
与Generalist顶峰相见,30天狂吸30亿,千寻智能做对了什么?
与Generalist顶峰相见,30天狂吸30亿,千寻智能做对了什么?千寻智能又一次把融资节奏拉满。
来自主题: AI资讯
9769 点击 2026-04-07 11:17
 搜索
搜索
千寻智能又一次把融资节奏拉满。
上次 0.83 那条路没了,现在还能怎么便宜开 GPT Plus
OpenAI 加快了迈向下一 AI 阶段的进程。
刚刚,Anthropic年收入首超OpenAI!同时就在今天,一份与谷歌、博通最新合作,将在2027年上线3.5 GW全新TPU集群。这批史诗级的算力,预计从2027年开始陆续上线。
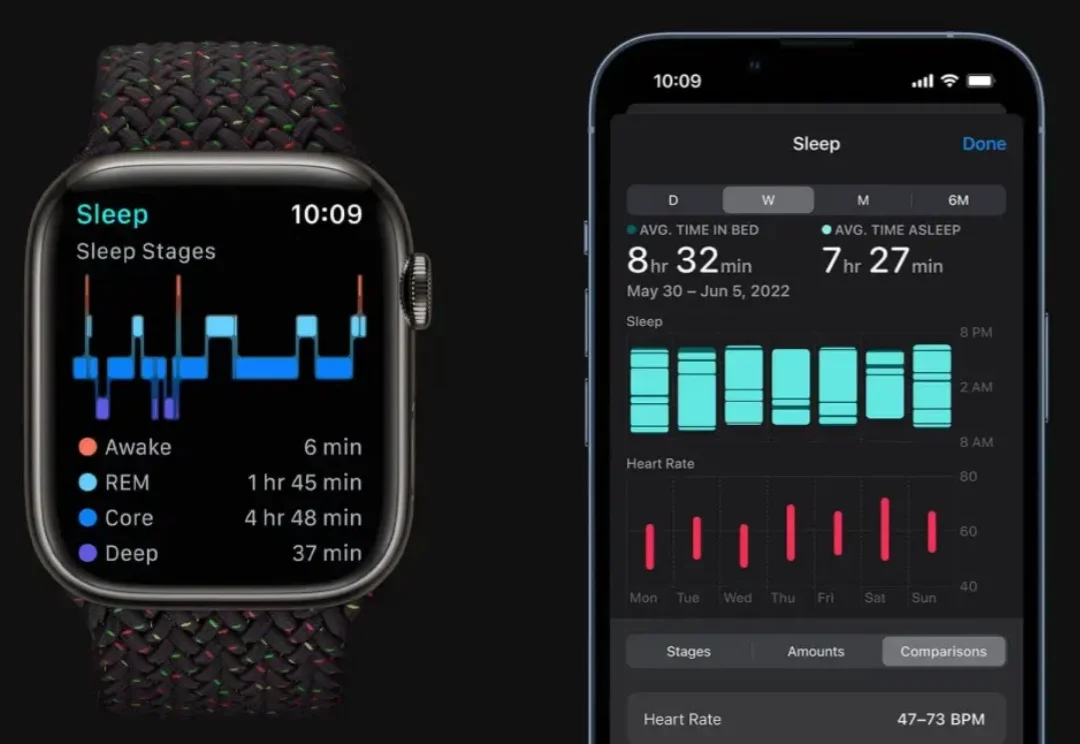
通过一晚上的睡眠,AI 模型就能监控最多 130 种疾病。

许多长期与文字和代码打交道的创作者,应该对 Obsidian 这款软件并不陌生。作为目前全球最具影响力的本地化 Markdown 笔记应用之一,它凭借独树一帜的知识图谱和开源生态,在知名度与用户忠诚度上,已然能与 Notion 分庭抗礼。

雷军和马云在具身智能赛道罕见"握手"。
Google 最新发布的 Gemma-4-31B 基础模型出现了越狱版本,安全限制被完全移除。这个名为"Gemma-4-31B-JANG_4M-CRACK"的模型已经公开发布在 Hugging Face 上,任何人都可以下载使用。

如果你是 Kimi Code 会员,现在就可以去控制台申请抢先体验——据说能提前体验新模型。消息虽非官方,但足以让开发者兴奋。毕竟,Kimi K2.5 接入 Kimi Code 才过去不到两个月。

AI正在把漏洞发现的速度推到一个新量级,Linux内核安全团队从每周2-3份报告,暴涨到每天5-10份,而且几乎全是「真货」。旧时代的安全规则,正在被AI逐条撕碎。