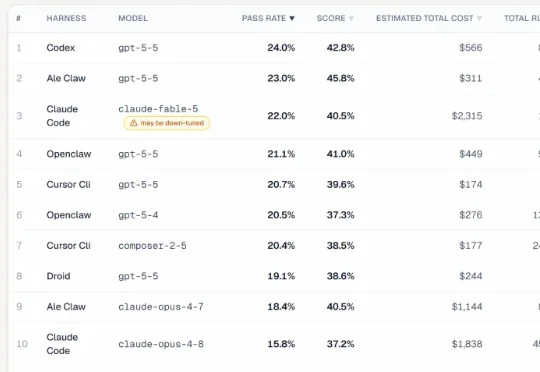
“智能体最后的考试”,Fable 5竟然不敌GPT 5.5
“智能体最后的考试”,Fable 5竟然不敌GPT 5.5刚刚,UC伯克利放出了一场号称“智能体最后的考试”的全新基准测试。它把当今最强的AI Agent们拉到考场上,让它们干真正的活——在Siemens NX里建3D模型、在Unreal Engine里搭游戏场景、在Adobe After Effects里做特效合成。
来自主题: AI技术研报
9107 点击 2026-06-13 10:41
 搜索
搜索
刚刚,UC伯克利放出了一场号称“智能体最后的考试”的全新基准测试。它把当今最强的AI Agent们拉到考场上,让它们干真正的活——在Siemens NX里建3D模型、在Unreal Engine里搭游戏场景、在Adobe After Effects里做特效合成。
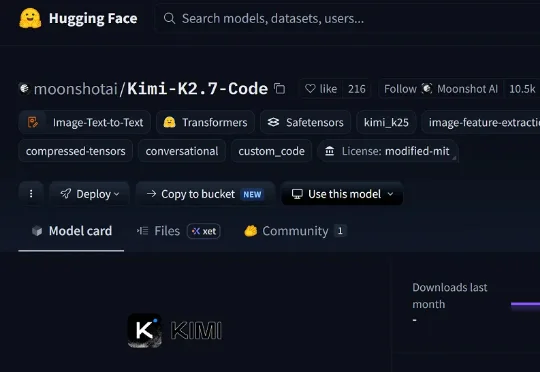
今天,月之暗面发布并开源Kimi K2.7 Code编程模型,参数量达1.1万亿,提供256K上下文窗口。这一模型重点提升了长上下文编程场景的指令遵循能力、长程编程任务的性能表现,并且大幅改善了在长程任务中的过度思考倾向,平均token消耗减少30%。

决策机已推演23万起事件,准确率超90%。

刚刚,Anthropic CEO发布重磅檄文《指数级AI政策》:AI的「指数级爆炸」已无法阻挡,必须强制第三方测试+政府叫停!为此,Anthropic砸出3.5亿真金白银。
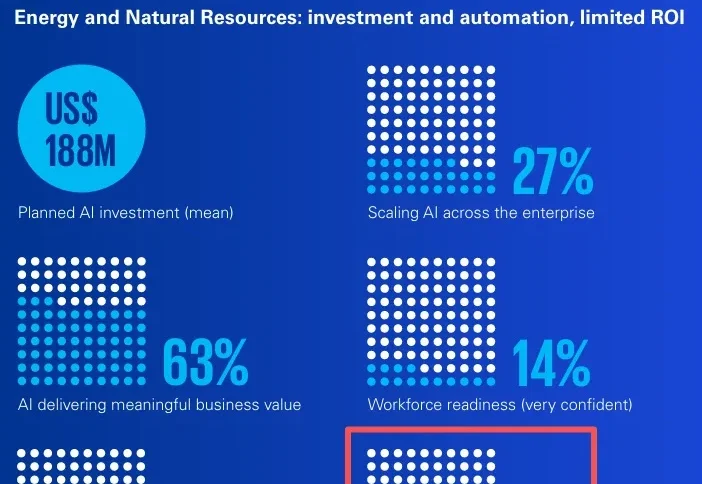
一提到AI的应用和落地,大家就会陷入非共识迷雾。为了拨开营销炒作,我把近期有代表性的几份Enterprise AI调研报告拉通,横跨Menlo Ventures(500+企业AI决策者)、德勤(24个国家,6大行业,3235名高管)、KPMG(20个国家,8大行业,2110名全球高管)、Entelligence(2444家企业)。

多模态长记忆在“看得准、找得到、想得清”三大环节的底层逻辑与工程避坑指南。

根据我长期使用的观察,0.3 倍率说是用 Kiro 逆向出来的 Claude,2.0 倍率说是正经 Claude Max 号池接出来的。听起来后者肯定更靠谱。我一开始也这么想的。毕竟倍率差了快七倍,价格摆在那,总不至于拿假货糊弄人吧。

刚刚,Google 甩出了 Gemini 3.5 Live Translate。这是它最新的语音对语音翻译模型,一句话概括:把「等你说完再翻」的老规矩,直接掀了。Google DeepMind 首席科学家 Jeff Dean 亲自发帖官宣,字里行间透着一股「二十年磨一剑」的底气:

在3D创作这个圈子,一直有个心照不宣的扎心真相: 那就是最难的一步从来不是生成,而是让模型变为可用资产。

最近几个月,海外主流社交平台X、YouTube、Instagram、LinkedIn、Facebook等的头部内容创作者,开始高频地提及同一个名字——AhaCreator 3.0。从科技博主、消费电子达人,到跨境电商品牌主理人,再到拥有百万粉丝的内容创作者,越来越多人在自己的内容中分享使用体验。