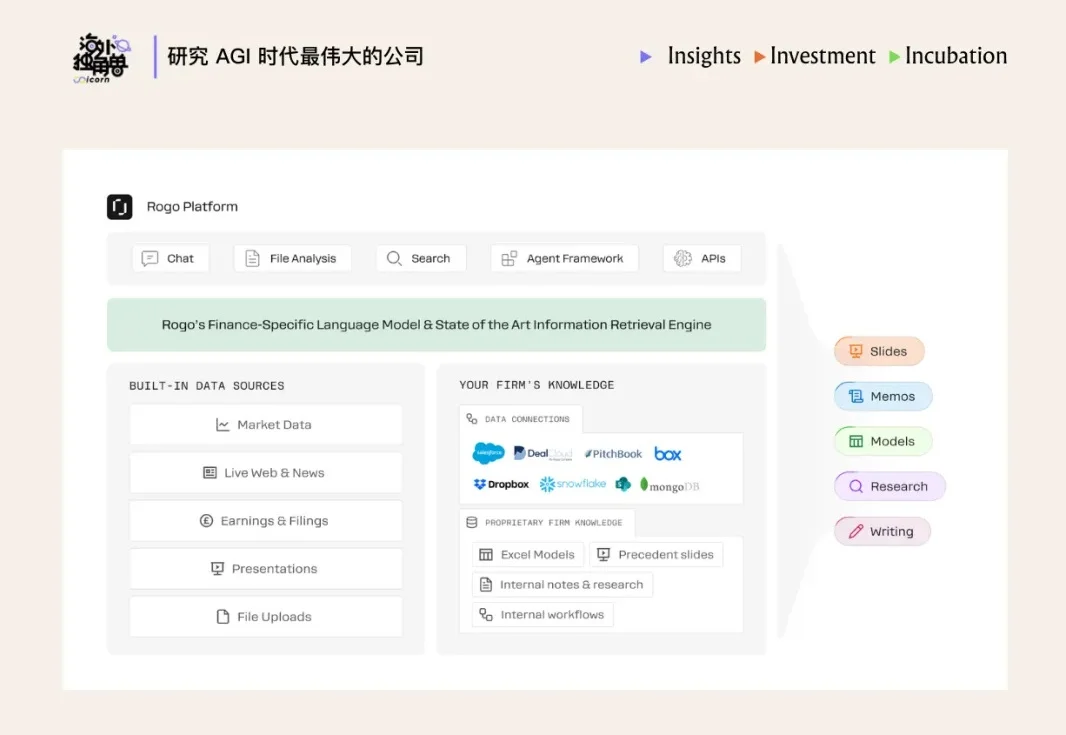
全球投行业每年处理超过 3.5 万亿美元的交易,但驱动这台庞大机器运转的,是数以万计每周工作超过百小时、从事着高度重复性劳动的初级分析师。Vertical Agent 开始加速很多专业领域的工作流,比如法律领域的 Harvey、医疗领域的 OpenEvidence,而在离钱最近的金融领域迟迟未能出现一款真正的统治级应用。
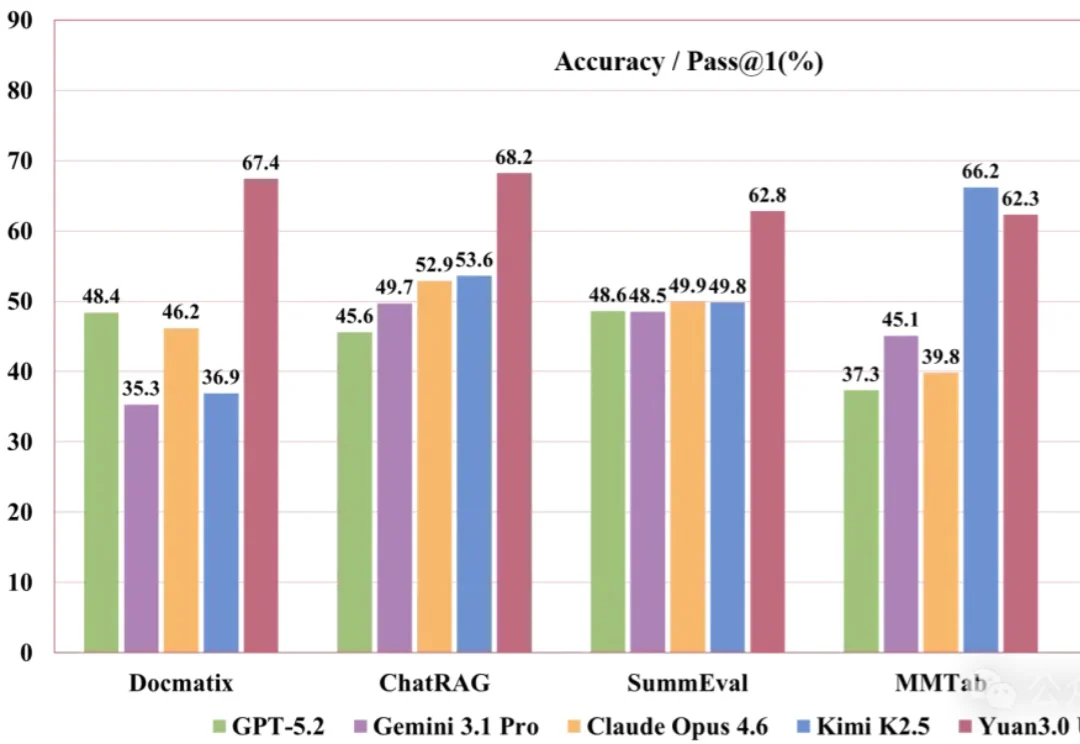
刚刚,YuanLab.ai团队正式开源发布源Yuan3.0 Ultra多模态基础大模型。
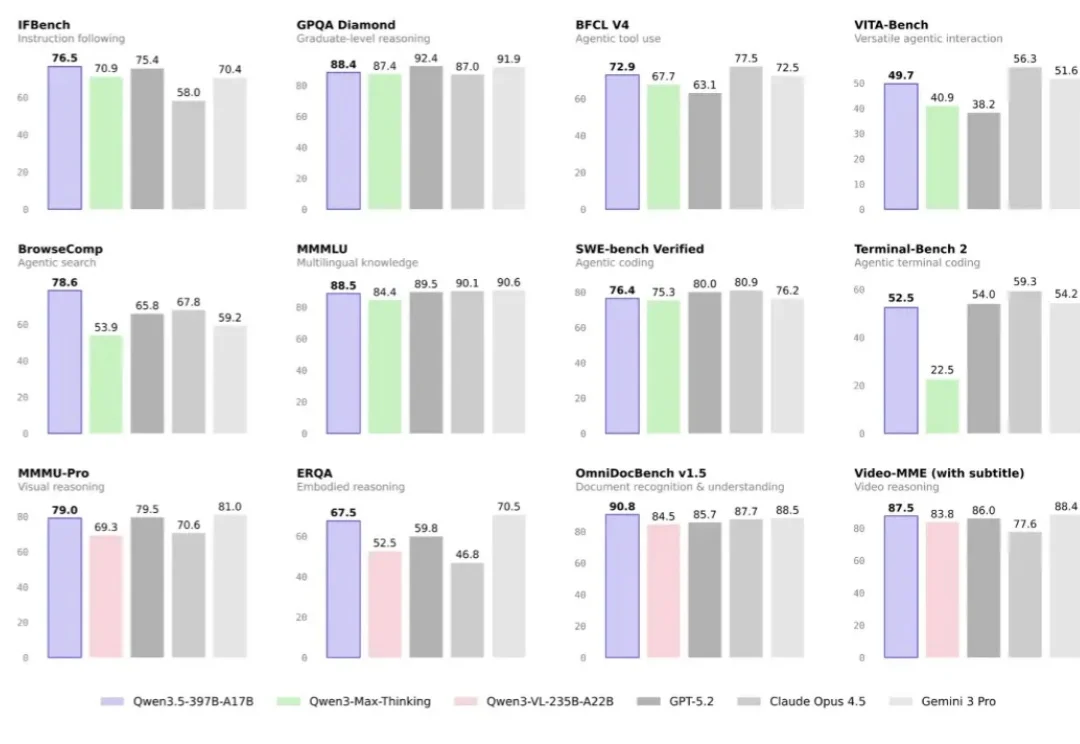
最近关于Qwen3.5还有其幕后团队,市场上的讨论沸沸扬扬,但今天我们不聊八卦,主要讲讲干货。

OpenAI深夜突袭,GPT-5.4新王炸场!一夜之间,直接粉碎了Gemini 3.1 Pro和Claude Opus 4.6的神话。这也是头一次,ChatGPT拥有真正「原生电脑使用」能力,办公效率直接拉满。而真正恐怖的地方在于,每一个维度上它都没有短板。
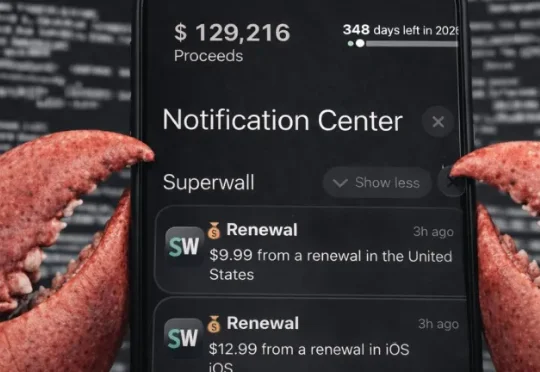
国外有一个小哥,超级个体,也就是现在国内流行的 OPC(一人公司),靠 11 个应用加 OpenClaw,每月能赚 7.3 万美元。这篇文章里,他专门拆解 OpenClaw 是怎么帮我们赚真金白银的,以及如何通过自动化把主动收入变成被动收入。
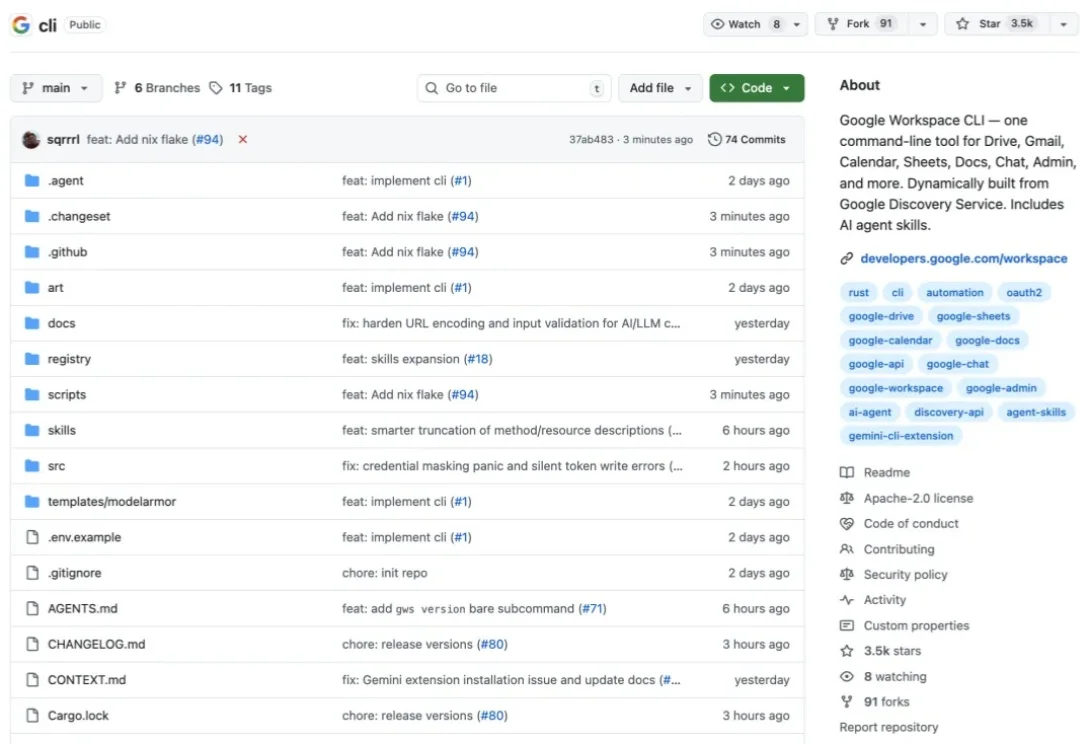
今天上午的时候,Google Workspace CLI 上线到了 GitHub,挂在 Google Workspace 的官方组织名下。我开始写这篇文章的时候,这个项目是 2700 个 Star;当我发出去的时候,重新截了个图,已经有 3500 个 Star 了

OpenAI的人才地震还在继续!刚刚,前研究副总裁Max Schwarzer宣布离职,这位亲手主导o1、o3和整个GPT-5系列post-training的核心人物,选择加入Anthropic,重返一线RL研究。
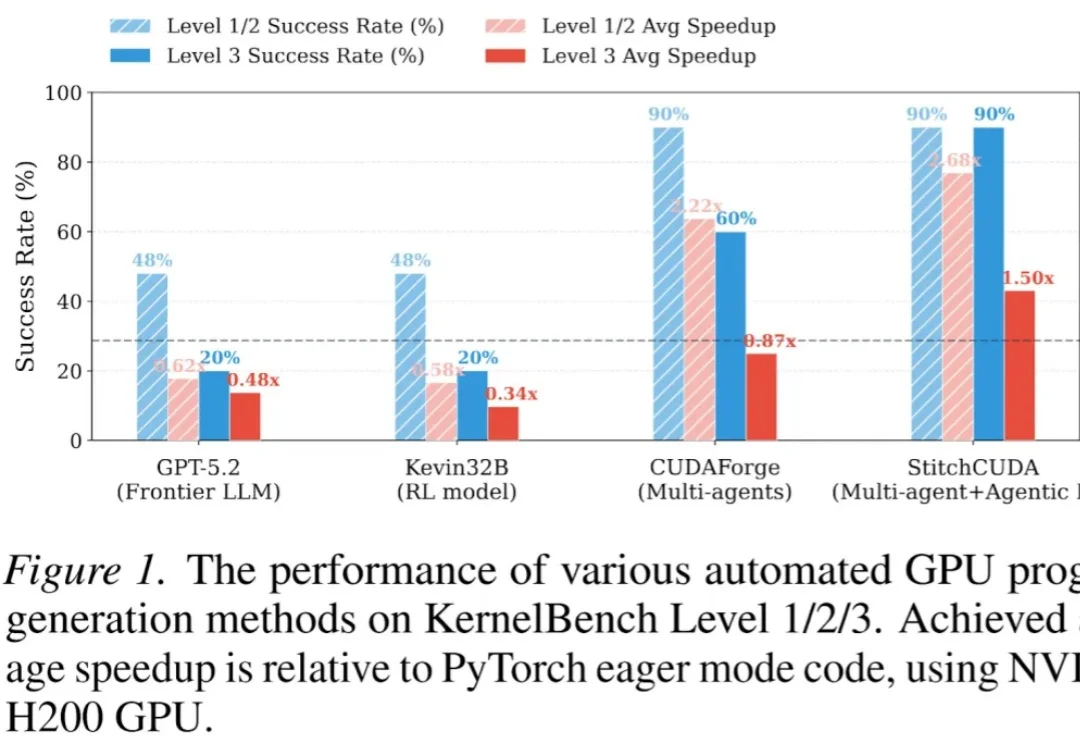
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。
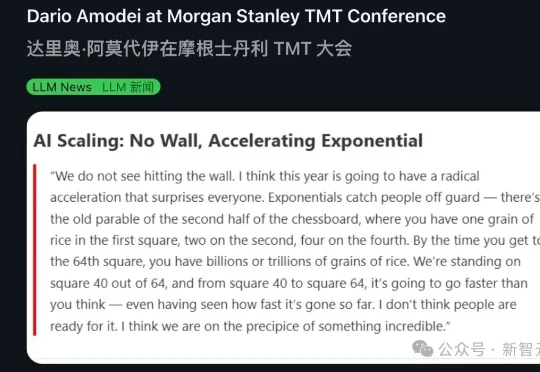
Anthropic CEO Dario Amodei在摩根士丹利会议上扔出一颗深水炸弹:Scaling Law根本没撞墙,2026年将迎来激进加速。他用棋盘稻米寓言做了个精准比喻——我们正站在第40格,前39格的所有震撼加在一起,不过是后24格的零头。这场指数级狂飙,没人准备好。