高德重磅发布3D原生城市世界模型ABot-Earth0.5,把地球玩成了《我的世界》!
高德重磅发布3D原生城市世界模型ABot-Earth0.5,把地球玩成了《我的世界》!6月8日,高德重磅发布了全球首个3D原生城市世界模型——ABot-Earth0.5。ABot-Earth0.5的发布不仅宣告着城市级场景3D原生技术的重要突破,更彻底重塑了传统3D建模的生产逻辑与成本结构。
来自主题: AI资讯
9427 点击 2026-06-08 18:59
 搜索
搜索
6月8日,高德重磅发布了全球首个3D原生城市世界模型——ABot-Earth0.5。ABot-Earth0.5的发布不仅宣告着城市级场景3D原生技术的重要突破,更彻底重塑了传统3D建模的生产逻辑与成本结构。

半年,估值实现6倍增长。
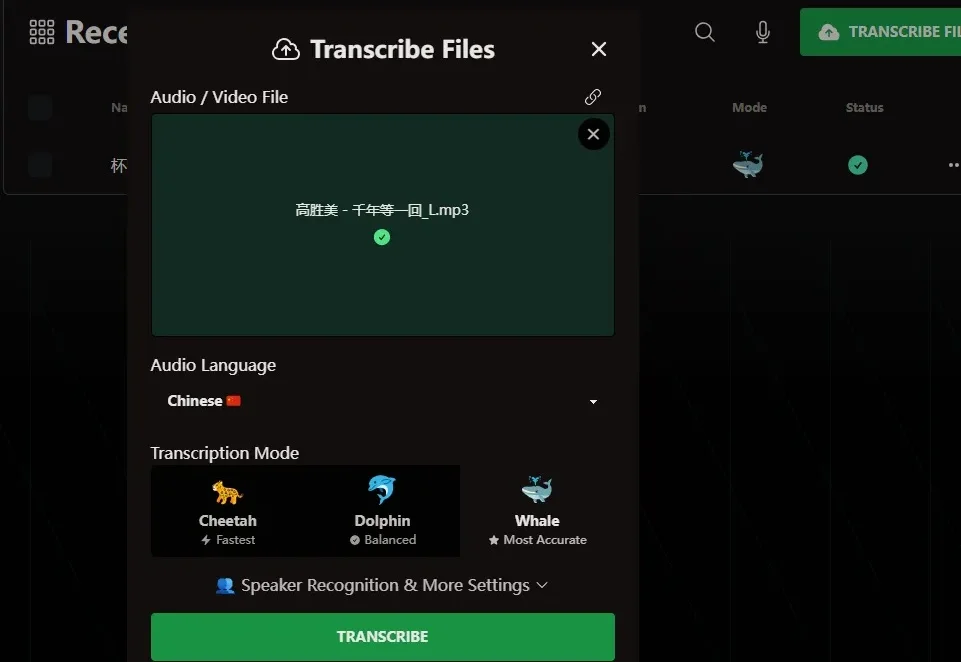
最近看到了一个音频转文字的 AI 工具站:turboscribe.ai。
空间智能与世界模型初创公司知天下(苏州)人工智能科技有限公司(以下简称“知天下”)近日已完成天使轮融资。知天下是一家专注于高斯泼溅(3D Gaussian Splatting,简称3DGS)三维重建与生成技术的AI企业,于 2024 年初推出 3DGS 免费重建与发布服务

35岁的周先生在杭州一家金融互联网企业担任AI大模型质检主管,负责对AI与用户交互生成的答案进行把关。2024年11月19日,他突然收到通知,从部门主管调至普通岗位,月薪也从2.5万元降到1.5万元,他拒绝接受。两个多月后,周先生被单方面解除劳动合同。
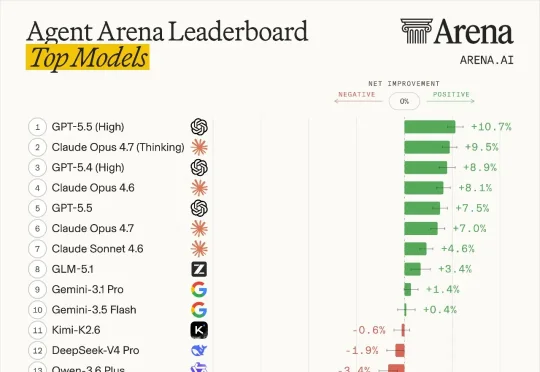
6月4日,Arena.ai发布Agent Arena排行榜,用373,431次真实会话的数据,给18个主流模型的Agent能力排了个座次。先看总榜。Agent Arena的排名依据是“净改进”(Net Improvement),用因果推断方法算出每个模型相对于随机基线的性能提升幅度。正值代表比随机选择更好,负值说明不如随机。

奇点灵智做了一款支持 Vibe Coding 的儿童硬件。 产品叫多奇 AI 小外教机器人,面向 3-8 岁孩子。今年 1 月在京东首发,首发期间产品进入京东榜单 Top 2,目前全平台订单超过 2
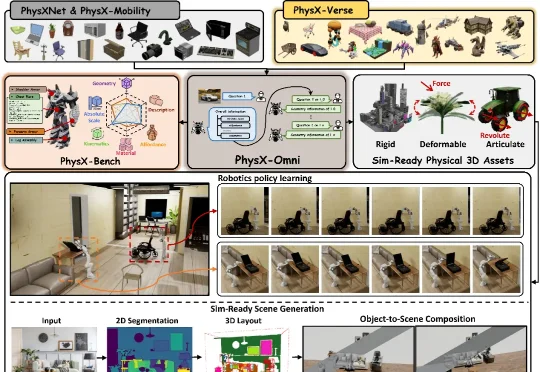
该论文第一作者为曹子昂,研究方向主要聚焦于 3D AIGC、Physical AI 与具身智能。论文主要合作者包括来自南洋理工大学的李海天、姚润茂、洪方舟、陈昭熹,以及大晓机器人的刘英豪和潘亮。通讯作者为南洋理工大学刘子纬教授。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,

奥特曼官宣ChatGPT记忆重大升级!全新Dreaming V3架构正式上线:ChatGPT会在后台「做梦」,首次向数亿免费用户开放。这一次升级,「做梦」功能向十亿人免费开放,Plus和Pro记忆容量直接翻倍。